# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
联邦学习使多个参与方可以在数据隐私得到保护的情况下训练机器学习模型。但是由于服务器无法监控参与者在本地进行的训练过程,参与者可以篡改本地训练模型,从而对联邦学习的全局模型构成安全序隐患,如后门攻击。
本文重点关注如何在有防御保护的训练框架下,对联邦学习发起后门攻击。本文发现后门攻击的植入与部分神经网络层的相关性更高,并将这些层称为后门攻击关键层。
基于后门关键层的发现,本文提出通过攻击后门关键层绕过防御算法检测,从而可以控制少量的参与者进行高效的后门攻击。

论文题目:Backdoor Federated Learning By Poisoning Backdoor-Critical Layers
论文链接:https://openreview.net/pdf?id=AJBGSVSTT2
代码链接:https://github.com/zhmzm/Poisoning_Backdoor-critical_Layers_Attack
方法
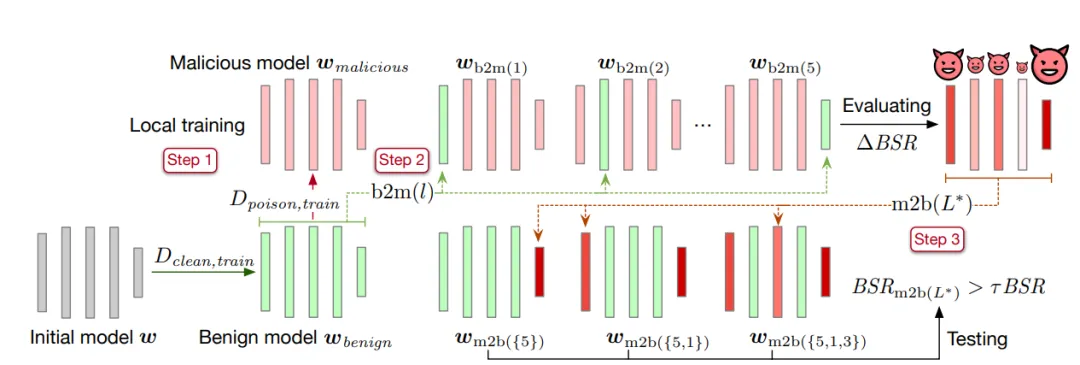
本文提出层替换方法识别后门关键层。具体方法如下:

在得到后门攻击关键层的集合之后,本文提出通过攻击后门关键层的方法来绕过防御方法的检测。除此之外,本文引入模拟聚合和良性模型中心进一步减小与其他良性模型的距离。
本文对多个防御方法在 CIFAR-10 和 MNIST 数据集上验证了基于后门关键层攻击的有效性。实验将分别使用后门攻击成功率 BSR 和恶意模型接收率 MAR(良性模型接收率 BAR)作为衡量攻击有效性的指标。
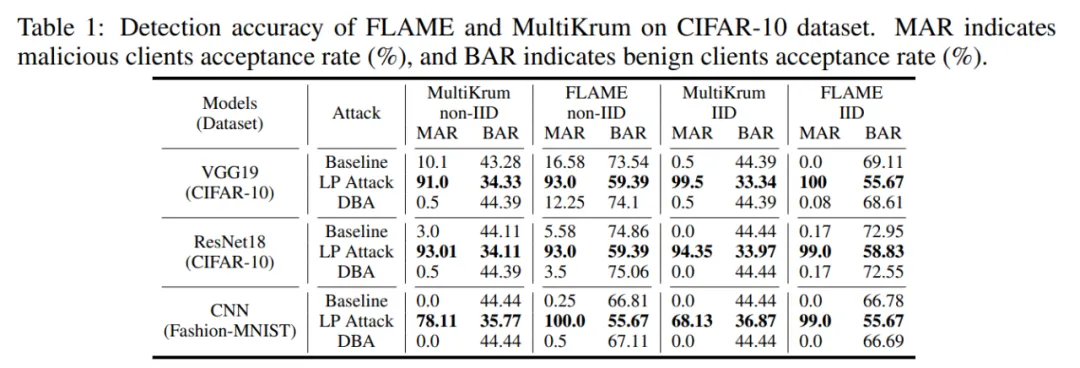
