# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
近年来的探针分析表明,即便模型最终输出错误,其隐藏状态中往往仍保留着正确答案。这意味着,问题可能并不只是模型 “没有算出来”,也可能是正确信息未被最终输出。
为解释这一现象,来自南京大学的研究团队从机制可解释性(Mechanistic Interpretability)的角度出发,系统研究了 LLM 在多操作数加法中的内部表征结构,发现其算术状态呈现出高度结构化的几何流形。
围绕这一发现,团队提出了两个核心概念:等本位和轨迹(Iso-Raw-Sum Trajectory, IRST)与噪声量化模型(Noisy Quantization Model)。前者揭示相同本位和的算术状态如何沿连续轨迹排列,后者解释为什么模型内部已经包含正确信息,却仍可能在最终输出阶段弄错。
该论文已被机器学习顶级会议 ICML 2026 接收。

如今大语言模型已经在数学领域取得了显著进展。在 2025 年,Google 和 OpenAI 相继宣布其模型取得了 IMO 金牌,到了今年,LLM 已经开始产出真正的,从未有人发现过的新数学结果。
但一个看似反常的现象始终存在:这些模型虽然能解决复杂题目,却仍然会在最基础的算术运算上犯错。
已有探针分析(probing)研究发现,轻量探针可以从模型残差流(residual stream)中读出多种算术信号:不仅能检测模型是否出错,甚至能在模型最终答案错误时解码出正确答案。
这意味着,模型内部其实已经编码了正确的信息,但这些信息并没有顺利转化为最终输出。
这正是本文试图回答的问题:大语言模型在做加法时,内部到底形成了怎样的几何结构?为什么正确答案和错误输出可以同时存在于同一个隐藏状态中?
本文的主实验选择了一个结构清晰、对模型具有挑战性的任务:让 Qwen3-4B 算 3 个 10 位整数相加,共 10000 道题目。模型需要以自回归方式对每道题逐位生成最终答案,研究者则在每一个生成位置提取残差流中的隐藏状态向量。
随后,作者训练轻量探针(probes)去解码多种算术变量,包括:
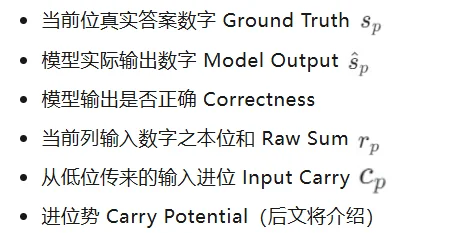
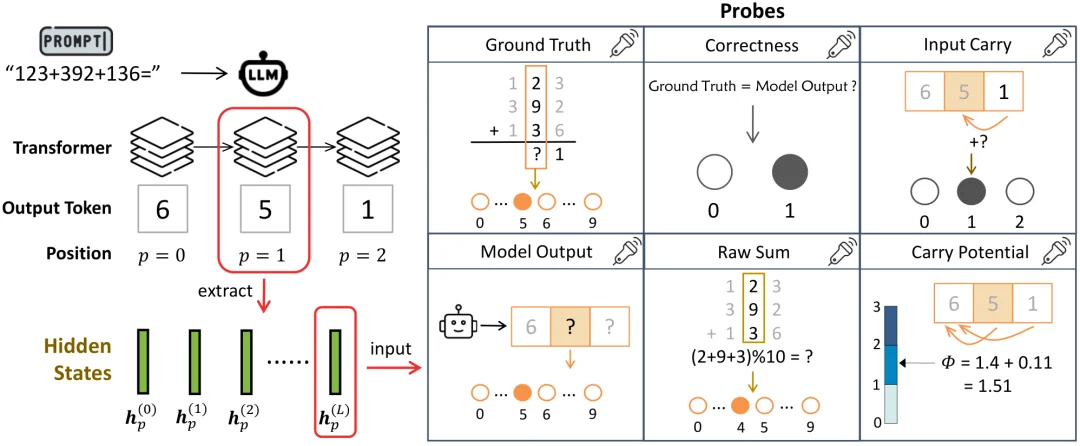
图2 - LLM加法任务的隐藏状态提取与探针实验
实验发现,同一个隐藏状态中确实可以同时解码出这些不同信号。论文将这一现象称为探针多功能性 (Probe Versatility)。
但探针本身只能告诉我们 “信息存在”,却不能解释 “错误如何发生”。如果正确答案和错误输出都能被读出,那么它们在模型内部表征的高维空间中究竟是怎样共存的?
为了回答以上问题,作者使用 UMAP 对最终层隐藏状态进行降维可视化,并将数字 token 的 unembedding 向量作为 0–9 的数字锚点(Anchor)。结果显示,模型内部的算术状态并不是杂乱地分布在空间中,而是形成了非常清晰的、类似 DNA 双螺旋的层级几何结构。
首先,在宏观层面,隐藏状态围绕 0–9 十个数字锚点形成不同的数字盆地(digit basins):如果一个表示点落在数字 6 的盆地附近,模型就更倾向于输出 6。如下图所示。
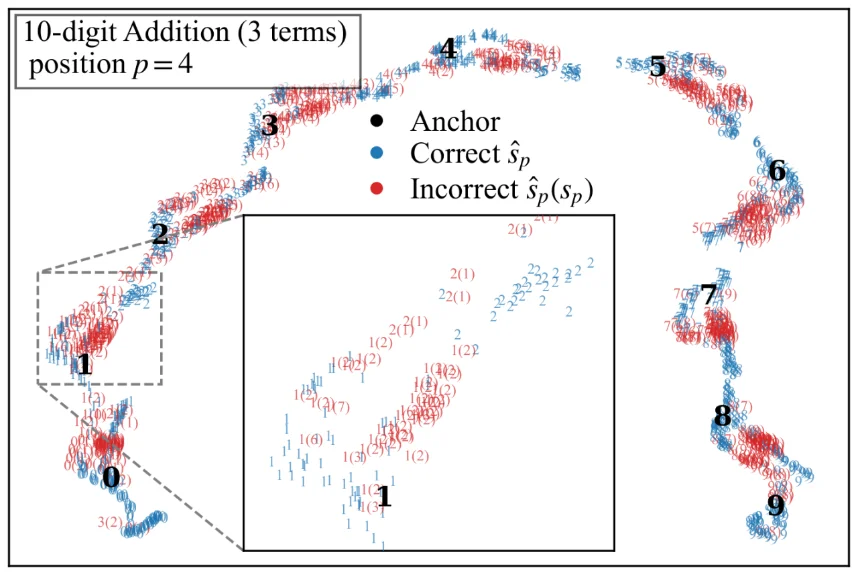
图3 - UMAP降维可视化,展示宏观结构
其次,在微观层面,在每个数字盆地内部,样本又会按照输入进位状态进一步分层。同样是输出数字 1,模型内部会区分 “没有进位得到的 1”“进位 1 得到的 1”“进位 2 得到的 1”。因此,模型不仅知道最终数字,也在内部保留了进位来源。如下图所示。
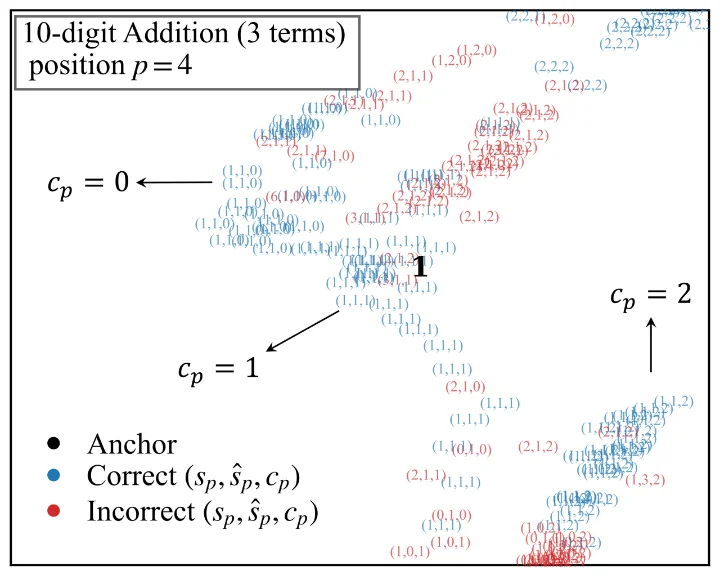
图4 - UMAP图的局部放大,展示微观结构
更关键的是,作者发现一些样本会沿着连续线状结构跨越相邻数字盆地。基于这一现象,论文提出了核心概念:等本位和轨迹(Iso-Raw-Sum Trajectory,IRST)。它指的是一组本位和相同、但进位状态不同的内部表征状态。
例如,在某一列加法中,如果输入数字的本位和固定为 1,那么:
从离散算术上看,这是三个不同输出;但从几何空间上看,它们是沿着同一条连续轨迹排列。这条轨迹就像一根线,穿过数字 1、2、3 对应的盆地。如下图。
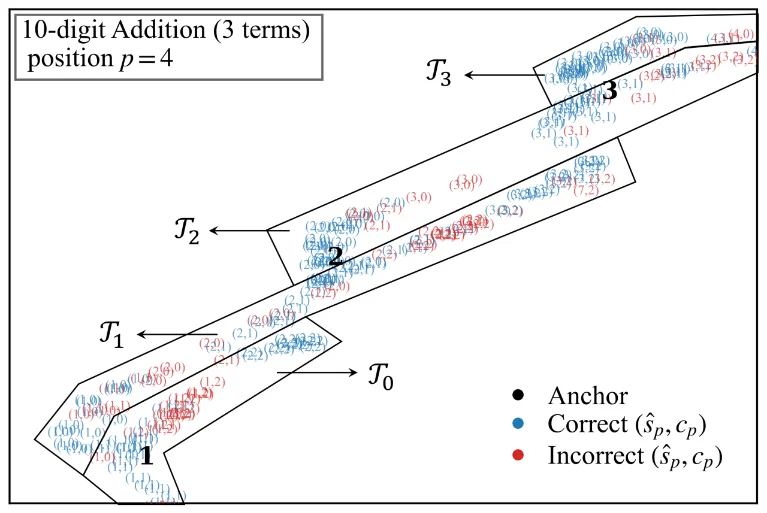
图5 - UMAP图的局部放大,展示四条IRST示例
如果把大模型内部的算术表示想象成一张地形图,那么不同数字对应不同的语义盆地;相同本位和的样本沿着同一条轨迹分布;输入进位的变化推动表示在这条轨迹上移动;最终输出的离散数字,则取决于表示最终落入哪个数字盆地。
因此,大模型的加法表征既不是纯粹离散的,也不是完全连续的,而是由数字盆地、进位纤维和等本位和轨迹共同组成的层级几何流形。
那既然模型内部存在这样有序的几何结构,错误到底是如何产生的?
