# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

昨天的谷歌Next大会可是太精彩了,谷歌一连放出不少炸弹。
- 升级「视频版」Imagen 2.0,下场AI视频模型大混战
- 发布时被Sora光环掩盖的Gemini 1.5 Pro,正式开放
- 首款Arm架构CPU发布,全面对垒微软/亚马逊/英伟达/英特尔
此外,谷歌的AI超算平台也进行了一系列重大升级——最强TPU v5p上线、升级软件存储,以及更灵活的消费模式,都让谷歌云在AI领域的竞争力进一步提升。
连放大招的谷歌,必不会在这场AI大战中退让。
在短短两个月内,谷歌一键将多种前沿模型引入Vertex AI,包括自家的Gemini 1.0 Pro、轻量级开源模型Gemma,以及Anthropic的Claude 3。
Gemini 1.5 Pro,人人可用了!
传说中的谷歌最强杀器Gemini 1.5 Pro,已经在Vertex AI上开放公测了!
开发者们终于可以亲自体验到,前所未有的最长上下文窗口是什么感觉。
Gemini 1.5 Pro的100万token,比Claude 3中最大的200K上下文,直接高出了五倍!而GPT-4 Turbo,上下文也只有128K。

当然,超长上下文在无缝处理输入信息方面,仍然有一定的局限性。
但无论如何,它让对大量数据进行本机多模态推理成为可能。从此,多海量的数据,都可以进行全面、多角度的分析。
自然而然地,我们可以正式用Gemini 1.5 Pro开发新的用例了。比如AI驱动的客户服务智能体和在线学术导师,分析复杂的金融文件,发现文档中的遗漏,查询整个代码库,或者自然语言数据集。
现在,已经有无数企业用Gemini 1.5 Pro真实地改变了自己的工作流。
比如,软件供应商思爱普用它来为客户提供与业务相关的AI解决方案;日本广播公司TBS用它实现了大型媒体档案的自动元数据标注,极大提高了资料搜索的效率;初创公司Replit,则用它更高效、更快、更准确地生成、解释和转换代码。
不仅如此,Gemini 1.5 Pro现在还增加了音频功能。
它能处理音频流,包括语音和视频中的音频。
这直接就无缝打破了文本、图像、音频和视频的边界,一键开启多模态文件之间的无缝分析。
在财报电话会议中,一个模型就能对多种媒介进行转录、搜索、分析、提问了。
Imagen 2.0能生视频了:4秒24帧640p
并且,这次谷歌也下场开卷AI模型了!
AI生图工具Imagen,现在可以生成视频了。
只用文本提示,Imagen就能创作出实时的动态图像,帧率为每秒24帧,分辨率达到360x640像素,持续时间为4秒。

谷歌表示,Imagen在处理自然景观、食物图像和动物等主题时,表现尤为出色。
它不仅能够创造出一系列多样的摄影角度和动作,还能确保整个序列的视觉一致性。
同时,这些动态图像也配备了安全过滤和数字水印技术。
并且,谷歌对Imagen 2.0也升级了图像编辑功能,增加了图像修复、扩展、数字水印功能。
想把图中这个男人去掉?一键圈出,他就没了!并且模型还自动补全了山上的背景。

想让远处的山高一点?Imagen 2.0也能轻松做到。

另外,它还可以帮我们扩大图片边缘,获得更广阔的视角。

而数字水印功能,由Google DeepMind的SynthID强力驱动。
这样,用户为就可以图片和视频生成隐形水印,并且验证它们是否由Imagen所生成。
全新代码模型CodeGemma发布,核心团队华人占6成
最新发布轻量级代码生成模型CodeGemma,采用的是与Gemma系列相同的架构,并进一步在超过5000亿个代码Token上进行了训练。
目前, CodeGemma已经全系加入Vertex AI。

