# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Stability AI又有新动作了!这次给我们端上来的是全新的3D生成模型Stable Video 3D(SV3D)。
只需一张图,SV3D就能生成对应的3D模型,相比于自家之前发布的Stable Zero123,模型质量更高,功能更强!

与之前基于Stable Diffusion1.5的Stable Zero123不同,SV3D以Stable Video Diffusion为基础,充分利用了视频模型的功能性。
与图像扩散模型相比,视频扩散模型在生成输出的泛化和视图一致性方面存在明显优势。

从上面的演示我们可以看到,SV3D的生成效果大大超越了当前的同类模型,视频模型的理解能力确实不一般,篮球、玉米、钟表都做的相当还原。
——不过还是需要说一句,开庭时请带上你的SV3D。

项目地址:https://sv3d.github.io/
模型下载:https://huggingface.co/stabilityai/sv3d

此外,Stability还给出了两个进阶版本:
SV3D_u,基于单个图像输入生成轨道视频,无需相机调节;
SV3D_p,扩展了SVD3_u的功能,既可以容纳单个图像,也可以容纳轨道视图,从而允许沿着指定的摄像机路径创建3D视频。
目前,Stable Video 3D可以通过Stability AI会员资格用于商业目的。
对于非商业用途,可以在Hugging Face上下载模型权重。
单图像3D对象重建是计算机视觉中长期存在的问题,且在游戏设计、AR/VR、电子商务、机器人等领域有着广泛的应用。
这是一个非常具有挑战性的问题,因为它需要将2D像素提升到3D空间,同时还要推理3D中物体看不见的部分。
对此,一个典型的策略是使用基于图像的2D生成模型(比如Imagen、Stable Diffusion等)为给定对象的不可见新视图提供3D优化损失函数。
还有的方法是采用2D的图像生成模型,从单个图像执行新视图合成(novel view synthesi,NVS)。
从概念上讲,这些方法都是模仿了典型的基于摄影测量的3D对象捕获管道,即首先拍摄对象的多视图图像,然后进行3D优化。

这种方法的一个关键问题是,底层生成模型中缺乏多视图一致性,导致新视图不一致。
本文的工作以视频扩散模型(Stable Video Diffusion,SVD)为基础,来生成具有显式相机姿态条件的给定对象的多个新视图,具有出色的多视图一致性。

另外,由于SVD是在比大规模3D数据更容易获得的大规模图像和视频数据上训练的,所以具有更强的泛化能力。
SV3D的工作原理如下图所示,首先根据输入的单个图像,生成一致的多视图图像。
然后使用生成的视图优化3D表示,从而生成高质量的3D网格。
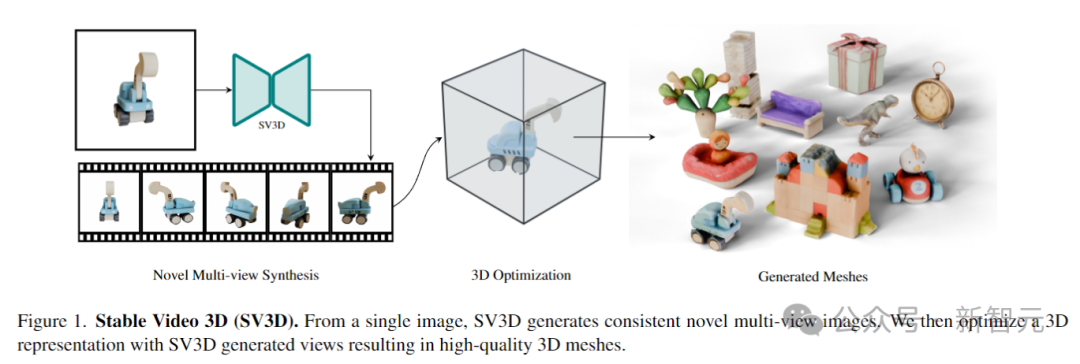
通过调整视频扩散模型Stable Video Diffusion,并添加摄像机路径调节,SV3D能够生成对象的多视图视频。
此外,研究人员还提出了改进的3D优化,利用SV3D的强大功能来生成围绕物体的任意轨道。
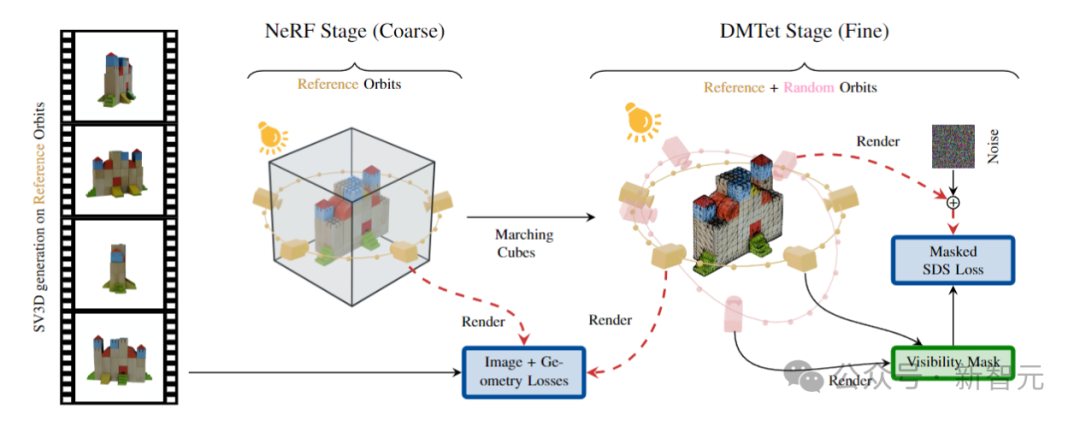
通过进一步实施解纠缠照明优化(disentangled illumination optimization)、以及新的掩蔽分数蒸馏采样损失功能(masked score distillation sampling loss function),SV3D能够从单个图像输入可靠地输出高质量的3D网格。
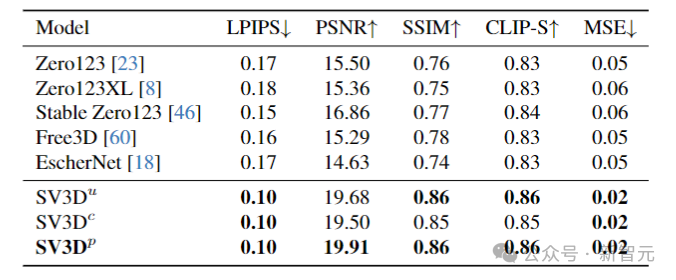
研究人员在具有2D和3D指标的多个数据集上进行了大量实验,结果表明:SV3D在NVS和3D重建方面到达了目前最好的性能。

