# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
始智AI wisemodel.cn社区将打造成huggingface之外最活跃的中立开放的AI开源社区。欢迎《加入wisemodel社区志愿者团队》以及《欢迎加入wisemodel开源共创计划》。
清华大学和智谱AI的研究团队提出了一个新型的级联模型——Relay Diffusion(RDM),该模型在具备原有级联方法的优点的同时,借助模糊扩散过程(blurring diffusion)和块状噪音(block noise)可以在任意不同分辨率间无缝衔接,像“接力赛”一样,极大地减少了训练和采样的成本。Relay Diffusion(RDM)模型的代码已经发布到了始智AI wisemodel.cn开源社区的代码模块,大家前往wisemodel社区了解详情。
https://wisemodel.cn/codes/ZhipuAI/RelayDiffusion(代码地址)
01
研究概述
扩散模型在近年来成为了最流行的生成模型,在训练高分辨率图像的扩散模型时,主要有两个主要障碍:一个是训练效率,另一个是噪声调度。
研究团队提出了Relay Diffusion(RDM),一个新的级联框架,以改进以前级联方法的不足。在每个阶段,模型从上一阶段的结果开始扩散,而不是基于它进行条件化并从纯噪声开始。本文的方法被命名为“接力赛”,因为级联模型像接力赛一样协同工作。本文的贡献可以总结如下:
(1)在频域分析了高分辨率扩散模型噪声调度困难的原因。以前的工作在分析信噪比(SNR)时假设所有图像信号来自同一分布,忽略了低分辨率和高分辨率图像在频域之间的差异。研究团队的分析成功解释了相同噪声水平在不同分辨率上显示不同感知效果的现象,并引入块噪声来弥合这一差距。
(2)提出了RDM,以在级联管道中解耦扩散过程和底层神经网络。RDM摆脱了低分辨率条件和其分布不匹配问题。由于RDM是从低分辨率结果而不是纯噪声开始扩散的,因此可以减少训练和采样步骤。
(3)在无条件的CelebA-HQ 256×256和条件性ImageNet 256×256数据集上评估了RDM的有效性。RDM在CelebA-HQ上实现了最先进的FID,在ImageNet上实现了最佳的sFID。

图 1:(左):在 ImageNet 256×256 和 CelebA-HQ 256×256 上通过 RDM 生成的样本。(右):在没有任何引导的情况下,对最近的扩散模型进行基准测试,以生成类条件的 ImageNet 256×256 图像。如果使用无分类器引导,RDM 可以实现 1.87 的 FID。
02
研究方法
2.1 动机
扩散模型在高分辨率图像生成中面临的挑战主要集中在两个方面:训练效率和噪声调度。对于高分辨率图像,相同的噪声水平会导致在频域中信噪比(SNR)更高,这意味着模型在早期阶段难以生成准确的图像。例如,图2(a)(b)展示了在64×64和256×256分辨率下,相同噪声水平产生的不同视觉效果和SNR曲线的变化。为了弥合这一差距,研究团队提出使用块状噪声,这种噪声在更大的分辨率图像上可以模拟较小分辨率图像上独立高斯噪声的效果。

