# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
北大团队联合兔展发起的 Sora 复现计划,现在有了新成果。
OpenAI 在今年年初扔出一项重大研究,Sora 将视频生成带入一个新的高度,很多人表示,现在的 OpenAI 一出手就是王炸。然而,众多周知的是,OpenAI 一向并不 Open,关于 Sora 的更多细节我们无从得知。谁能率先发布类 Sora 研究成了一个热门话题。
今年 3 月初,北大团队联合兔展启动了 Sora 复现计划 ——Open Sora Plan,该项目希望通过开源社区的力量复现 Sora。

项目上线一个月,星标量已经达到 6.6k。
现在这个项目终于有了新成果,Open-Sora-Plan v1.0.0 来了,新研究显著增强了视频生成的质量以及对文本的控制能力。研究者表示,他们正在训练更高分辨率(>1024)以及更长时间(>10s)的视频。目前该项目已支持国产 AI 芯片(华为昇腾 910b)进行推理,下一步将支持国产算力训练。
项目作者林彬表示:Open-Sora-Plan v1.0.0 可以生成1024×1024分辨率视频,也能生成10 秒、24 FPS 的高清视频。而且它还能够生成高分辨率图像。
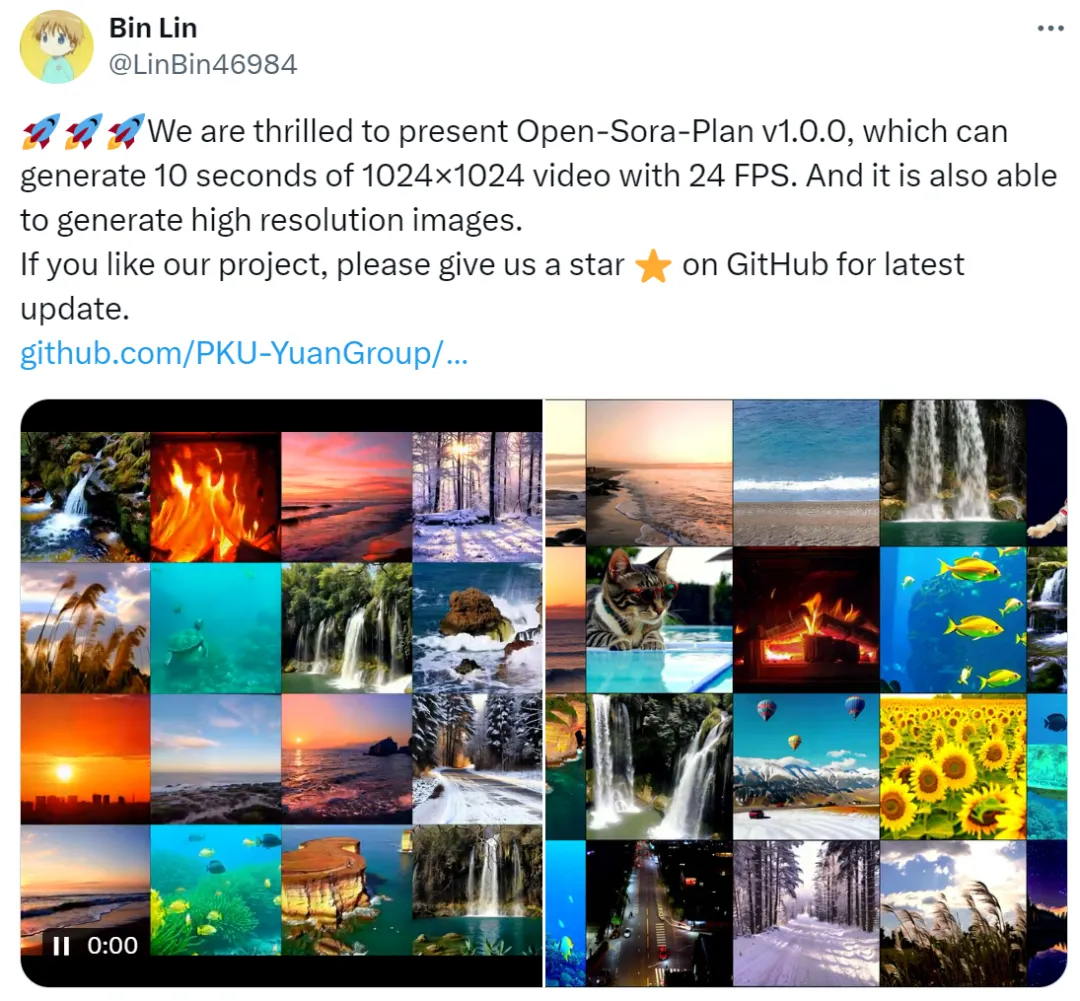
下面我们看一下 v1.0.0 的效果(为了展示,动图进行了一些压缩,会损失一些质量)。
文本到视频生成
提示:海上的日落。

00:10
提示:黎明时分,宁静的海滩,海浪轻轻拍打着海岸,天空被涂上柔和的色调......

