# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
马斯克搞大模型,速度也奇快。
Grok 1 开源才刚有 10 天,Grok 1.5 就来了。
本周五早上,马斯克旗下的人工智能公司 xAI 正式推出了 Gork 大模型的最新版本 Grok-1.5。新一代模型实现了长上下文理解和高级推理能力,计划将在未来几天内向早期测试人员和 X 平台(前 Twitter)上的现有 Grok 用户提供。
上周一,马斯克刚刚开源了 3140 亿参数的混合专家(MoE)模型 Grok-1。通过开源 Grok-1 的模型权重和网络架构,Gork 项目已展示了 xAI 截至去年 11 月所取得的进展。在最新模型 Grok-1.5 中,Gork 又有了进一步提高。
能力与推理
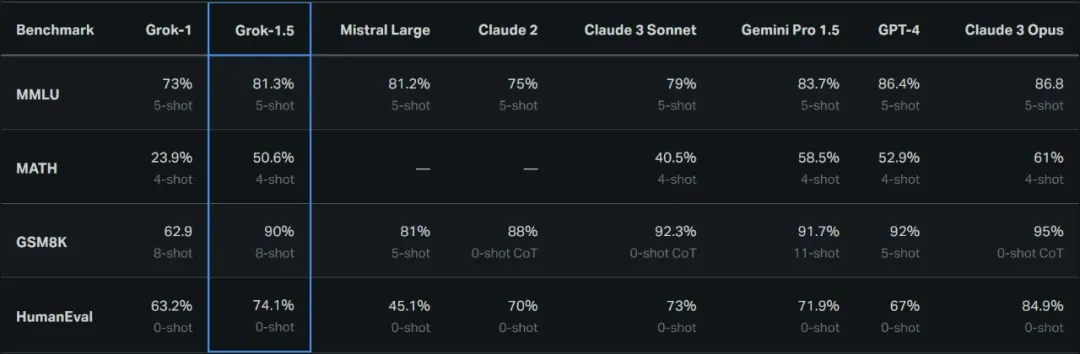
Grok-1.5 最明显的改进之一是其在代码和数学相关任务中的性能。在 xAI 的测试中,Grok-1.5 在 MATH 基准上取得了 50.6% 的成绩,在 GSM8K 基准上取得了 90% 的成绩,这两个数学基准涵盖了广泛的小学到高中的竞赛问题。
此外,它在评估代码生成和解决问题能力的 HumanEval 基准测试中得分为 74.1%。
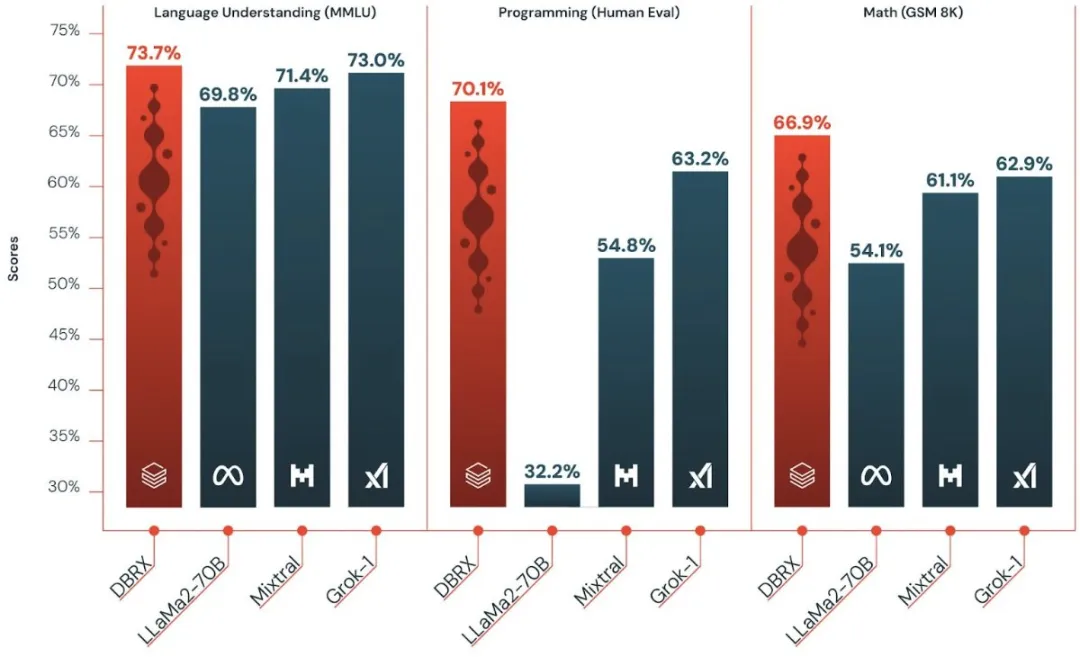
还记得昨天 Databricks 开源的通用大模型 DBRX 吗?当时的对比图表如下所示,看起来新版本 Grok 的提升是显著的。
就是不知这个大幅升级的 1.5 版会在什么时候开源?
