# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
每一次技术范式的重大转换,都是旧秩序松动、新物种诞生的窗口期。
大模型的竞争进入 2026 年,行业正在将 AI 视为一场关于参数规模与算力堆砌的无限游戏时,一家成立仅三年多的中国创业公司——智象未来(HiDream.ai),凭借底层架构的创新,在巨头环伺的图像模型领域撕开了一道裂缝。
近日,智象未来(HiDream.ai)全新推出的商用版图像生成模型 HiDream-O1-Image-1.5 再次实现 SOTA,在全球知名独立 AI 模型评测与分析平台 Artificial Analysis 的文生图榜单(Text to Image Leaderboard)上,一举登上中国图像生成模型第一,成为评分仅次于 OpenAI 的中国大模型公司,超越 Google Nano Banana 2(Gemini 3.1 Flash Image Preview)、NVIDIA Cosmos3-Super-Text2Image 和字节跳动的 Seedream 4.0 等国内外大厂的主流图像生成模型。
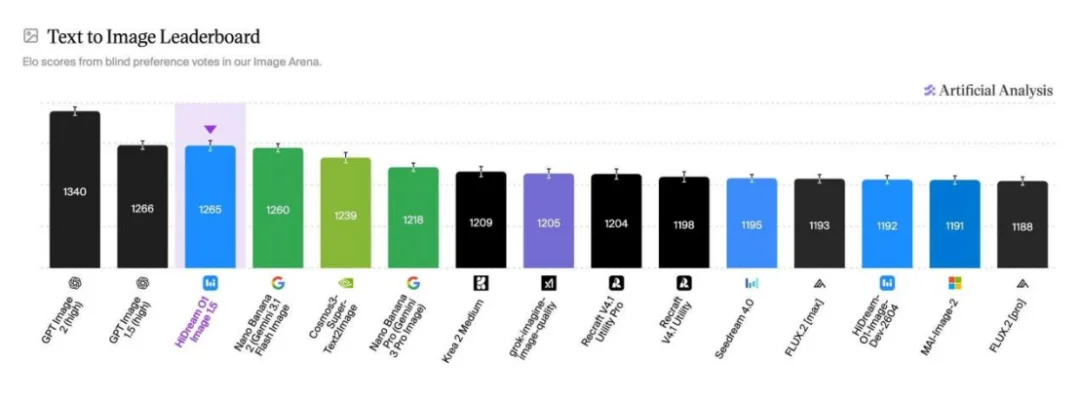
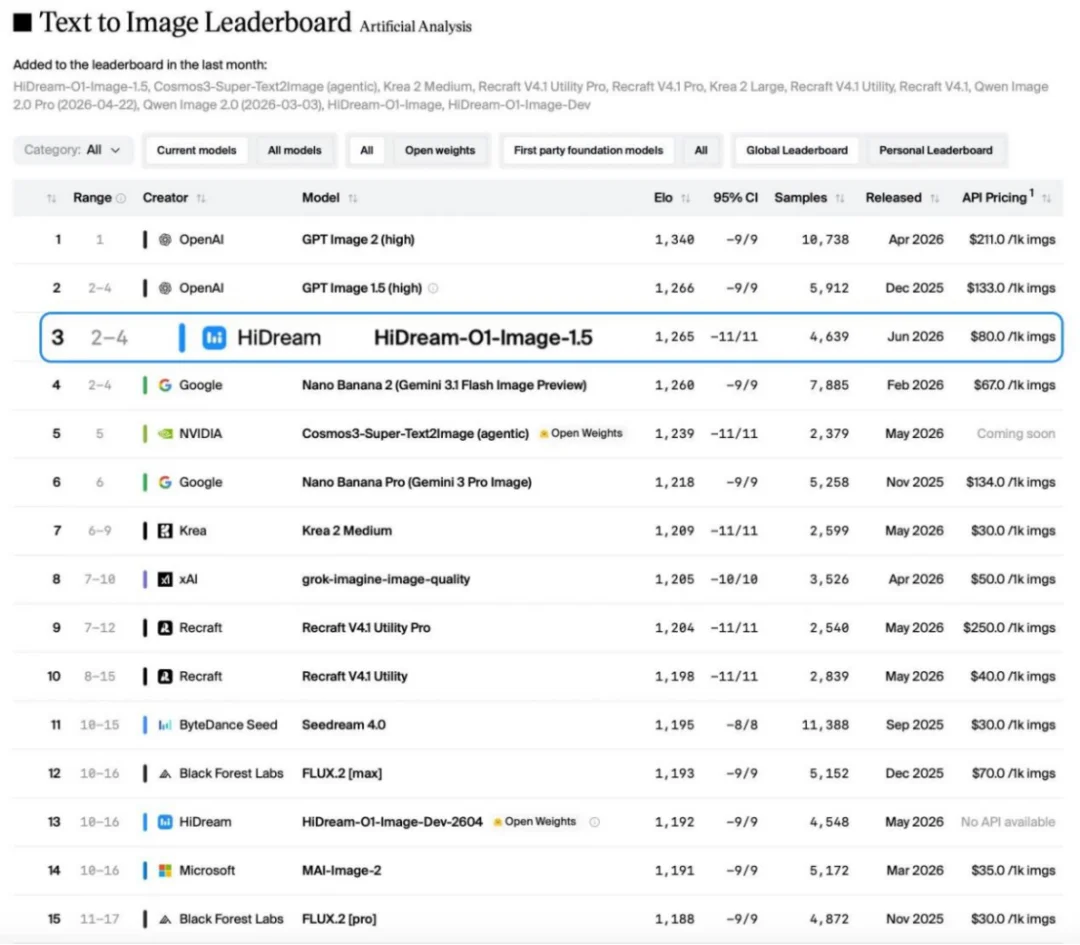
这并非是一次偶发性的技术爆发。仅仅在数周之前,智象未来原生全模态 HiDream-O1 系列的开源模型 HiDream-O1-Image-Dev-2604 刚刚登顶文生图榜单开源模型的全球第一。
半月之内两次问鼎全球,这不禁让人让人感到好奇:一家成立刚满三年的创业公司,凭什么在图像生成的权威榜单中超越谷歌和字节?这是偶然的评测优化,还是硬核实力的比拼?这次评测结果,又折射出了哪些时代的潮向?
Artificial Analysis 的 Text to Image Leaderboard 采用匿名对比、用户投票和 ELO 动态排名机制,尽量减少品牌认知对评测结果的影响,更接近真实用户在开放生成场景中的偏好判断。在这一专业评测体系下,HiDream-O1-Image-1.5 在超过 4000 个样本对比中取得 1265 ELO。HiDream-O1-Image-1.5 的表现不仅体现了模型在图像质量上的竞争力,也反映出其在语义遵循、复杂画面生成、文字渲染和多主体控制等综合能力上的提升。
放眼整个 “赛场”,与智象未来同台竞技的对手不乏一些市值万亿的巨擘:Google 拥有 TPU 集群和全球顶级人才积累,字节跳动拥有庞大的流量入口与应用土壤。在算力、数据与生态禀赋都不占优的背景下,这家初创企业实现超越,核心在于选择了一条截然不同的技术路径。
当前全球主流文生图模型,普遍沿用文本编码器 + VAE(变分自编码器)+DiT(扩散 Transformer) 的模块化架构,行业也长期以增加参数规模、堆砌算力作为主要迭代方向。而智象未来放弃了这条成熟路线,选择了一条更难但更具想象力的路 —— 像素级原生全模态架构 UiT。