00:02
提示:沿海景观从日出到黄昏过渡的延时拍摄……

文本到视频生成的更多效果展示:

00:02
文本到图像生成(512×512 )

视频重建(720×1280)

00:24

00:17
图像重建(1536×1024):

在实现细节方面,通过团队放出的技术报告,我们得知模型架构 CausalVideoVAE 概览图如下所示:
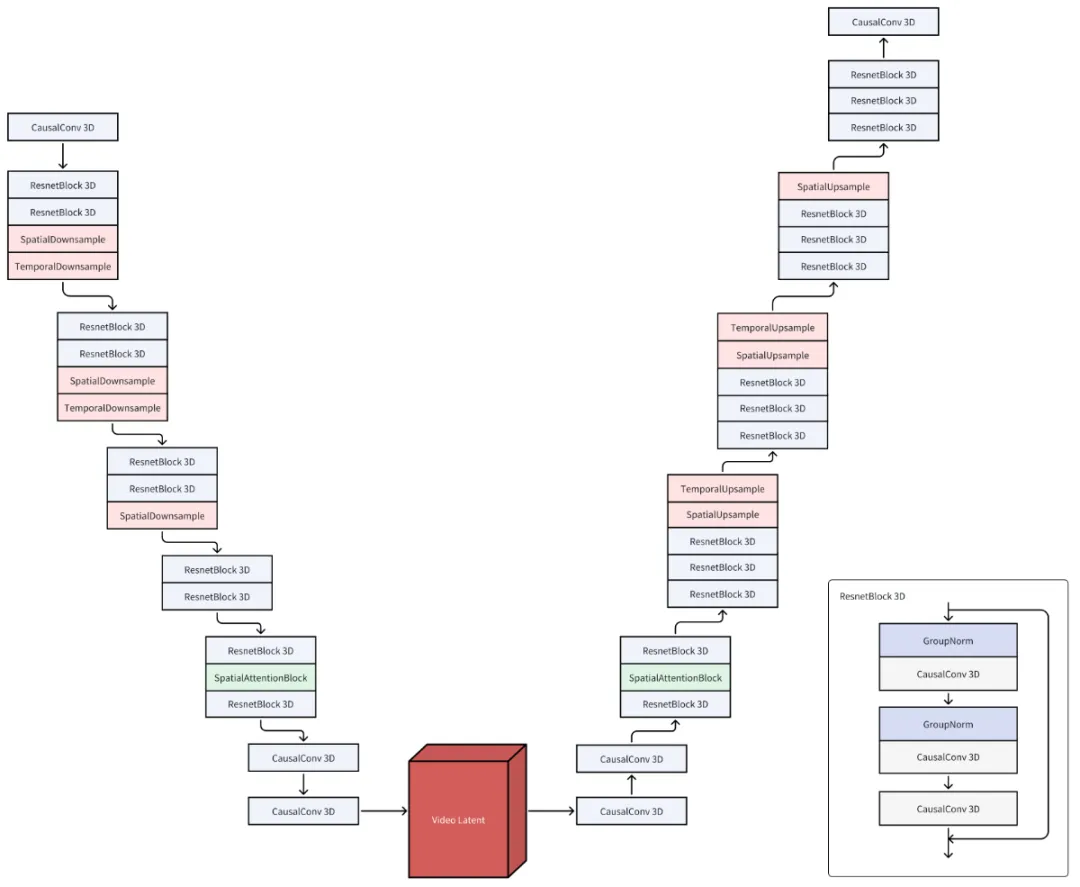
CausalVideoVAE 架构继承自 Stable-Diffusion Image VAE。为了保证 Image VAE 的预训练权重能够无缝应用到 Video VAE 中,模型结构设计如下:
CausalConv3D:将 Conv2D 转换为 CausalConv3D,可以实现图像和视频数据的联合训练。CausalConv3D 对第一帧进行特殊处理,因为它无法访问后续帧。
初始化:Conv2D 扩展到 Conv3D 常用的方法有两种:平均初始化和中心初始化。但本文采用了特定的初始化方法 tail 初始化。这种初始化方法确保模型无需任何训练就能够直接重建图像,甚至视频。
训练细节:
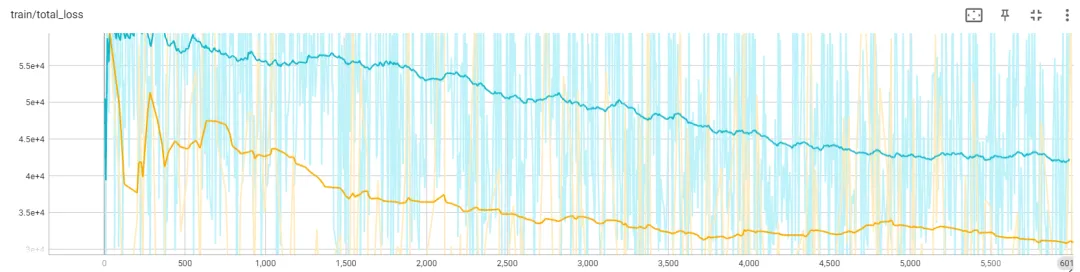
上图展示了 17×256×256 下两种不同初始化方法的损失曲线。黄色曲线代表使用 tail init 损失,而蓝色曲线对应中心初始化损失。如图所示,tail 初始化在损失曲线上表现出更好的性能。此外,该研究发现中心初始化会导致错误累积,导致在长时间内崩溃。
训练扩散模型。与之前的工作类似,该研究采用了多阶段级联训练方法,总共消耗了 2048 A800 GPU 小时。研究发现,图像联合训练显着加速了模型收敛并增强了视觉感知,这与 Latte 的研究结果一致。

不过,目前发布的 CausalVideoVAE(v1.0.0)有两个主要缺点:运动模糊和网格效果。团队正在改进这些缺点,后续版本很快就会上线。
最后附上团队完整名单:




