# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

200 亿元估值已经成了头部具身智能公司的新标杆。
最近和朋友聊天,一个同样关注具身智能的朋友说,自己之前有点错判形势了。年初前三个月,行业融资已经很热闹,当时觉得大家该融的应该也融得差不多了,接下来可能会安静一点。结果现在看,完全不是这么回事。
最近两天,最轰动的融资消息是,自变量机器人又连续完成了 B+、B++ 和 C 轮融资,估值突破 200 亿元人民币。而且是全部交割后的估值。
极客公园 4 月刚刚写过,自变量完成了 B 轮融资,投资方是小米战投。也就是说,接下来的两个多月里,自变量又连续完成 3 轮重磅融资。
这几轮的投资方包括中国移动、红杉中国、IDG 资本、源码资本、达晨财智、中金资本、中保投资等 30 多家顶级机构,基本都是行业里非常有分量、判断也很谨慎的资金。能在短时间内拿到这么多高质量资金,本身就说明自变量这轮融资的含金量很高。
最近具身智能赛道里,新公司依然很多,不少公司刚成立就能拿到不错的估值。但像自变量这轮融资,展现了头部公司的吸金速度,仍然快过新公司的成长速度。此前,百亿估值还足够惊人;这一轮之后,200 亿元估值已经成了头部具身智能公司的新标杆。
在这样的热闹背后,大家自然会想:具身智能为什么现在这么值钱?自变量又为什么这么值钱?
一个重要原因或许是,市场对具身智能公司的定价逻辑,正在逐渐向大模型公司靠拢。模型能力已经开始分出高下,头部公司一旦被认为更有潜力,就会更容易聚集资金,也更容易被重新定价。
自变量这一轮估值突破 200 亿元,放在更大的行业背景里看,不只是具身智能融资热的延续,更是资本对「自研具身大脑」的一次集中认可。
过去两年,行业最容易被看见的是机器人的「身体」:本体、关节、运动控制、供应链。谁能跑起来,谁更吸引眼球。但到今天,越来越多人开始认为,机器人本体和运动能力正在快速收敛,至少已经不是最稀缺的变量。
资本开始看向身体之外的问题:机器人有没有一个足够强、足够通用、足够理解物理世界的「大脑」。而大脑的技术路线,也恰好在这段时间进入了变化期。
自变量被投,很大程度上是因为它从一开始就把自己定义成一家模型公司。创始团队本身有大模型背景,他们最早想做的,就是「基于具身大模型的通用操作机器人」。
相比于其他具身公司,自变量一直非常关心模型架构。很多公司今年才开始密集讨论世界模型,但去年年底参加极客公园创新大会时,极客公园掌握的信息是,自变量已经在尝试融合世界模型和其他具身智能路线。
到了今年 4 月,自变量发布 WALL-B,并提出「世界统一模型」WUM 架构。

