# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自动驾驶正在重演DeepSeek R1的“范式革命”。
一年前,R1横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模——后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
自动驾驶系统已经在海量驾驶数据上完成了预训练,但距离真正的Physical AGI,仍有一道鸿沟:模型知道”该怎么开”,却不知道”为什么这样开更好”。真正的进化,需要闭环、需要反馈、需要在与世界的交互中不断修正。
香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,发表的最新论文World Engine: Towards the Era of Post-Training for Autonomous Driving给出了系统回答。

现代端到端自动驾驶系统已经能够处理大量常规场景。问题在于,真正决定安全边界的,往往不是日常巡航,而是极少出现但后果严重的长尾事件。
这些场景在真实驾驶数据中天然稀缺。车队规模越大,普通场景数据增长越快,但真正有价值的高风险样本仍然难以高密度覆盖。
World Engine将这个问题视为自动驾驶中的结构性矛盾:
最需要学习的安全关键行为,恰恰来自最稀缺的数据。
与大语言模型的发展类似,LLM不是只靠更大规模预训练解决推理问题,而是通过合成推理链、post-training 等方式,在高价值稀疏区域继续对齐能力。
因此,自动驾驶不能只被动等待真实世界“碰巧”采到危险场景,而要主动发现失败模式,合成安全关键交互,并在高保真世界中进行后训练。
如果只看流程,World Engine似乎并不复杂:先训练一个基础驾驶模型,再找到失败场景,重建成仿真世界,生成更多交互,最后做强化学习后训练。
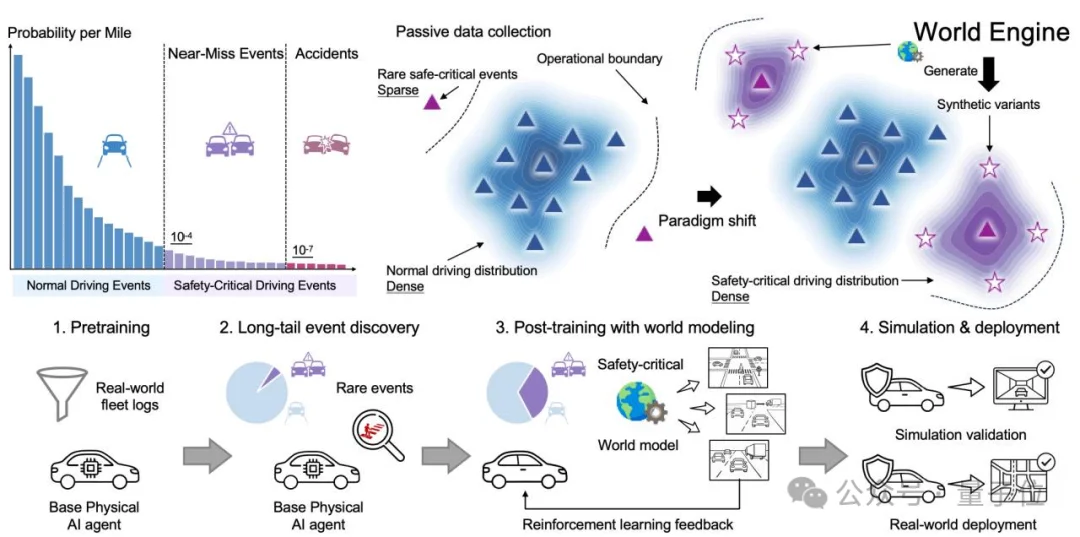
但这篇论文真正有价值的地方,不在于这四个步骤本身,而在于它把自动驾驶post-training中三个最难的问题串成了一个闭环:
学什么?怎么找到真正值得post-training的失败样本,而不是盲目合成corner case?
在哪里学?怎么把一次真实失败变成可闭环交互、可重新采样的世界,而不是日志回放?
怎么学?怎么让策略在长尾场景变强,同时不忘掉普通驾驶能力?