论文地址:https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf

具体来说,CodeGemma共有三个模型检查点(Checkpoint):
CodeGemma 7B的预训练版本(PT)和指令微调版本(IT)在理解自然语言方面表现出色,具有出众的数学推理能力,并且在代码生成能力上与其他开源模型不相上下。
CodeGemma 2B则是一个SOTA的代码补全模型,可以进行快速的代码填充和开放式生成。
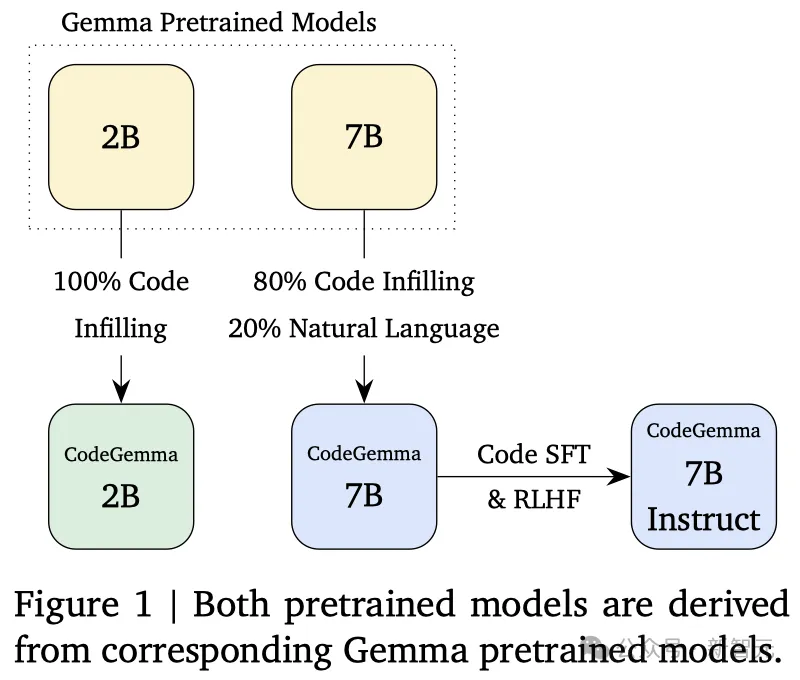
CodeGemma的训练数据包括了来自网络文档、数学和代码的5000亿个Token(主要是英文)。
2B规模的模型完全使用代码进行训练,而7B规模的模型则采用了80%编程代码外加20%自然语言的方式。
为了确保数据的质量,谷歌对数据集进行了去重和过滤,移除了可能影响评估的代码样本和一些个人或敏感信息。
此外,谷歌还对CodeGemma模型的预训练采用了一种改进的中间填空(Fill-in-the-Middle, FIM)方法,以此来提升了模型的训练效果。
具体可以分为两种模式:PSM(前缀-后缀-中间)和SPM(后缀-前缀-中间)。


