# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不走Transformer寻常路,魔改RNN的国产新架构RWKV,有了新进展:
提出了两种新的RWKV架构,即Eagle (RWKV-5) 和Finch(RWKV-6)。
这两种序列模型以RWKV-4架构为基础,然后作了改进。
新架构的设计进步包括多头矩阵值状态(multi-headed matrix-valued states)和动态递归机制(dynamic recurrence mechanism),这些改进提高了RWKV模型的表达能力,同时保持RNN的推理效率特征。
同时,新架构引入了一个新的多语言语料库,包含1.12万亿个令牌。
团队还基于贪婪匹配(greedy matching)开发了一种快速的分词器,以增强RWKV的多语言性。
目前,4个Eagle模型和2个Finch模型,都已经在抱抱脸上发布了~
此次更新的RWKV,共包含6个模型,分别是:
4个Eagle(RWKV-5)模型:分别为0.4B、1.5B、3B、7B参数大小;
2个Finch(RWKV-6)模型:分别是1.6B、3B参数大小。
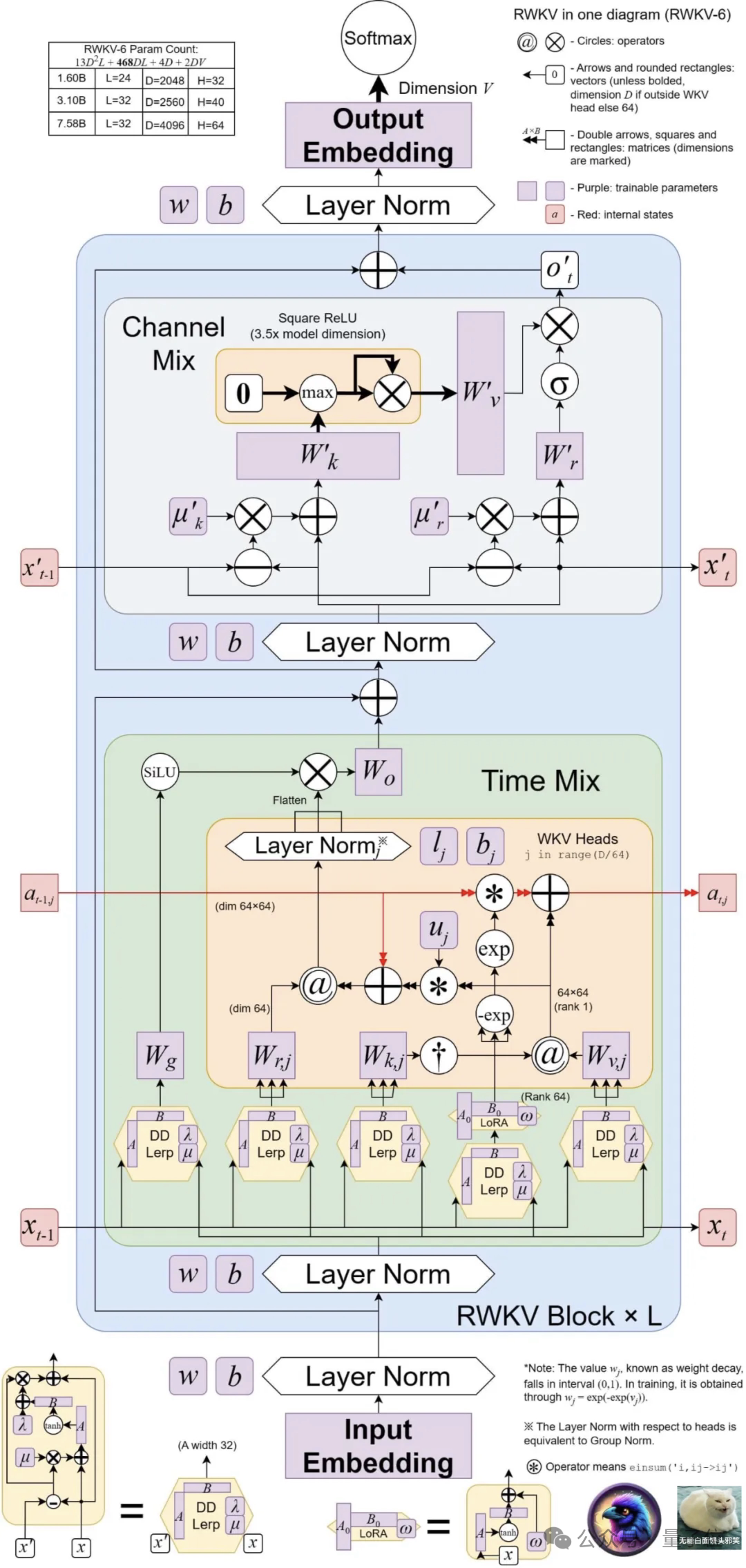
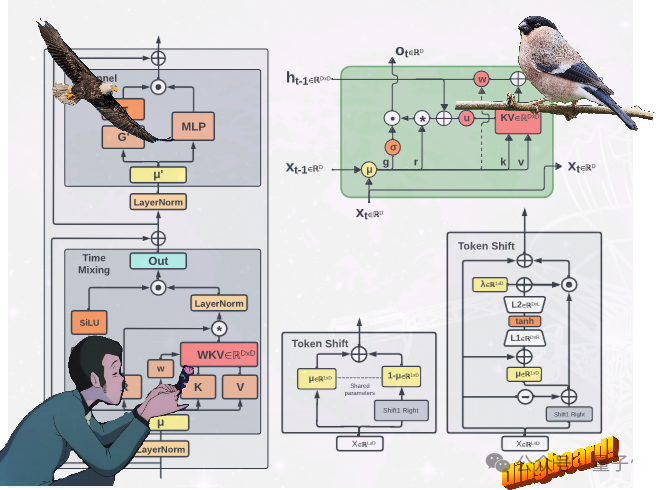
Eagle通过使用多头矩阵值状态(而非向量值状态)、重新构造的接受态和额外的门控机制,改进了从RWKV-4中学习到的架构和学习衰减进度。
Finch则通过引入新的数据相关函数,进一步改进架构的表现能力和灵活性,用于时间混合和令牌移位模块,包括参数化线性插值。
此外,Finch提出了对低秩自适应函数的新用法,以使可训练的权重矩阵能够以一种上下文相关的方式有效地增强学习到的数据衰减向量。