传统文生图模型通常采用 “文本编码器 + VAE + DiT / 扩散模型” 的模块化路径,其形态更像一棵不断分叉生长的树:文本有自己的 tokenizer,图像和视频有各自的 encoder /decoder,音频、动作、空间关系也往往沿着不同路径被处理,模块之间需要多次转换信息。在长文本排版、UI 设计、多主体画面、多参考图联动、连续分镜等复杂任务中,信息多次转换容易造成细节丢失、语义偏差与画面结构不稳定,这也是当前多数商用图像模型的普遍痛点。
智象未来 HiDream-O1 系列所采用的原生全模态架构,彻底重构了信息处理逻辑。该架构剔除传统方案中的独立 VAE 与专用文本编码器,将图像像素、文本 Token、视频体素、音频、动作及空间关系等原始信号,统一映射至同一个共享表征空间,通过一套 UiT(像素级统一 Transformer)完成全模态信息的理解、计算与生成。不同于行业常见的 “多模态后期拼接” 方案,这套架构从模型底层实现了各类信号的融合交互,从根源上减少模态转换带来的损耗。
企业技术路线的选择,往往与团队的认知结构和实践经验高度相关。要理解智象未来的技术路线,需要回到这支团队的历史坐标系中。
智象未来核心技术团队专注 AIGC 领域超过 10 年,深度参与三代 AI 模型技术演进,是国内少有的由院士领衔、兼具完整技术路径与产业经验的多模态 AI 团队。早在 2017 年,团队便提出了 TGANs-C,这也是全球最早的视频生成模型论文之一,也曾深度参与全球第二大视频搜索引擎、中国最大自营电商平台图片搜索引擎等大规模系统建设,并将多模态技术进一步落地到物流具身智能、千卡级准实时智能视频推理等高复杂度产业场景。
这意味着,智象未来并非只拥有模型研发经验,而是同时经历过前沿算法、工程系统与真实业务场景的完整闭环。决定发展高度的,是持续深耕底层创新的能力;决定能走多远的,是穿越复杂产业场景的落地经验。
智象未来从不缺乏创新的魄力。
在智象未来的技术体系中,图像被定义为现实世界建模的空间基底。单张图像承载着某一瞬间完整的场景、光影、结构与主体信息,它并非独立的单一能力,而是视频生成、乃至通向原生全模态世界模型的关键入口。基于这一前瞻性判断,企业确定了 “以图像为根基,向视频、全模态延伸” 的发展路线。
纵观行业格局,头部大厂长期以大语言模型为核心搭建多模态体系。文本作为主流认知中介,围绕其构建的技术栈、产品生态与商业壁垒已经根深蒂固,也让大厂难以彻底推翻现有架构重新布局。而成立时间较短的智象未来没有历史技术包袱,团队提出全新理念:在多模态发展的新阶段,信号本身即可作为认知载体,文本不再是必需的中间媒介。
当前全球多模态技术路线尚未完全收敛,行业仍处于路线竞争的窗口期。当巨头受制于成熟技术体系难以全面革新时,初创企业凭借轻量化组织、灵活的试错空间,依托底层架构创新,反而有机会实现代际层面的技术跨越。