通过让模型接触各种数学问题,可以提升它在逻辑推理和解决问题方面的能力,这对编写代码来说是非常重要的。
为此,谷歌选用了多个主流的数学数据集进行监督微调,包括:MATH、GSM8k、MathQA,以及合成数学数据。
在代码方面,谷歌采用了合成代码指令的方法来创建数据集,用于后续的监督微调(SFT)和基于人类反馈的强化学习(RLHF)之中。
为了确保生成的代码指令数据既有用又准确,谷歌采取了以下方法:
- 示例生成:根据OSS-Instruct的方法,制作一系列独立的问题与答案对;
- 后期过滤:利用大语言模型来筛选这些问题与答案对,评估它们的实用性和准确性。
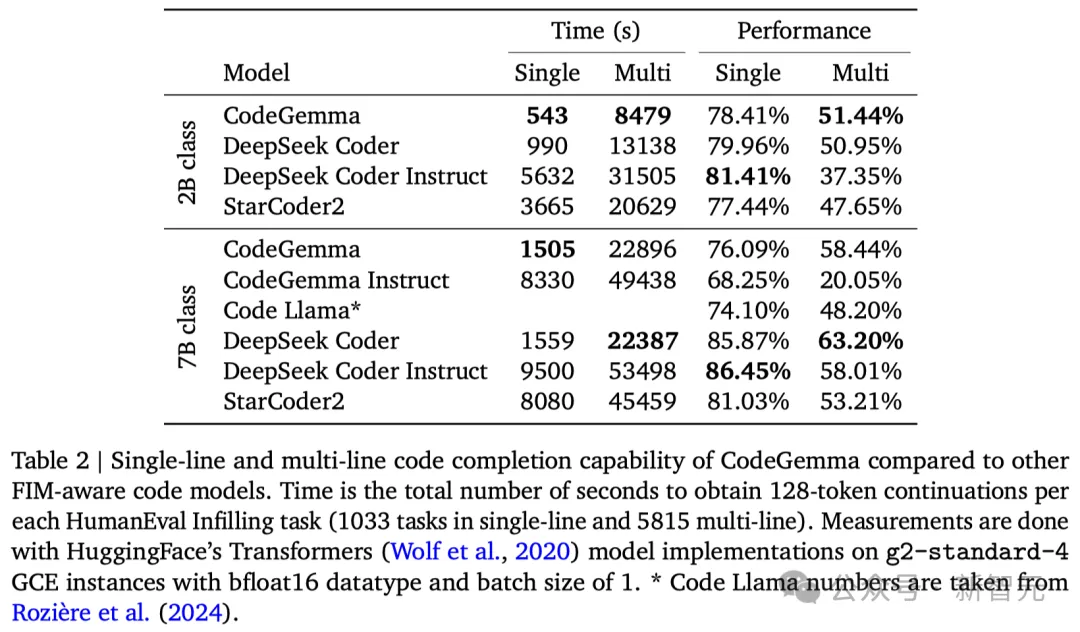
