# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
先说个事儿,我昨天做了个挺好玩儿的梦:踩着滑板在城市大道上飞!驰!
醒过来还意犹未尽,结果没想到AI不光帮我还原了画面,还把我拉进梦里玩了一把。
我踩着滑板往前冲,换方向、加速、跳跃、甚至秀了个Ollie(豚跳)~

属实给我整精神了,AI啥时候会干的这事??
不卖关子了,这是HappyOyster 1.0(快乐生蚝)实现的,阿里ATH推出的可实时构建和交互的开放式世界模型产品。
看到世界模型四个字,可能有朋友好奇:这和我之前玩的Sora那些有啥区别?不都是AI生成画面嘛?
嗯……还真不是一回事。
咱先简单聊两句行业现状啊,过去这一年多,AI视频赛道卷得确实热闹,各种产品轮番上场,画面精度一个比一个高,看着确实挺惊艳。
但用多了就会发现一个共性问题:它们都是「单程票」。
你写一段描述,模型渲染出一段视频,生成完,就完了,然后你就只能看,更不能跟画面里的角色互动。
而且时间一拉长,画面大概率就会崩坏,比如角色前一秒拿着剑后一秒空手了,走两步脸都换了一张。
这也是为啥市面上AI视频基本都是短片段,不是不想做长,是长了真绷不住啊……
说白了,当前文生视频的天花板,就是一段好看但不可更改的影像素材;
而HappyOyster 1.0做的是一件完全不同的事——
打造一个完整可演绎、可探索、可互动的数字世界。
画面生成出来的那一刻,体验才刚开始。你可以一边看一边下指令,世界实时反馈并持续演化。
就好像以前你是观众,现在你成了世界的…主人。

那这只快乐生蚝到底有多快乐呢??下面就继续实打实测一波!
HappyOyster 1.0主打两大核心模式:Adventure(世界探索)和Directing(实时导演)。
Adventure是「用动作探索,世界即刻延展」的开放漫游模式,你亲自下场当主角;
Directing是「用镜头叙事,故事随心掌控」的导播执导模式,你站在世界之上当导演。
一个管“身体”,一个管“脑子”,覆盖了两种截然不同的创作和体验诉求。
咱先来体验Adventure模式。
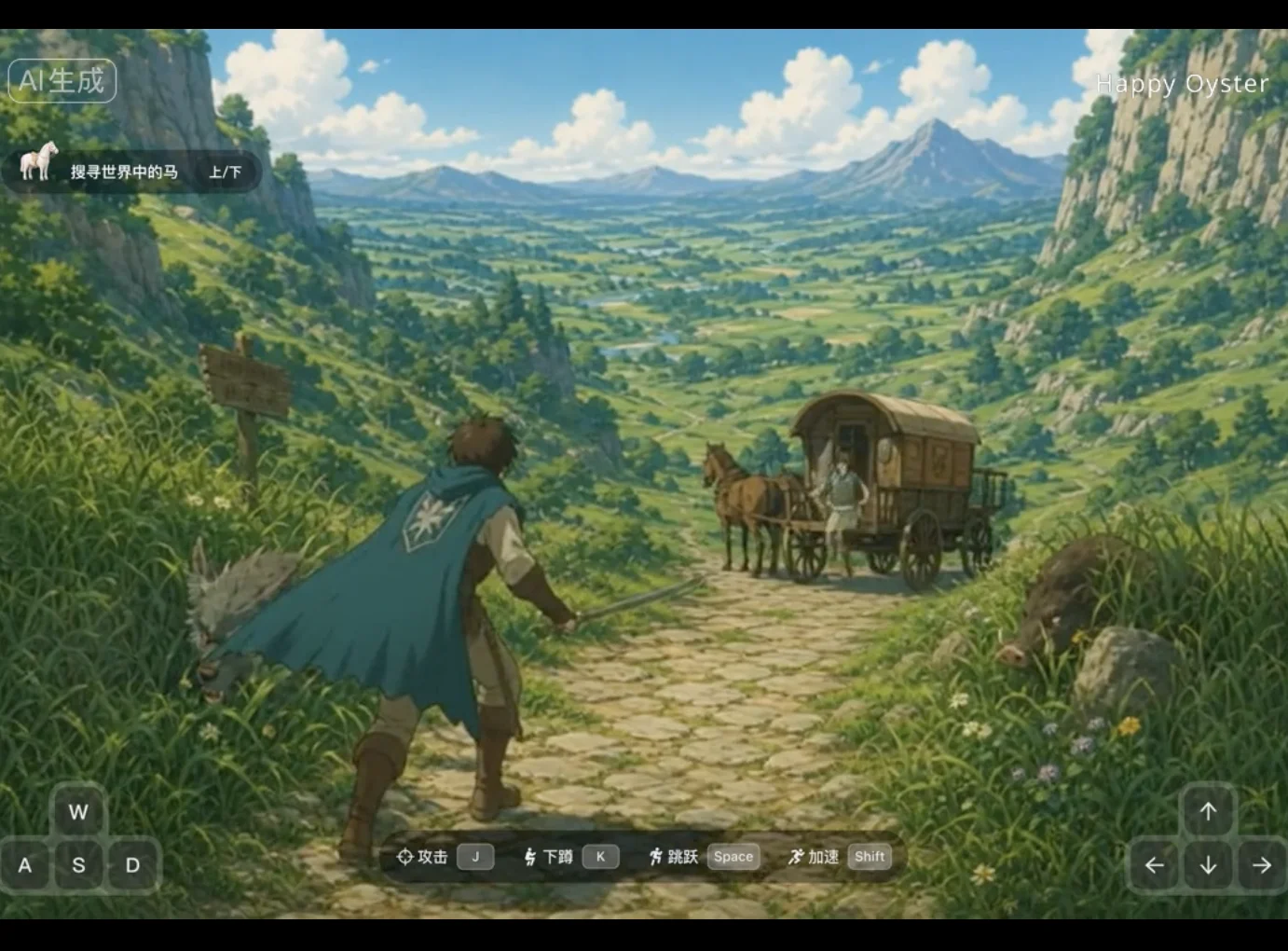
我丢了一张吉卜力风格的草原图进去,画面生成的一瞬间直接把我拉了进去,整个画面是活的,在等我操作。