图2:在添加独立高斯和块噪声后,空间和频率结果的示意图。(a)(b) 在64×64和256×256的分辨率下,相同的噪声水平在感知效果上有所不同,在频率图中,信噪比(SNR)曲线向上移动。(c) 在64×64分辨率下的独立高斯噪声和256×256分辨率下的块噪声(核大小=4)在空间域和频率域产生相似的结果。噪声为N()对于(a)。这些信噪比曲线对大多数自然图像都普遍适用。
2.2 Relay Diffusion模型
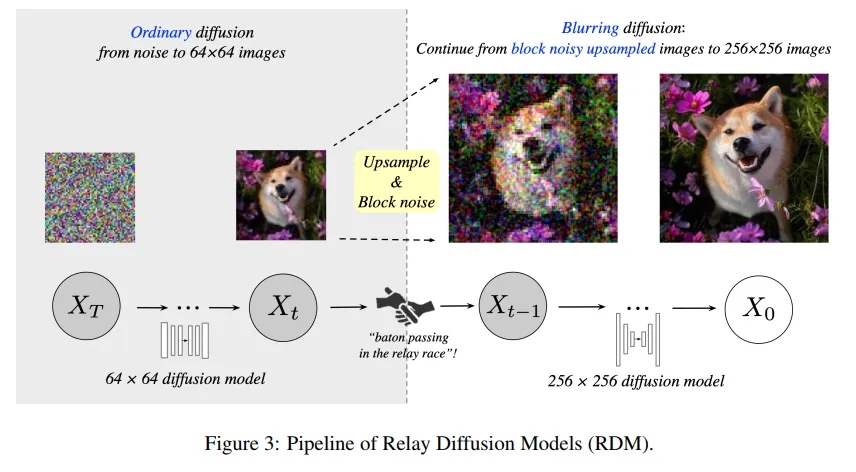
Relay Diffusion模型(RDM)是一个新的级联框架,旨在通过在每个阶段从上一阶段的结果开始扩散(而不是重新从纯噪声开始)来改进传统方法。这种方法类似于接力赛,前一个阶段的输出直接成为下一个阶段的输入。关键贡献如下:
频域分析:研究团队的分析揭示了在不同分辨率图像上相同噪声水平表现出不同视觉效果的原因,从而在RDM中引入了块状噪声来解决这一问题。与以往方法相比,RDM通过从低分辨率结果而非纯噪声开始扩散,减少了训练和采样步骤,同时避免了低分辨率条件及其分布不匹配问题。
块状噪声:通过在256×256分辨率下引入块状噪声(如图2(c)所示),研究团队模拟了64×64图像上独立高斯噪声的效果,从而在不同分辨率图像上实现了类似的频域特性和视觉感知效果。
2.3 随机采样器
研究团队为RDM设计了一个适应性的采样器,以适应扩散过程中噪声的特殊处理。特别地,团队利用了Heun方法来提高采样过程的精度,通过引入额外的校正步骤来优化采样质量,同时减少了所需的采样步数。
03
实验分析
3.1. 实验设置
本文使用CelebA-HQ和ImageNet进行实验。采用UNet作为扩散模型的骨干网络。在CelebA-HQ上训练非条件模型,在ImageNet上分别训练类条件模型。遵循EDM的实现,直接使用ImageNet在64×64阶段的发布检查点。64×64模型的浮点运算(FLOPs)大约是256×256模型的1/10。使用包括FID、sFID、IS、精度和召回率在内的多个指标进行全面评估。
3.2. 实验结果
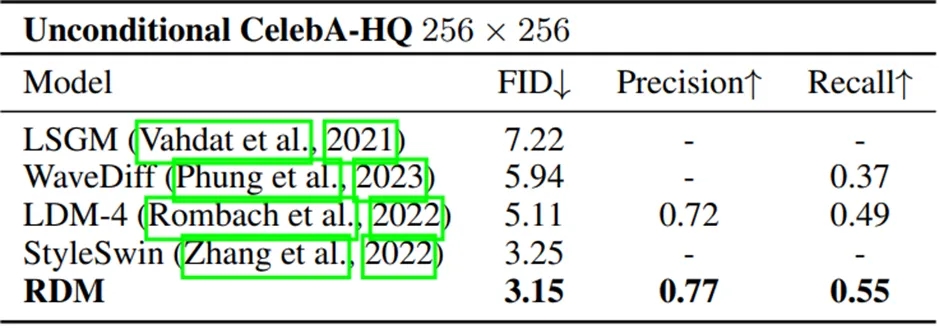
CelebA-HQ:RDM在CelebA-HQ 256×256上的性能超过了现有最先进的模型,并且在训练迭代次数方面更少(50M对比820M训练图像)。RDM在所有现有作品中取得了最佳的精度和召回率。具体结果如下表所示:
ImageNet:在ImageNet 256×256的类条件生成模型中,RDM展现出最佳的sFID,并在FID上超越了除MDT-XL/2之外的所有其他方法。采用固定但最优的CFG尺度,RDM的训练迭代次数仅为MDT-XL/2的70%(1.2B对比1.7B训练图像),表明通过延长训练和更细粒度的CFG策略,RDM的FID还有优化空间。具体结果如下表所示:

04
局限与展望
虽然RDM在多个方面取得了进展,但直接从数据集推导出最佳噪声调度的尝试表明,这一任务涉及的因素远比预期的要复杂。最佳噪声调度可能不仅与图像的分辨率有关,还与模型的结构和数据本身的特性密切相关。因此,未来的研究需要考虑这些额外的因素,以进一步优化扩散模型的性能。
总之,RDM为高分辨率图像生成提供了一个有效的新框架,并为扩散模型研究领域开辟了新的方向。未来的工作将继续在这一基础上探索,以克服现有方法的限制,并进一步提高模型的生成质量和效率。

本文来源于公众号 始智AI wisemodel,作者wisemodel