首先,基于层的攻击 LP Attack 可以让恶意客户端获得很高的选取率。如下表所示,LP Attack 在 CIFAR-10 数据集上得到了 90% 的接收率,远高于良性用户的 34%。
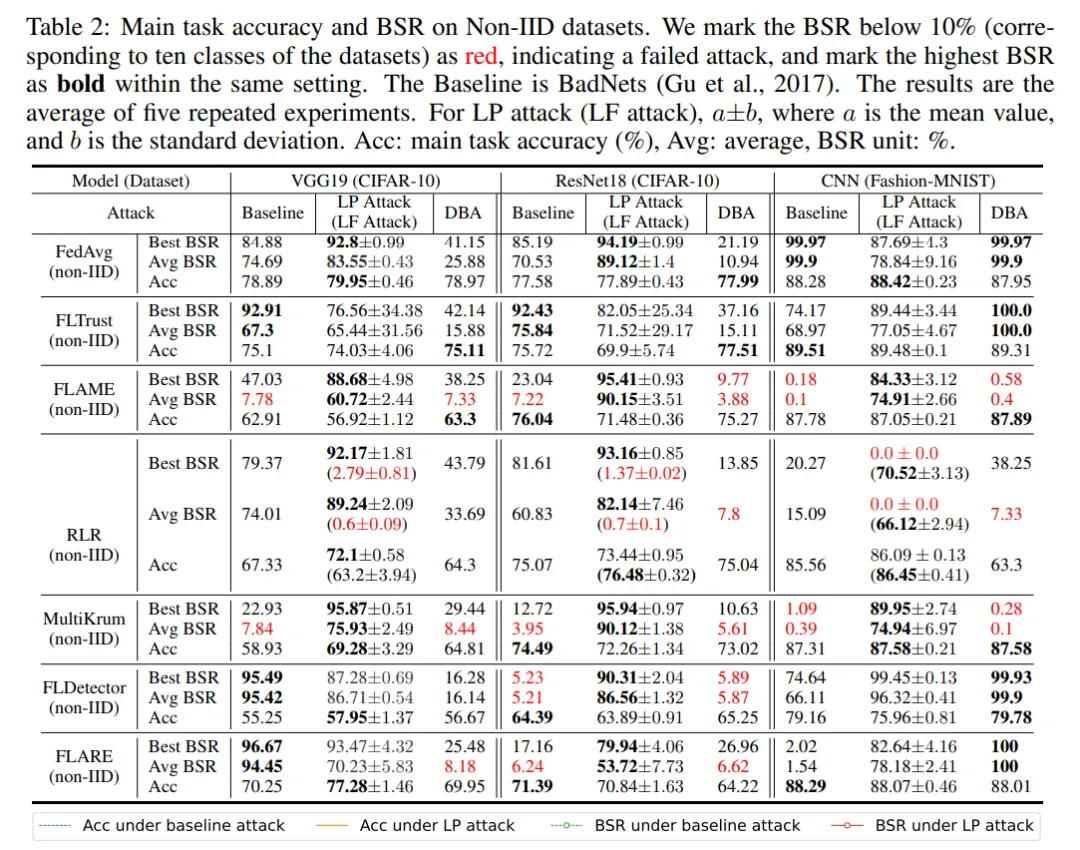
然后,LP Attack 可以取得很高的后门攻击成功率,即使在只有 10% 恶意客户端的设定下。如下表所示,LP Attack 在不同的数据集和不同的防御方法保护下,均能取得很高的后门攻击成功率 BSR。
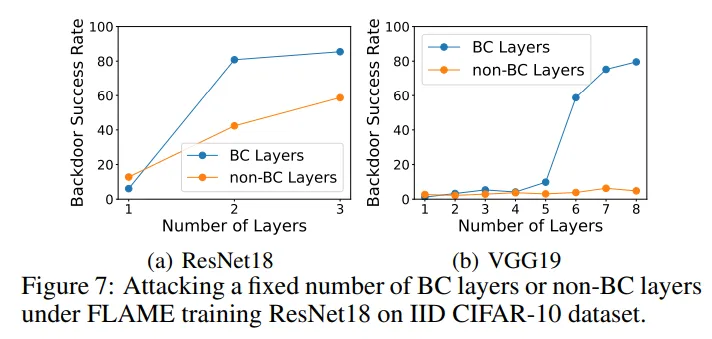
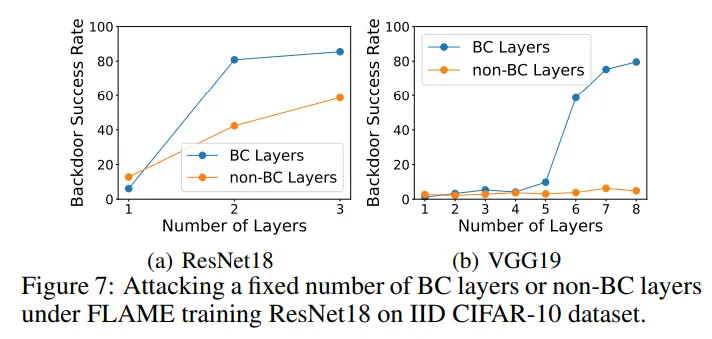
在消融实验中,本文分别对后门关键层和非后门关键层进行投毒并测量两种实验的后门攻击成功率。如下图所示,攻击相同层数的情况下,对非后门关键层进行投毒的成功率远低于对后门关键层进行投毒,这表明本文的算法可以选择出有效的后门攻击关键层。
除此之外,我们对模型聚合模块 Model Averaging 和自适应控制模块 Adaptive Control 进行消融实验。如下表所示,这两个模块均对提升选取率和后门攻击成功率,证明了这两个模块的有效性。
总结
本文发现后门攻击与部分层紧密相关,并提出了一种算法搜寻后门攻击关键层。本文利用后门攻击关键层提出了针对联邦学习中保护算法的基于层的 layer-wise 攻击。所提出的攻击揭示了目前三类防御方法的漏洞,表明未来将需要更加精细的防御算法对联邦学习安全进行保护。
Zhuang Haomin,本科毕业于华南理工大学,曾于路易斯安那州立大学 IntelliSys 实验室担任研究助理,现于圣母大学就读博士。主要研究方向为后门攻击和对抗样本攻击。
文章来自微信公众号“机器之心”,作者:机器之心