如表2所示,CodeGemma 2B在代码补全场景下展现出了卓越的性能,尤其是在低延迟的表现上。
其中,推理速度更是比不少模型快了有2倍之多。
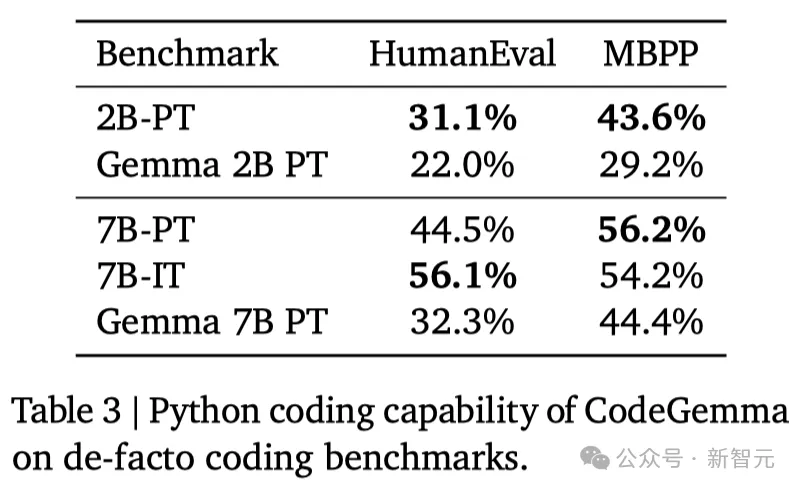
HumanEval和Mostly Basic Python Problems的评估结果如表3所示。
与Gemma基础模型相比,CodeGemma在编程领域的任务上表现明显更强。
BabelCode通常用来评估模型在多种编程语言中的代码生成性能,结果如表4所示。
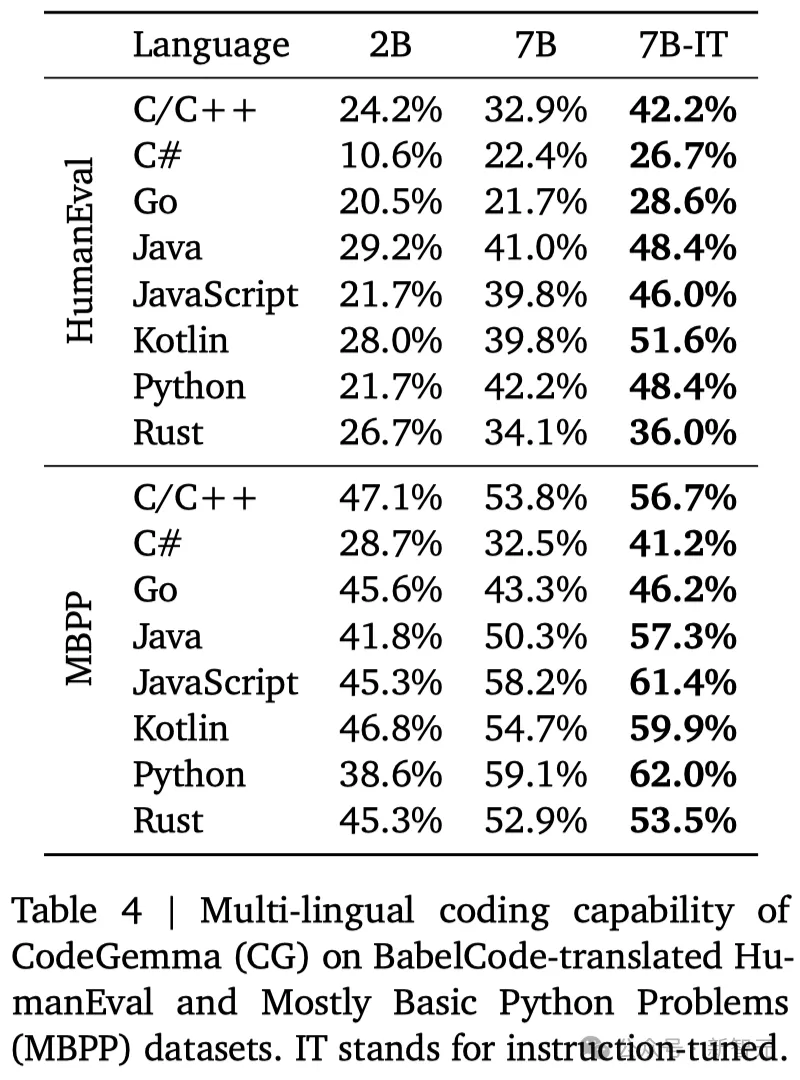