这是一个和传统 VLA 不同的架构尝试。过去很多 VLA 模型,本质上是把视觉、语言、动作模块拼接起来,让机器人在看到环境、理解指令之后生成动作。WALL-B 想解决的问题更底层:机器人大脑能不能在同一个模型里理解视觉、语言、动作和物理变化。
按照自变量的定义,WALL-B 是一个完全自研的机器人大脑,没有跟随海外的 VLA 或世界模型路线。它将视觉、语言、动作、物理预测等能力放在同一个网络中,从零开始联合训练、融为一体,试图消除模块之间的边界和数据搬运损耗。
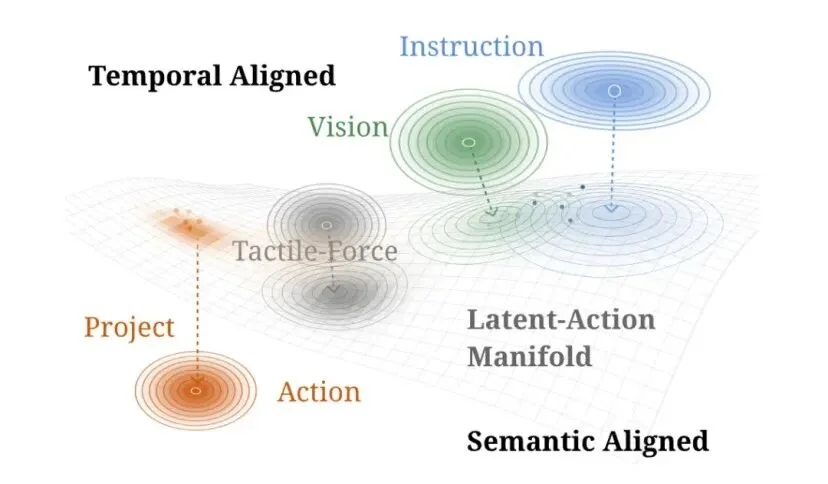
这使得 WALL-B 具备几个重要特征:它是原生多模态的,因此具备更好的空间推理能力;它不只是生成动作,还要理解物理规律,并预测环境与事件如何演化;它也具备记忆能力,可以在与环境的互动中持续积累经验。
从底层架构到训练范式,对具身大模型做一次重写,意味着很强的技术审美。对资本来说,这类公司更容易被理解成「有确定技术框架的模型公司」,也是「有模型原创研发能力的具身公司」。
当然,自变量并不是只有一条技术支线。
围绕具身大脑这条主线,自变量今年还发布了两个模型成果。开源模型 WALL-OSS-0.5 试图回答预训练模型能不能在不做大量后训练的情况下,直接完成真实任务;WALL-WM 则把世界模型从均匀时间采样推进到「事件级预测」,让模型围绕物理世界真正发生变化的节点来对齐语言、视觉和动作。
这两个成果说明,自变量在做 WALL-B 的同时,也在持续探索具身模型的泛化性来源、模态对齐和世界建模方式。它对外展示的不是单点技术,而是一条比较清晰的技术路线:用统一模型承载视觉、语言、动作和物理预测,再通过预训练、世界模型和事件级预测,不断提升机器人在真实世界里的泛化能力。
也正因为如此,自变量这轮融资真正被押注的,不只是某一台机器人、某一个场景,甚至也不只是某一个模型版本。资本押的是它能不能率先做出一个足够通用的具身大脑。
不过,具身大脑不是只靠模型架构就能做出来的。
和纯软件大模型不同,具身智能最难的地方在于,模型必须真正理解物理世界。而理解物理世界,离不开大规模、高质量的交互数据。
这也是自变量这轮融资里,另一个容易被资本看重的地方:它不只是做模型,也在自己搭建数据和 Infra。
过去,具身智能行业获取数据的成本很高。一方面,真实世界里的复杂、危险、罕见场景很难大规模采集;另一方面,机器人数据不是简单的视频或文本,而是包含视觉、语言、动作、力反馈、空间状态等多模态信息,采集之后还要经过清洗、标注、质量控制和数据增广,才能真正用于模型训练。
自变量的做法,是自研一套可扩展的模型驱动型数据管线,把数据采集、清洗、自动化标注、质控和增广整合成工业级的数据生产系统。它还自研了数据合成模型,用来复现真实世界中难以大规模采集的复杂场景,在物理精度上尽量和真实世界对齐,从而更快积累稀缺数据。
更关键的是,自变量近期发布了 XR Zero 系列无本体数采方案。按照公司的说法,这套方案具备全行业唯一的全身移动数采能力,可以支持全模态数据回放、迁移和模型训练,并已经通过模型闭环验证,将训练模型所需的数据成本降低了 95%。