SV3D的主要思想是重新利用视频扩散模型中的时间一致性,以实现对象的空间3D一致性。
具体来说,研究人员对SVD进行微调,以在单视图图像的基础上围绕3D物体生成轨道视频。该轨道视频不必处于相同的高度,也不必处于规则间隔的方位角。
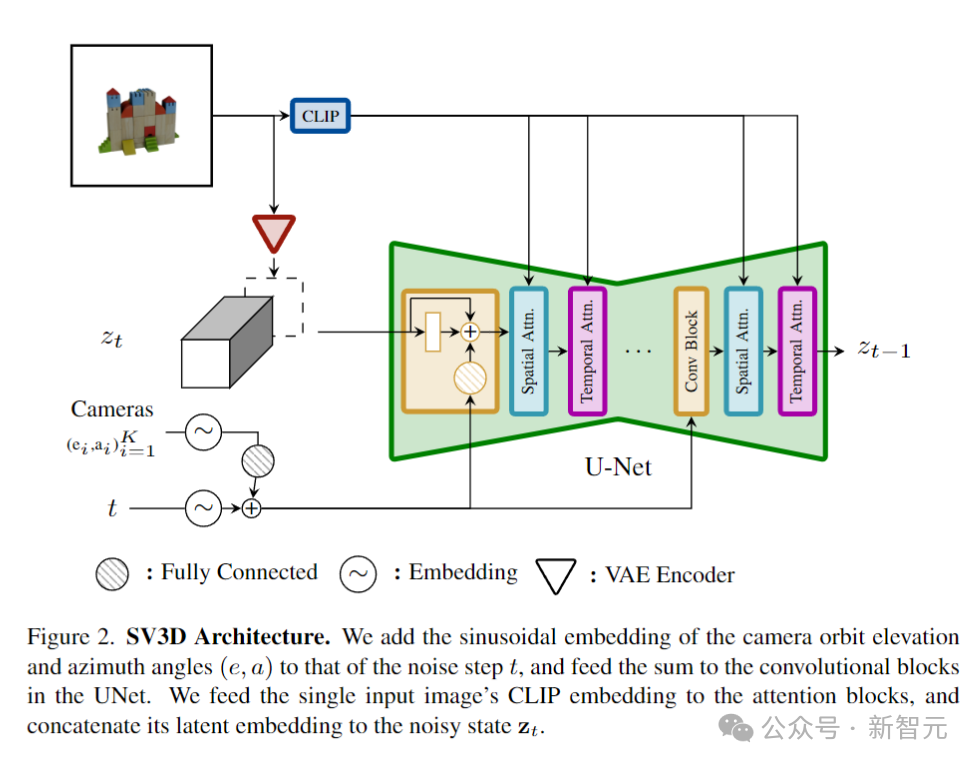
如上图所示,SV3D的架构建立在SVD的基础上,SVD由一个具有多个层的UNet组成,每层包含一个带有Conv3D层的残差块序列,以及两个带有注意力层的Transformer块(空间和时间)。
作者对于SVD做了如下调整:
1. 删除了fps id和motion bucket id的矢量条件,因为它们与SV3D无关;
2. 在嵌入到SVD的VAE编码器的潜空间之后,将条件图像根据噪声潜态输入连接到UNet;
3. 将条件图像的CLIPembedding矩阵作为键和值提供给每个Transformer块的交叉注意力层。
4. 相机轨迹与扩散噪声时间步长一起输入残差块。
动态轨道
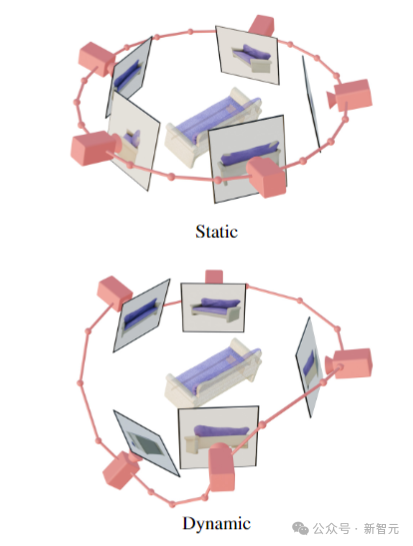
如上图所示,研究人员设计了静态和动态轨道来研究相机姿态调节的效果。
在静态轨道上,相机以相同的仰角和规则间隔的方位角围绕物体旋转。
静态轨道的缺点是,由于调节仰角,可能无法获得有关物体顶部或底部的任何信息。
而在动态轨道中,方位角可以不规则地间隔,并且仰角可以因视图而异。
为了建立一个动态轨道,研究人员对静态轨道进行采样,在方位角上添加小的随机噪声,并在高度方向上添加具有不同频率的正弦曲线的随机加权组合。