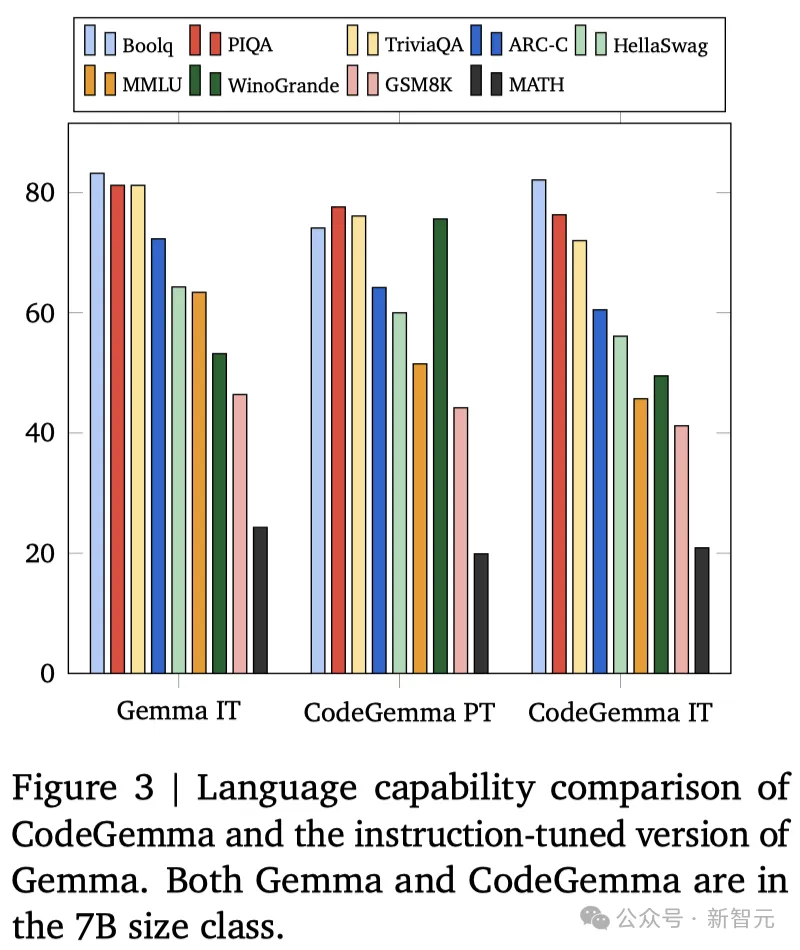
图3展示了多个领域的性能评估结果,包括问答、自然语言处理以及数学推理。
可以看到,CodeGemma同样有着Gemma基础模型的自然语言处理能力,其PT和IT版本在性能上均优于Mistral 7B和Llama2 13B——分别领先了7.2%和19.1%。
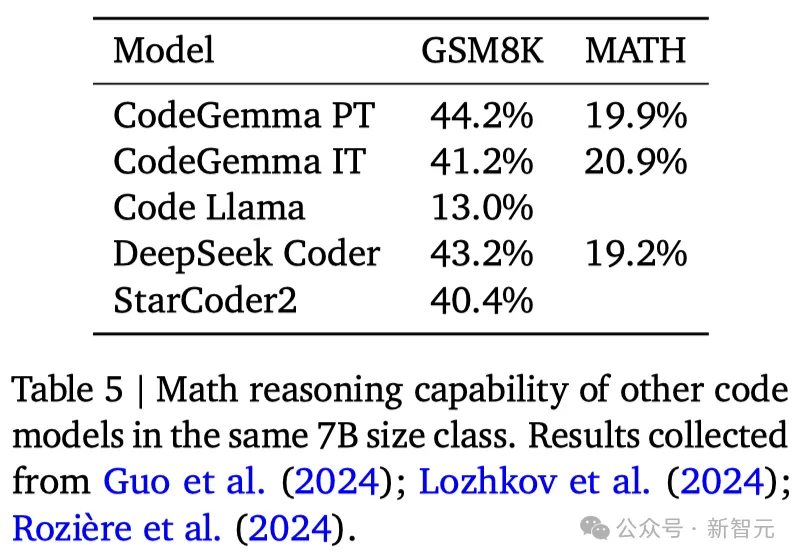
进一步地,如表5所示,CodeGemma在数学推理方面,相比同等规模的模型有着更出色的表现。
如图4所示,在进行代码补全任务时,比如函数补全、注释文档字符串生成或者导入模块建议,应当按照一定的格式来设计输入提示。