这件事的重要性在于,具身智能公司的竞争,最终会落到迭代速度上。谁能更便宜、更快地获得有效数据,谁就能更快训练模型、验证模型、部署模型,再从真实场景中回收新数据。
围绕这个闭环,自变量还搭建了面向具身大模型的分布式训练与高性能推理框架,针对多模态、长序列和连续动作控制做了优化。它想解决的不是单次 demo 能不能跑通,而是从本体执行、数据采集、模型再训练到本体部署,能不能形成一个持续运转的数据回流系统。
这种 Infra 能力,也在今年早些时候的全球具身智能开发者大会黑客松上被展示过。参赛选手只用了三天,就完成了从数据采集、模型训练到真机部署的全流程上手。通常情况下,专业研究实验室搭建类似流程,至少需要六个月。
所以,自变量的价值并不只来自一个更漂亮的模型故事。它试图把模型、数据、训练、推理、部署和回流全部连起来。对于一家具身智能公司来说,这意味着它不只是在造机器人,也是在搭建一套让机器人持续变聪明的系统。
如果说模型、数据和 Infra 决定了一家具身智能公司的长期上限,那么真实场景落地,决定了它能不能尽快穿过 demo 阶段。
这也是自变量和很多具身智能公司不同的地方。它并没有只停留在实验室或发布会现场,而是同时把机器人推向了家庭和产业场景。
在机器人本体方面,自变量已经自研并量产了量子一号、量子二号两款高性能机器人,机械臂、关节模组、动力驱动器、主控制器等核心零部件也实现了全面自研,并和算法能力深度适配。这为机器人进入真实家庭和工业产线,提供了足够稳定的硬件载体。
今年 3 月,自变量和 58 集团旗下 58 到家合作,推出智能保洁家庭服务。机器人不再只是站在展台上完成演示,而是和保洁阿姨一起进入普通家庭,协同完成真实家政任务。按照自变量的说法,这是全球首个机器人大范围进入普通家庭、真实服务大众的项目。
这件事的意义在于,家庭场景可能是最复杂、最不可控的具身智能场景之一。每个家庭的空间布局不同,物品摆放不同,用户习惯也不同。机器人进入家庭,面对的不再是被精心布置过的测试环境,而是大量随机、琐碎、长尾的真实需求。

到了今年 5 月,自变量又推出了机器人常驻家庭的「X 家庭成员计划」,为用户提供长达 1 个月的机器人常驻服务,去覆盖更持续、更多样的家庭需求。这意味着具身机器人第一次开始在更长周期里接受普通用户的检验。它需要证明的不是某个动作能不能完成,而是在真实生活里能不能持续提供价值。
与此同时,自变量也在 B 端场景里推进落地。
工业生产线是检验具身智能生产力的另一个重要场景。它对操作精细度、稳定性和效率都有更高要求。今年 3 月,自变量和金杯股份签署协议,合资成立金智变量机器人,并进入金杯股份所属华晨宝马座椅和内饰产品一级供应商生产线。接下来,搭载具身模型的机器人将在集团多个板块批量落地,并面向全球战略合作伙伴和工业客户提供解决方案。

在物流场景,自变量和顺丰达成合作,把具身大模型和机器人引入复杂的工业物流环境。物流分拣和供件对效率、节奏和稳定性要求很高,也非常考验机器人在动态环境中的感知、决策和执行能力。自变量希望通过机器人深度嵌入具体作业流程,实现更自动化、更柔性的智能分拣与供件,让具身智能在真实生产系统里释放经济效益。

从家庭保洁,到工业产线、物流分拣,自变量正在尝试证明一件事:通用具身智能不是只存在于技术叙事里,它必须能进入具体场景,完成具体任务,并在真实用户和真实产业流程中被反复检验。
这也解释了为什么资本会在这个时间点重新给自变量定价。具身智能行业正在从「看谁能做出机器人」进入「看谁能让机器人变成生产力」的阶段。机器人本体能力逐渐收敛之后,真正拉开差距的,是具身大脑、数据闭环、工程系统,以及能否在 C 端和 B 端同时跑通商业化。
具身智能的马太效应已经开始显现。
资本和产业伙伴的关注重点,正在从分散押注各类机器人公司,逐渐收敛到少数具备模型能力、数据能力、工程能力和落地能力的头部公司身上。自变量这一轮融资,本质上也是这种行业共识的一次集中体现。
面向未来,真正能够实现通用具身智能愿景的公司,大概率只会是少数。
就像它的名字所暗示的那样,自变量似乎希望成为那个主动改变行业状态的变量,而资本市场也正在押注于此。
*头图来源:自变量
文章来自于"极客公园",作者 "Li Yuan"。