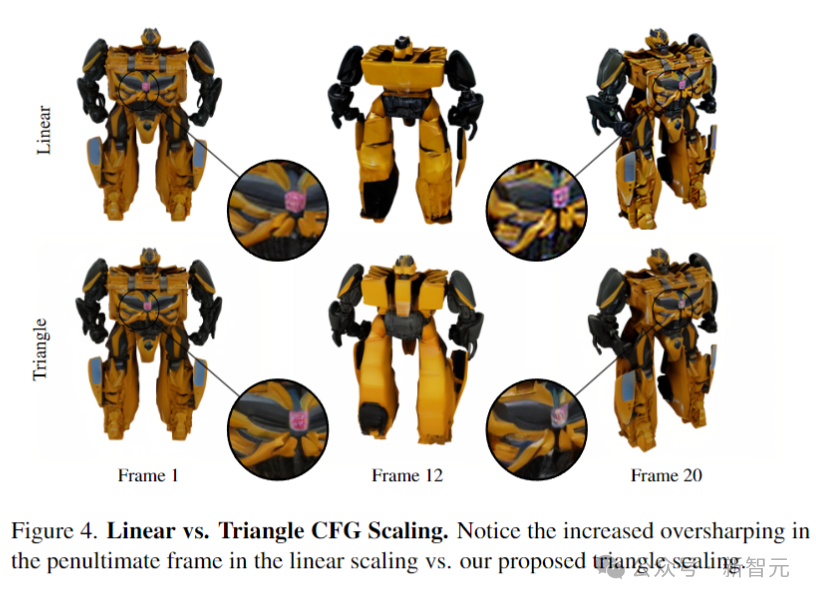
还有一个问题是,SVD在生成的帧中使用线性递增的无分类器引导(CFG)比例,这种缩放会导致生成轨道中的最后几帧过度锐化,如上图第20帧所示。
作者建议在推理过程中使用三角形CFG缩放(Triangular CFG Scalin),从上图可以看出,使用三角形CFG缩放在后视图(第12帧)中产生了更多细节。
作者训练了三个从SVD微调的图像到3D视频模型。
首先是一个无姿态的模型SV3D,该模型仅以单视图图像为条件,即可生成围绕物体的静态轨道视频。请注意,与SVD-MV不同,这里没有为无姿态模型提供仰角,因为作者发现模型能够从条件图像中推断出它。
第二个模型是姿态条件的SV3D_u,它以输入图像以及轨道上的相机仰角和方位角序列为条件,在动态轨道上进行训练。
通过在训练过程中逐渐增加任务难度,产生了第三个模型SV3D_p,首先微调SVD以无条件地产生静态轨道,然后在具有相机姿态条件下的动态轨道上进行调整。

研究人员使用Objaverse数据集训练了SV3D,该数据集包含涵盖广泛多样性的合成3D对象。对于每个对象,在576×576分辨率、33.8度视野的随机颜色背景上环绕渲染21帧。
所有三个模型总共训练了105k次迭代,批量大小为64。总共使用了8个80GB A100 GPU(4个节点)训练了6天 。
最后,我们直观地看一下几种3D生成模型的效果比较:

本文来源于公众号新智元,作者alan



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