智象未来的突围,可以解构为三个层面:
第一,在架构层面寻找代际优势,用极限资源做成核心业务。
智象未来没有卷入 DiT 主流赛道的算力与参数竞赛,而是全力打磨自研的 UiT 原生全模态架构。这条路线前期研发投入大、试错成本高,但一旦跑通,便有望形成结构性的代际优势。据团队披露,在相近的训练数据和计算资源下,其 8B 参数模型已可实现与行业百亿级传统模型对标甚至超越的综合表现,体现出更高的参数效率。
这种对底层架构的极致追求,并未让智象未来陷入 “为创新而创新” 的孤芳自赏。相反,在工程化落地层面智象未来保持着高度务实的态度。以视频生成为例,团队采用 “先图像、后视频” 的思路:先用图像模型完成技术验证与快速试错,再将成熟能力迁移至视频领域。这一策略将训练成本压缩至行业平均的五分之一到十分之一 —— 正是这种用极限资源做成核心业务的生存智慧,让一家创业公司在巨头林立的环境中跑出了自己的节奏。
第二,将模型与垂直场景深度耦合,构建别人难以复制的护城河。
智象未来不只是一家模型公司,正如此前所说,商业化是公司诞生之日起就极度关注的问题。经过多年的探索,目前已经形成 “1+1+3” 的布局:一个 HiDream 模型底座,一个对外输出能力的平台,三个智能体应用场景分别是面向专业影视团队的影视创作协作智能体「帧赞」,面向电商(特别是跨境商家)批量营销内容生产的 HiBurst,以及面向专业社媒创作工作者的 vivago,实现了模型与产品的最强耦合。
商业营销智能体 HiBurst 已进入 TikTok 官方服务商 Top 5,年产电商营销视频超百万条,覆盖 GMV 超亿元;AI影视创作与协作智能体「帧赞」打通“创意—分镜—成片”全流程,累计制作短漫剧超 5000 分钟,并接入长江电影集团、慈文传媒等影视机构;社媒创作智能体 vivago 近期登上 Product Hunt 日榜第一,覆盖全球 100 多个国家和地区,服务超 4000 万用户。
智象未来的专业影视视频生成业务,目前已能稳定 one-shot 直出 1-3 分钟的视频,成功率超过 70%。在今天的大抽卡时代,这个数字令人印象深刻。
第三,保持极致的战略定力与认知升级。
当行业绝大部分玩家还在传统架构上发力时,智象未来敢于 “推倒重来”,押注原生全模态。这种 “身份清零” 的勇气,源自创始团队的两个坚持:一面是战略定力,一面是认知升级。他们没有被算力竞赛和参数内卷带偏,始终笃信 “全模态融合才是通往世界模型的必经之路”;同时又在每一次技术迭代中重新审视路径、刷新认知。这种稳得住又跟得上的能力,使得公司始终拥有持续创新的强大动能。
这种持续创新的能力,正逐渐转化为一批可见的战略性成果。HiDream1.5 问鼎全球权威榜单,即是生动注脚。