换句话说,World Engine 并不是简单把“仿真器 + 场景生成 + 强化学习”串起来,而是在回答一个更底层的问题:当一个自动驾驶基础模型已经具备较强常规驾驶能力后,如何系统性地找到它的安全边界、把边界附近的真实失败转化为可学习经验,并用受约束的方式更新策略。
理解World Engine,不能从“它有几个模块”开始,而要从这三个问题开始:失败样本从哪里来,交互世界如何被重建,策略又如何被安全地后训练。
World Engine的技术实现主要由三部分组成:SimEngine、Behaviour World Model和Reinforcement Post-training。
这三部分共同服务于一个目标:将真实驾驶日志中的长尾场景转化为可闭环交互的训练环境,并利用这些交互经验对端到端驾驶模型进行后训练。
SimEngine的作用,是把真实世界中的驾驶日志,转化为一个既能被重新渲染、又能被交互控制的仿真世界。
这一过程可以分为两个部分:场景重建和可控渲染。
在场景重建阶段,World Engine基于3DGS来恢复真实驾驶场景。
为了提升新视角渲染的质量,World Engine在重建过程中加入了深度和法向监督,使几何结构更加稳定。
另一方面,真实车辆采集的数据往往存在曝光和颜色差异:不同时间、不同相机之间的亮度和色彩并不完全一致。
针对这一问题,系统先通过LiDAR-guided exposure alignment对全局亮度进行校正,再使用per-camera affine color transform吸收不同相机之间残余的颜色偏差,从而让多视角重建结果更加一致。