那我就不客气了,直接动手!
1.0版本新增了一套很丰富的交互按键,有加速、下蹲、攻击、跳跃,操作手感跟你玩的3A大作相当接近。
我按了一下前冲,少年迈腿就跑起来;按攻击键,少年开始挥剑;再按跳跃,少年腾空而起,落地那一刻角色屈膝动作,镜头有个上升和下坠的变化,这细节属实拉满了。
关键是,这些全都不是预先做好的动画素材,是模型根据你的操作实时推演出来的。
为啥这么说呢?因为同一个场景我反复试了好几次,每次动作角度不一样,角色的姿态也不一样。
而且模型有个很聪明的设定,它会根据场景内容自动匹配可玩的交互方式。
比如我这个画面里有马车,世界就会解锁骑马互动彩蛋。少年走到马车旁,触发对应操作指令,就能直接上马骑行!!
如果创建的世界里有汽车,那么就会自动匹配开关车灯、鸣笛的玩法,主打一个「画面有什么,就能玩什么」。

而且探索过程中还能随时截屏留存画面,也能保存世界,一键对外分享链接,别人点进来就能看到你创建的完整世界。
意思是,方便发朋友圈了(doge)。
如果说Adventure是让你下场当主角,那Directing就更过瘾了,直接让你当导演。
Directing支持多模态参考,@一张图片就能锁定角色外观,咱直接就是一个POV恋爱互动先安排上!

我给她设定了一个近景特写镜头,全程第一视角对视,然后随手打了几条互动指令,效果be like:

好好好,AI生视频这下都吃上自助餐了,我狂吃!
而且1.0版本在Directing模式上做了几个相当重磅的升级,体验完之后我只想说:这才是创作者的终极玩具!
我先用一条prompt启动了一段剧情:
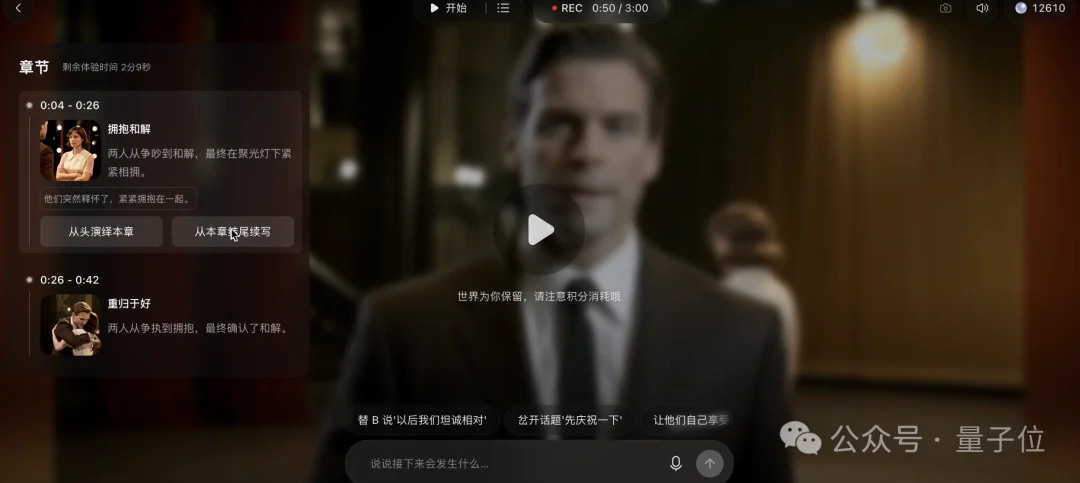
在舞台上,两个人面对面激烈争吵。
看了大概二十秒之后,我觉得剧情可以转折了。
于是我输入了一条新指令:
他们突然释怀了,紧紧拥抱在一起。
接收到新指令后,两个角色的表情开始缓和,身体从对抗姿态慢慢转向靠近,最后紧紧拥抱在一起。

而且,整个过程中,不光是场景,两个角色的脸、衣服、体态、发型完全没有变!!
好戏还没完——
1.0另外杀手锏功能是回溯和剧情分支。
比如,我可以直接回退到争吵的那个节点,换条完全不同的指令,画面就会重新演化。
或者从同一个节点续写,设计出A、B两条完全不同的故事线。
等等,这不就是创作者梦寐以求的平行宇宙嘛!!!
而且所有这些操作都是流式生成的,即说即演,不用等渲染。你随时插话,剧情随时响应,这对内容行业来说,属实是黑科技啊……
更贴心的是,官方还写了份体验指南放在网页上,教你怎么创建更好的世界~
上面体验了这么多,估计有朋友已经按捺不住了:
这玩意儿到底是怎么做到的?跟文生视频在技术上有啥区别?
咱先把最根本的概念差异说清楚:
文生视频的工作方式是文本→视频的单向条件映射,你输入一段描述,模型一次性离线渲染出一段固定的像素序列。
世界模型学的则是一套完全不同的东西,是当前状态+用户动作→下一个状态的转移规律。
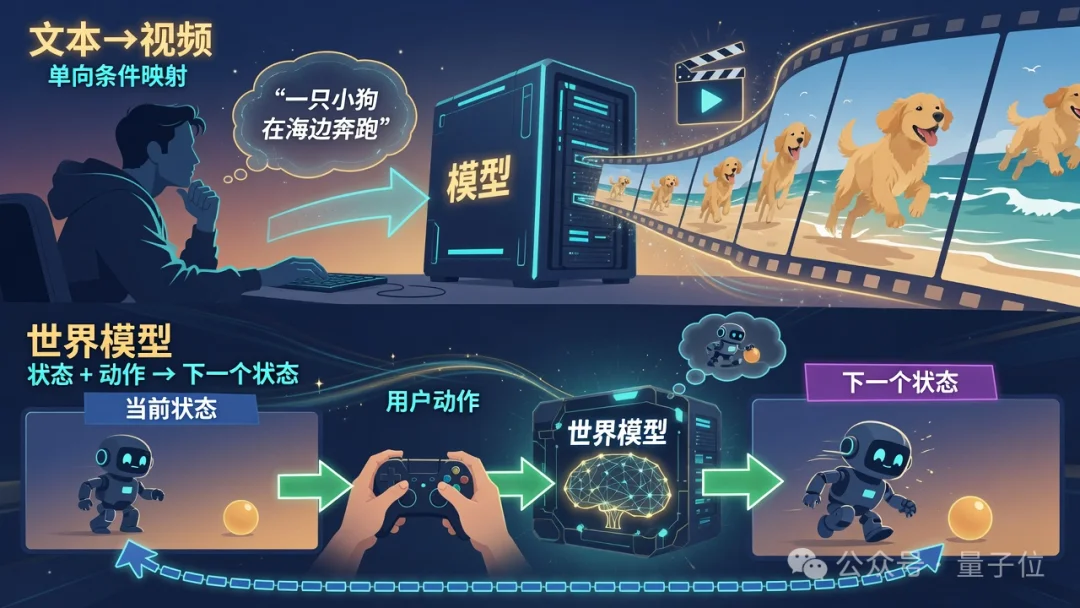
这就要求模型必须同时具备三重能力:物理规律的隐式建模、长程因果链路的追踪、外部干预的即时响应。
首先要说的就是闭环世界状态建模。
要让一个世界持续运行,最朴素的思路是记住所有历史画面,每生成新一帧,就回头看前面所有帧来保持连贯性。
但问题是,这么干计算量会指数级膨胀,时间一长直接寄。
HappyOyster 1.0在这里把世界状态压缩成隐状态摘要(Latent State),在生成链路上递归传递,支撑长程一致性。
就像接力跑一样,跑下一棒之前,上一棒把「关于现在世界的一切」写成一张纸条递过去,一棒一棒往后传。
每生成新的一帧,模型只需要拿到上一帧的那张纸条加上你新发出的指令,就能推演出下一帧。
所以几分钟下来世界不会乱、因果关系不会断。
而且1.0版本因为这个纸条可以被存档,所以暂停、回溯、分支叙事这些功能就自然而然实现了。本质上就是在某个时间点把纸条存一份副本,想从哪继续就从哪继续。
一个架构设计,直接把产品的交互想象空间整个撑开了。