官宣自研Arm架构CPU处理器Axion

此次Next大会上,谷歌还正式宣布,将自研首款基于Arm的CPU。
据称这款CPU处理器Axion,将提供比英特尔CPU更好的性能和能源的效率,其中性能提高50%,能源效率提高60%。
据悉,比起目前基于Arm的最快通用芯片,Axion的性能还要高出30%。
凭着这个新武器,谷歌也在AI军备竞赛中,正式向微软和亚马逊宣战!

新CPU Axion,显然是谷歌跟随亚马逊AWS和微软Azure的动作——它也想自研处理器了。
Axion将帮助谷歌提高通用工作负载的性能,比如开源数据库、Web和应用程序服务器、内存缓存、数据分析引擎、媒体处理和AI训练。
由此,谷歌在开发新的计算资源方面,又向前迈进了一步。在今年晚些时候,Axion就可用于云服务了。
对于AI军备竞赛来说,像Axion这样的CPU至关重要,因为它能提升训练AI模型所需的算力。
要训练复杂的AI模型,就需要处理大型数据集,而CPU有助于更快地运行这些数据集。
要说此举的最大的好处,那无疑就是——省钱!
众所周知,购买AI芯片的成本惊人,英伟达的Backwell芯片,预计售价在3万美元到4万美元之间。

现在,Axion芯片已经在为YouTube 广告、Google Earth引擎提供加持了。
而且,很快就可以在谷歌计算引擎、谷歌Kubernetes引擎、Dataproc、Dataflow、Cloud Batch等云服务中使用。
不仅如此,原本在使用Arm的客户,无需重新架构或者重写应用程序就可以轻松地迁移到Axion上来。
TPU v5p上线,与英伟达合作加速AI开发
在此次Google Cloud Next 2024年会上,谷歌宣布:对自家超算平台进行大规模升级!
升级列表中的第一位,就是谷歌云的张量处理单元TPU v5p了。如今,该定制芯片全面向云客户开放。

谷歌的TPU,一直被用作英伟达GPU的替代品,用于AI加速任务。
作为下一代加速器,TPU v5p专门用于训练一些最大、最苛刻的生成式AI模型。其中,单个TPU v5p pod包含8,960个芯片,是TPU v4 pod芯片数量的两倍之多。
另外,谷歌云还将和英伟达合作加速AI开发——推出配备H100的全新A3 Mega VM虚拟机,单芯片搭载高达800亿个晶体管。
而且谷歌云还会将英伟达最新核弹Blackwell整合进产品中,增强对高性能计算和AI工作负载的支持,尤其是以B200和GB200提供支持的虚拟机形式。

其中,B200专为「最苛刻的AI、数据分析和HPC工作负载而设计」。
而配备液冷的GB200,将为万亿参数模型的实时LLM推理和大规模训练提供算力。
虽然现在万亿参数的模型还不多(少量几个选手是SambaNova和谷歌的Switch Transformer),但英伟达和Cerebras都在冲万亿参数模型硬件了。
显然,他们已经预见到,AI模型的规模还会迅速扩大。
在软件方面,谷歌云推出了JetStream,这是一款针对LLM的吞吐量和内存优化了的推理引擎。
这个新工具可以提高开源模型的单位美元性能,并与JAX和PyTorch/XLA框架兼容,从而降本增效。
此外,谷歌的存储解决方案也在不断升级——不仅加速了AI训练和微调,优化了GPU和TPU的使用,还提高了能效和成本效益。
此次,谷歌推出的Hyperdisk ML,显著缩短了模型加载时间,提高了吞吐量,并对AI推理和服务工作负载进行了优化。
不仅支持每个存储卷承载2,500个实例,而且还提供了高达1.2TiB/s的数据吞吐量,性能直接超越微软和AWS。
已发布的Cloud Storage FUSE,可将基础模型的训练吞吐量提高2.9倍,性能提高2.2倍。
高性能并行文件系统Parallelstore可将训练速度提高到3.9倍,并将训练吞吐量提高到3.7倍。
而专为AI模型量身定制的Filestore系统,允许在集群中的所有GPU和TPU之间同时访问数据,将训练时间缩短56%。
总之,此次谷歌超算的大规模更新表明,谷歌在努力为客户带来实际的商业利益,创建无缝集成、高效可扩展的AI训练和推理环境。
参考资料:
https://cloud.google.com/blog/products/ai-machine-learning/google-cloud-gemini-image-2-and-mlops-updates
https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
https://www.businessinsider.com/google-ramped-up-ai-competition-against-microsoft-amazon-2024-4
https://www.theverge.com/2024/4/9/24125074/google-axion-arm-cpu-ai-chips-cloud-server-data-center
https://blogs.nvidia.com/blog/nvidia-google-cloud-ai-development/
https://venturebeat.com/ai/google-upgrades-its-ai-hypercomputer-for-enterprise-use-at-cloud-next/
文章来自微信公众号”新智元“,作者 Aeneas 好困



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