HiDream-O1-Image-1.5 展现出远超 “好看图片” 范畴的全能图像生成能力。它不再满足于输出一张精美的静态画面,而是能够理解复杂排版、渲染多语言文字、把控连续分镜逻辑。
同时,HiDream1.5 的商用模型定位,标志着原生全模态进入生产验证阶段,能够解决实际生产中的各类难点。过往不少 AI 图像模型往往无法用于商业场景,尤其是在复杂排版、多主体控制、长文本渲染等场景中,存在短板,而 HiDream1.5 在这个方面实现了重大突破。
HiDream1.5 面向广告营销、品牌设计、电商视觉、游戏内容、影视分镜、IP 创作等更高要求的商业场景,全面展示了强化的图像质量、文字渲染、复杂排版、多主体一致性和视觉叙事能力。
人像摄影场景
模型可输出摄影级画质,适配魔幻光影、人物特写、双人互动等多种风格。在皮肤质感、服饰纹理、肢体互动、环境虚化等细节上表现自然,面对广角、低机位、室内暖光等复杂构图,也能保证人物比例、空间透视与画面叙事的协调性,可满足商业人像、品牌视觉、影视分镜等专业需求。

自然风光场景
针对雪山湖泊、沙漠、洞穴等大场景与复杂地貌,模型能够精准把控空间层次、光影变化与环境氛围,画面具备电影质感与丰富细节,适配旅游宣传、影视概念图、游戏场景设计、品牌视觉传播等场景。

电商海报场景
可快速匹配不同品类商品的视觉风格,将产品、场景、装饰元素与营销文案自然融合。面对中英文混排、多层级卖点、复杂版式等需求,依旧能保证文字可读性与画面完整性,有效提升电商上新、广告物料、社交种草内容的制作效率。

多宫格与分镜设计
模型具备连续叙事理解能力,在绘本、故事脚本、广告分镜、短视频脚本等多画面创作中,可生成逻辑连贯的内容,同时保持角色、场景、视觉风格统一,对宫格布局、标题、编号等元素也能合理排布,支撑漫画、影视、教育类内容的视觉化创作。

HiDream-O1-Image-1.5 的出色表现,展现出 UiT 路线不仅带来了单图生成效果的跃升,更在多图一致性、分镜生成、视频首帧乃至长视频生成等复杂任务中展现出更稳定的底层能力。
站在 2026 年的关键节点展望,AI 图像生成的竞争逻辑正在悄然重构。它不再仅仅是参数规模的数字游戏,也不止于 “画面好不好看” 的审美判断 —— 而是进入了一个由架构能力、生产效率与工作流价值共同决定的新阶段。
当然,这远非终局。当前,全球多模态技术路线尚未收敛,窗口期仍在。但无论如何,这场竞争已经释放了一个清晰的信号:在 AI 的长期探索中,底层创新的勇气与落地能力正在逐步超越单纯的规模,成为更稀缺、更珍贵的变量。
不同体量、不同路线的企业同台竞技,终将推动整个行业向更实用、更高效、更贴合产业需求的方向演进。我们正站在这场范式革命的序幕 —— 而非高潮。在这场波澜壮阔的演进中,每一家企业都在以自己的方式寻找未来的坐标。而智象未来,已然先行一步。
通过以下链接体验:
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