长上下文理解
Grok-1.5 中的另一个重要升级是在其上下文窗口内可以处理多达 128K token 的长上下文。这使得 Grok 的容量增加到之前上下文长度的 16 倍,从而能够利用更长文档中的信息。
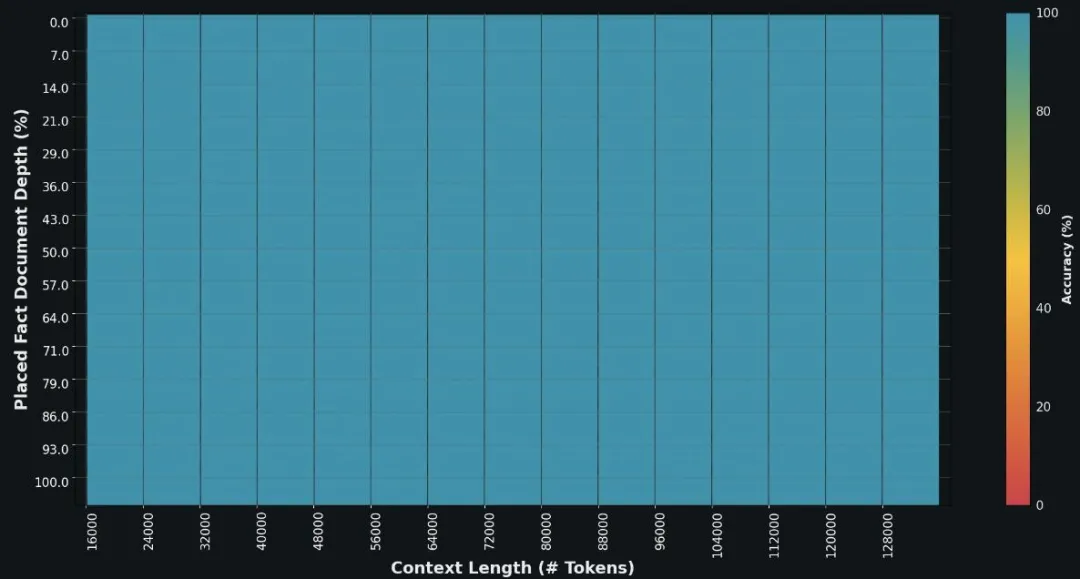
此外,该模型可以处理更长、更复杂的提示(prompt),同时在上下文窗口扩展时仍然能保持其指令跟踪能力。在大海捞针(NIAH)评估中,Grok-1.5 展示了强大的检索能力,可以在长度高达 128K token 的上下文中嵌入文本,实现完美的检索结果。
训练 Grok-1.5 的基础设施
xAI 进一步介绍了用于训练模型的算力设施。在大规模 GPU 集群上运行的先进大型语言模型(LLM)研究需要强大而灵活的基础设施。Grok-1.5 构建在基于 JAX、Rust 和 Kubernetes 的自定义分布式训练框架之上。该训练堆栈允许开发团队能够以最小的精力构建想法原型并大规模训练新架构。
在大型计算集群上训练 LLM 的主要挑战是最大限度提高训练作业的可靠性和正常运行时间。xAI 提出的自定义训练协调器可确保自动检测到有问题的节点,并将其从训练作业中剔除。工程师还优化了检查点、数据加载和训练作业重新启动等问题,以最大限度地减少发生故障时的停机时间。
展望
为了寻求替代微软支持的 OpenAI 和 Google 大模型的解决方案,马斯克去年推推动了 AI 创业公司 xAI,以创建他所说的「最大程度寻求真相的人工智能」 。去年 12 月,这家初创公司为 X 的 Premium+ 订阅者推出了 Grok。

xAI 表示,Grok-1.5 很快就会向早期测试者开放,其团队将继续改进 Grok。随着新版本推向公众,在未来几天 X 上的大模型将陆续推出一些新功能。
参考内容:
https://x.ai/blog/grok-1.5
https://www.reuters.com/technology/musks-xai-launch-improved-version-chatbot-2024-03-29/
文章来自微信公众号“机器之心”,作者:机器之心



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