第二项核心技术,是内生一致性,解决了生成画面里角色频繁换脸的痛点。
文生视频最头疼的问题就是主体漂移,人物走几步脸就变了,衣服颜色也跟着跑偏。
HappyOyster 1.0以持久的参考表征参与全程注意力来解这个问题。通俗点说,就是给每个角色、物品、场景元素都发了一张「身份卡」。
不管镜头怎么切、角色怎么转身、被其他物体遮挡多久再出现,模型每次生成新画面时都会对着身份卡检查,保证角色不变样不变形。
还有开放因果动作空间,打通动作与语言的表达逻辑。
很多交互式系统的做法是预定义一个动作集,比如能跳、能跑,但只能做这些。
HappyOyster 1.0把动作指令和自然语言放进了同一个语义接口。
比如,你说骑上那匹马,模型就自己推演出上马的完整动作序列和马开始跑的物理反馈。
动作空间是开放的,语言本身就是遥控器,不需要任何人工预设,模型自己就能推演因果。
最后说说长时序音视频协同。
HappyOyster 1.0的音频和视频是在同一个世界状态下联合解码生成的,不是先出画面再配音。
这意味着脚步声跟着你走、雨声跟着天气变、打击音效跟着攻击动作来,真正做到了声画物理合规。
这四大技术一起协同发力,这个世界才能真正活起来。
不过技术做得好不好,光靠体验感受还不够,得有量化标准来衡量。
但世界模型作为一个新兴领域,目前行业里还缺乏一套针对“世界逻辑”的系统性评测基准。
针对这个痛点,HappyOyster团队正在牵头与南京大学共建世界模型评测基准,这也说明,HappyOyster不只是在做产品,更承担起定义赛道标准的责任。
从传统文生视频生成一段固定影像,到世界模型搭建可进入、可操控、持续自主运转的完整数字空间,HappyOyster 1.0正是这条全新路线的落地先行者。
它把AI的生成能力从单向输变成了双向实时交互。
而且,一旦世界模型走通了这条路,很多行业的想象空间就变大了。
比如说游戏行业,不用搭建庞大的美术资产库、配置复杂的物理引擎,给HappyOyster 1.0丢一张概念图,很快就能跑出一个具备物理反馈和NPC交互的可玩场景。

在内容生成赛道上,如果一个剧本能分叉出十条故事线,观众自己选走向,那就可能催生一个全新的互动内容业态。
除此之外,文旅景区做虚拟漫游、博物馆做沉浸式历史还原……都可以用HappyOyster 1.0进行沉浸式体验。
现在,HappyOyster 1.0已经正式上线,用手机号注册就能玩!此外,API计划在近期开放。接下来无论是游戏创作、短剧生成、文娱体验,还是数字人直播、虚拟陪伴,都可以用上世界模型,给用户带来全新的交互体验。
这意味着人人都有机会亲手搭建、操控自己的专属虚拟世界,想想就「狠」带劲!
阿里这次属实是打开了大家的想象力,以后谁还满足于只看视频啊……
体验地址:https://www.happyoyster.cn
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