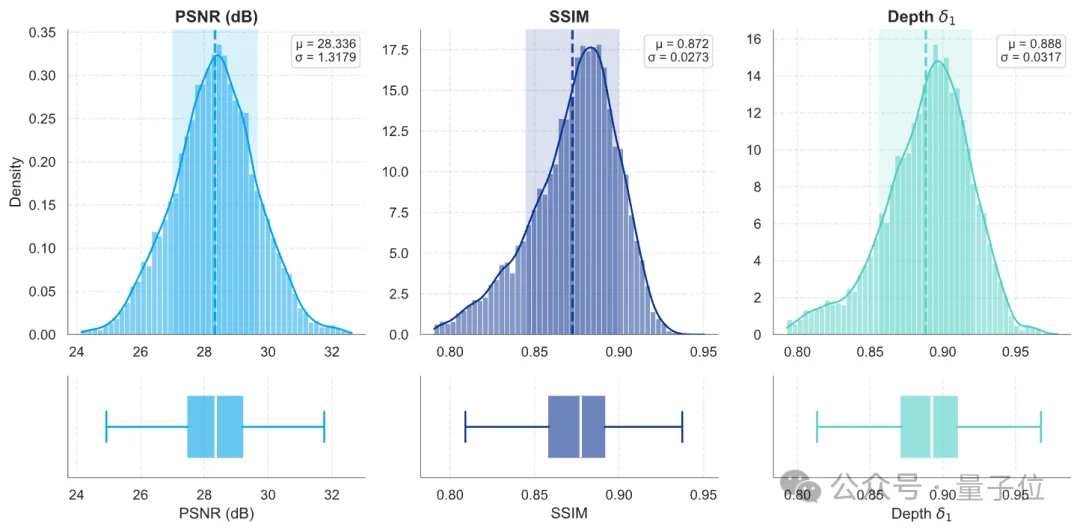
完成重建后,SimEngine就进入可控渲染阶段。给定新的ego pose、传感器内外参,以及其他非ego车辆的位置和朝向,系统可以实时渲染出对应的传感器观测。
得益于3DGS高效的rasterization机制,World Engine不仅能够生成高质量图像,还能支持实时渲染。这一点非常关键,因为它使SimEngine不再只是一个离线可视化工具,而是可以真正服务于闭环仿真和在线数据生成。

如果说SimEngine负责把真实驾驶场景“重建出来”,那么Behaviour World Model负责让这个世界“继续演化”。它的重点并不只是预测周围车辆怎么走,而是围绕已有失败案例,泛化生成更多相似但不完全相同的难例场景。
在闭环仿真中,ego车辆一旦做出不同决策,周围交通参与者也应该产生相应变化。
简单的日志回放只能复现一次失败,而Behaviour World Model则可以在保留道路结构、历史轨迹和关键交互关系的基础上,生成周围 agents 的新未来轨迹。这样,一个具体失败案例就可以被扩展成一组具有相似风险模式的闭环测试场景。
原场景,前车减速。
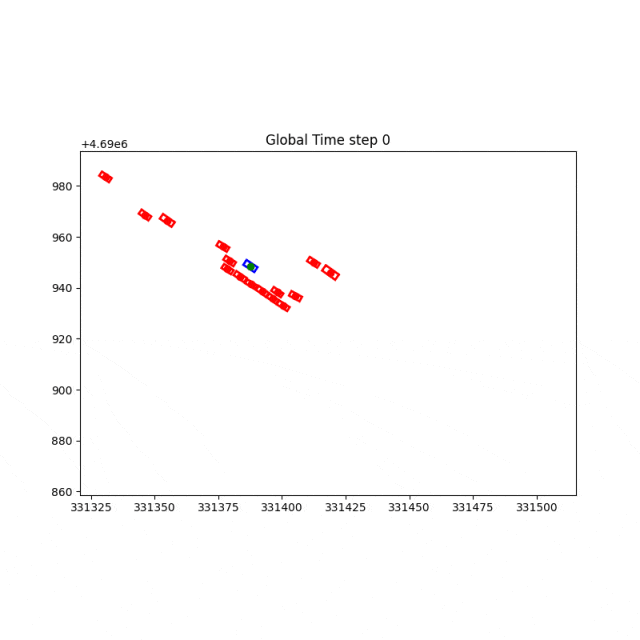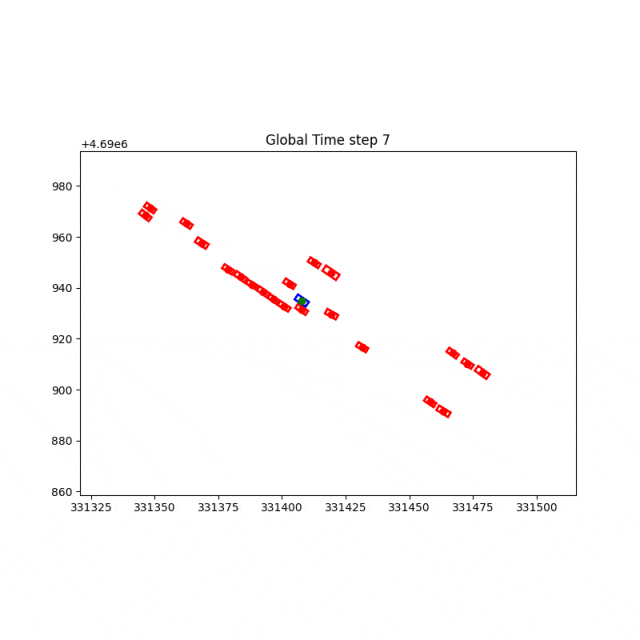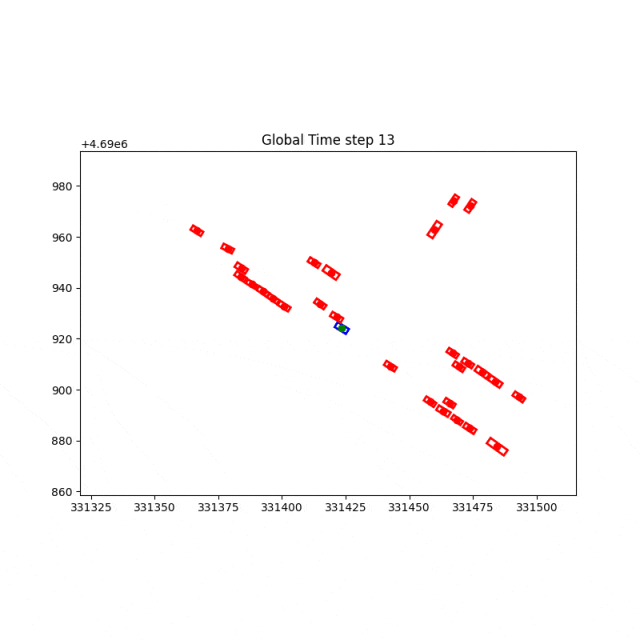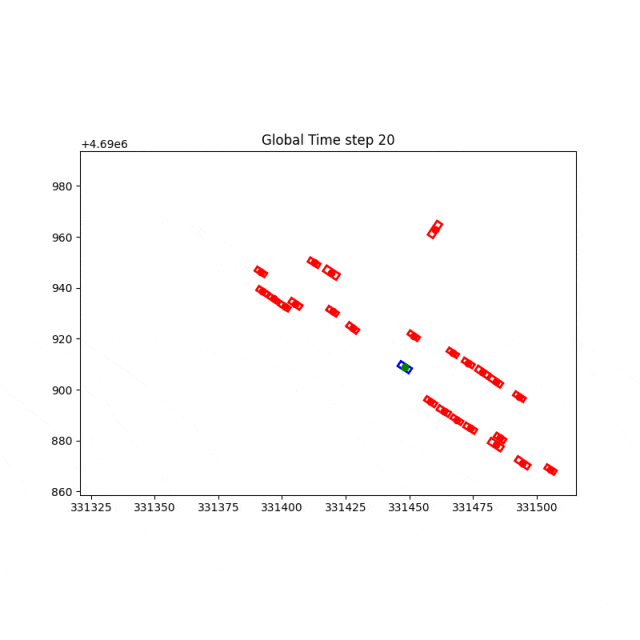