本文给出的答案是:错误往往发生在连续表征被量化成离散进位或离散数字的边界附近。
为此,论文提出了第二个核心概念:噪声量化模型(Noisy Quantization Model)。

在这一框架下,模型犯错并不是因为内部状态完全混乱,而是因为它已经走在一条正确的 IRST 上,却在接近量化边界时受到了噪声影响。
论文把这种错误称为几何滑移(geometric slippage):隐藏状态沿着 IRST 发生轻微偏移,跨过了相邻数字盆地之间的边界,最终滑入了错误数字对应的区域。
论文针对性地做了验证实验,计算了错误率随进位势的变化曲线,实验结果很好地支持了这一点(如下图)。
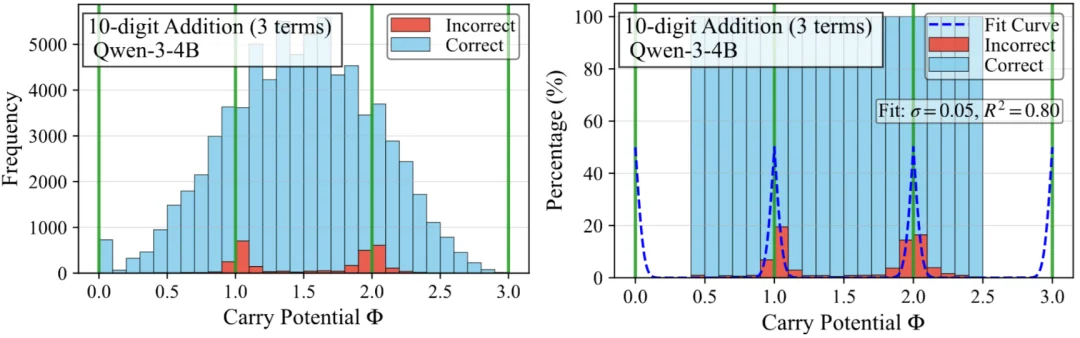
图6 - 噪声量化模型验证实验结果
为了进一步利用这些内部信号,论文还设计了一种推理时纠错方法:双流一致性检查。
这个方法从同一个最终层隐藏状态中解码两类信号:一类是局部信号,即当前列的本位和 Raw Sum;另一类是全局信号,即由右侧上下文累积而来的连续进位势 Carry Potential。
如果模型当前输出的数字与这两类内部信号在算术上自洽,就保留原输出;如果不自洽,就将 Raw Sum 与量化后的 Carry Potential 重新组合,得到一个新的候选输出。
实验结果显示,双流方法取得了最高的 token 正确率,优于原始输出以及若干基线方法(如下表)。
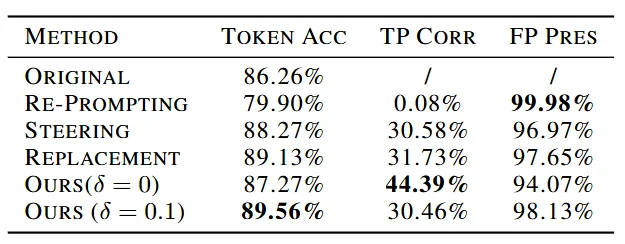
图7 - 推理时纠错方法性能对比
这一结果的意义不在于提升了多少准确率,而是它能进一步证明,模型在输出错误时,内部仍然保留着可恢复的正确算术成分。错误发生的位置,往往是在连续内部表征通向最终离散 token 的最后一步。
总结来看,这篇论文将 LLM 中的算术过程重新刻画为一个几何问题。
虽然探针方法在学术领域已司空见惯,但本文进一步回答了更关键的问题:探针为什么能读出这些信号?探针读的到底是什么?本文将探针的理解从 “信息可提取性” 推进到了 “几何可分性”。
本文的发现进一步证明,大模型的许多错误并非源于内部完全没有正确答案,而是正确的信息并未被很好地利用。
未来提升 LLM 可靠性,关键不仅是增强推理能力,也在于稳定连续神经表征到离散符号输出之间的映射。同时,隐藏状态中已经包含大量类似元认知的自我监测信号,如何让模型自身更好地利用这些信号,将是值得深入探索的方向。
文章来自于"机器之心",作者 "文流渊、朱洵、黄栎浩"。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