泛化场景,借道绕行前车。
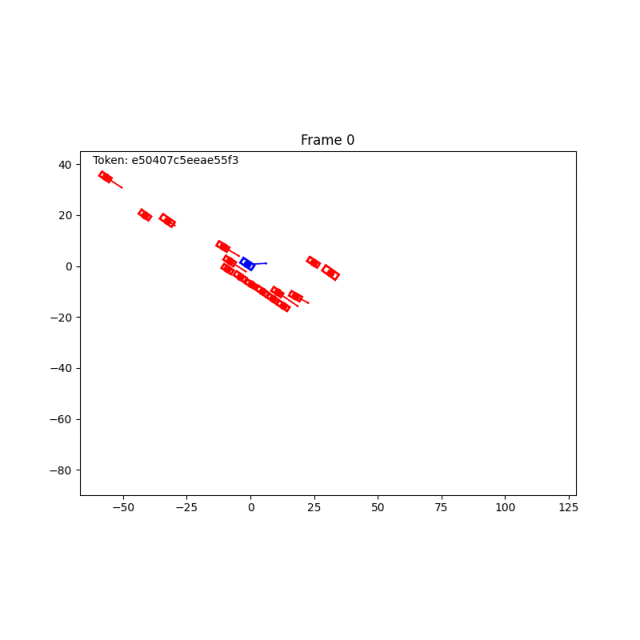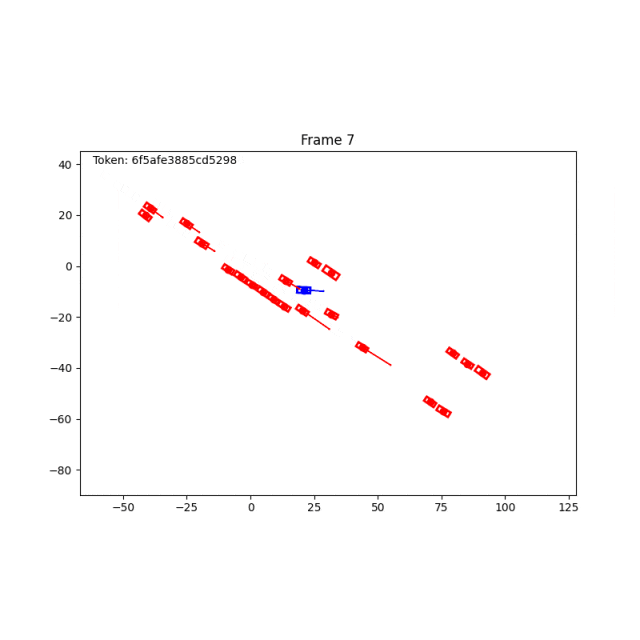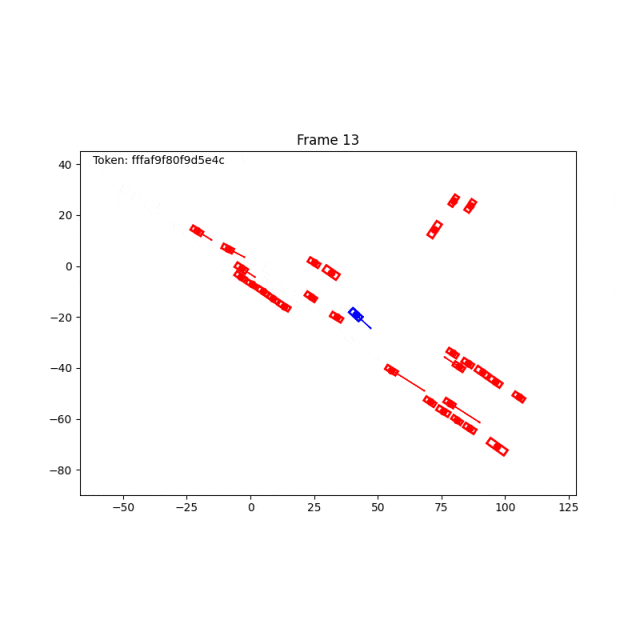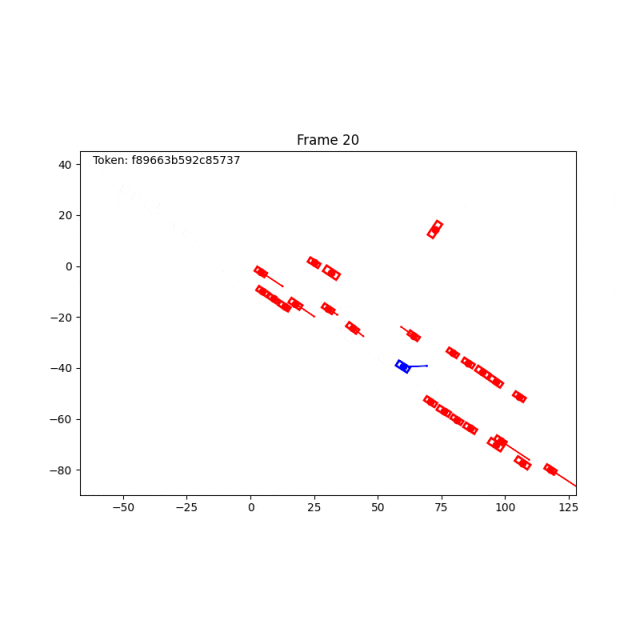
除了BWM,World Engine也支持log replay和IDM。log replay适合复现真实日志,IDM提供规则驱动的交通交互,而 Behaviour World Model 则进一步提供学习型的难例扩建能力。
也就是说,World Engine不只是复盘一次失败,而是可以把一次失败扩展成一类可渲染、可交互、可用于闭环评测和后训练的难例资产。
在World Engine中,难例场景不只是用来测试模型,也会进一步用于后训练。这里采用的不是简单的监督微调,而是behaviour-regularized reinforcement learning:
模型在闭环仿真中根据奖励信号学习,同时通过行为约束避免偏离原有预训练策略太远。
论文将自动驾驶任务建模为POMDP。模型根据传感器观测输出驾驶动作,World Model负责推演周围交通参与者的行为,SimEngine负责生成对应的传感器观测,两者共同构成一个可交互的闭环训练环境。策略在这个环境中不断试错,并通过最大化累积奖励进行更新。
奖励函数覆盖安全性、有效性和舒适性等目标,包括collision avoidance、drivable-area compliance、ego progress、time-to-collision margin和ride comfort。
相比只模仿人类轨迹,这些奖励能直接约束模型在闭环中的真实驾驶表现。
为了避免强化学习“训偏”,论文在目标函数中加入了对预训练策略的KL regularization,使post-trained policy在提升长尾和safety-critical场景表现的同时,仍然保持接近pre-trained policy。
训练经验则同时来自真实logged trajectories和World Engine生成的simulated rollouts:
前者维持common driving能力,后者补充稀缺的长尾难例。再结合hard experience mining,系统会优先筛选near collision、复杂博弈、recovery manoeuvre等高价值经验,让模型更集中地修正最容易暴露短板的场景。
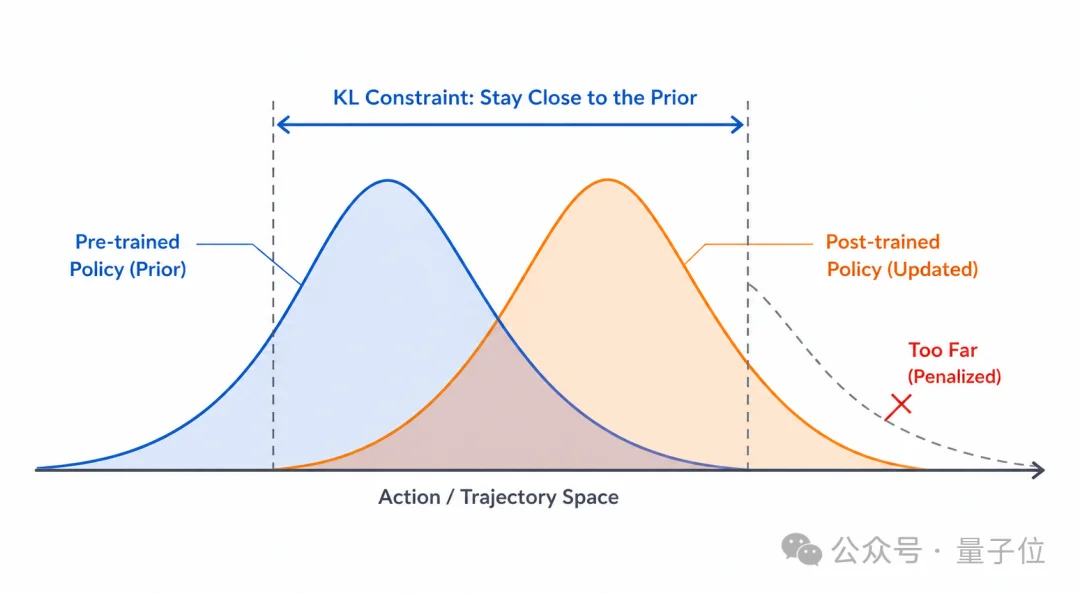
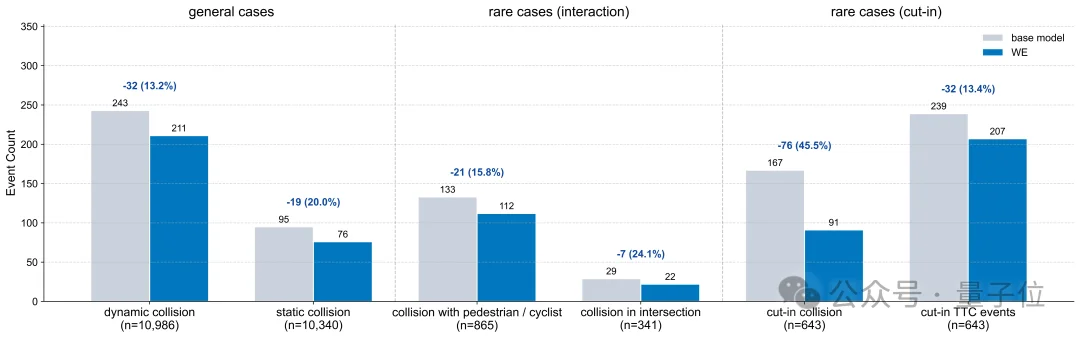
在华为ADS的工业级闭环验证中,World Engine后训练后的模型在6类安全指标上均降低失败事件。其中最显著的是rare cut-in场景:在643个cut-in测试案例中,碰撞事件从167次降至91次,减少76次,降幅达到45.5%。




实车验证中,World Engine 后训练模型在上海市区完成约200km道路测试,覆盖白天/夜晚、晴天/雨天等多种条件,全程0接管。



从工业级闭环仿真到真实道路测试,World Engine给出的信号很明确:自动驾驶的安全提升,不能只依赖更大规模的被动数据采集。真正决定系统上限的,是能否主动发现长尾失败、重建高风险交互,并通过后训练把这些稀缺经验转化为策略能力。
这也意味着,自动驾驶正在进入类似大模型发展的新阶段:预训练负责获得通用驾驶能力,而后训练负责对齐安全边界、修正长尾缺陷、持续提升真实交互中的可靠性。
World Engine 的意义不只是提出一个新的仿真框架,而是把 Post-Training for Autonomous Driving变成了一条可验证、可扩展、可进入量产研发闭环的技术路线。
论文标题:World Engine: Towards the Era of Post-Training for Autonomous Driving
代码地址:https://github.com/OpenDriveLab/WorldEngine
论文网页:http://arxiv.org/abs/2606.19836
主页:https://opendrivelab.com/WorldEngine/
数据集:https://huggingface.co/datasets/OpenDriveLab/WorldEngine
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