最后,RWKV新架构引入了一种新的分词器RWKV World Tokenizer,和一个新数据集RWKV World v2,两者均用于提高RWKV模型在多语言和代码数据上的性能。
其中的新分词器RWKV World Tokenizer包含不常见语言的词汇,并且通过基于Trie的贪婪匹配(greedy matching)进行快速分词。
而新数据集RWKV World v2是一个新的多语言1.12T tokens数据集,取自各种手工选择的公开可用数据源。
其数据组成中,约70%是英语数据,15%是多语言数据,15%是代码数据。
光有架构创新还不够,关键要看模型的实际表现。
来看看新模型在各大权威评测榜单上的成绩——
MQAR (Multiple Query Associative Recall)任务是一种用于评估语言模型的任务,旨在测试模型在多次查询情况下的联想记忆能力。
在这类任务中,模型需要通过给定的多个查询来检索相关的信息。
MQAR任务的目标是衡量模型在多次查询下检索信息的能力,以及其对不同查询的适应性和准确性。
下图为RWKV-4、Eagle、 Finch和其他非Transformer架构的MQAR任务测试结果。
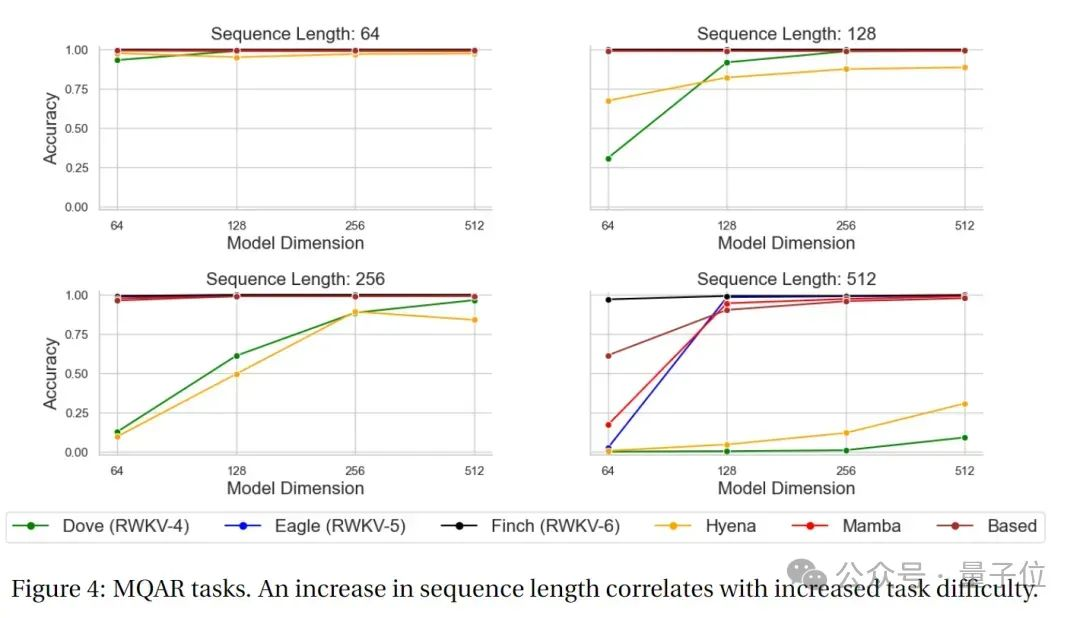
可以看出,在MQAR任务的准确度测试中, Finch在多种序列长度测试中的准确度表现都非常稳定,对比RWKV-4、RWKV-5和其他非Transformer架构的模型有显著的性能优势。
在PG19测试集上测试了从2048 tokens开始的RWKV-4、Eagle和Finch的loss与序列位置。
(所有模型均基于上下文长度4096进行预训练)。
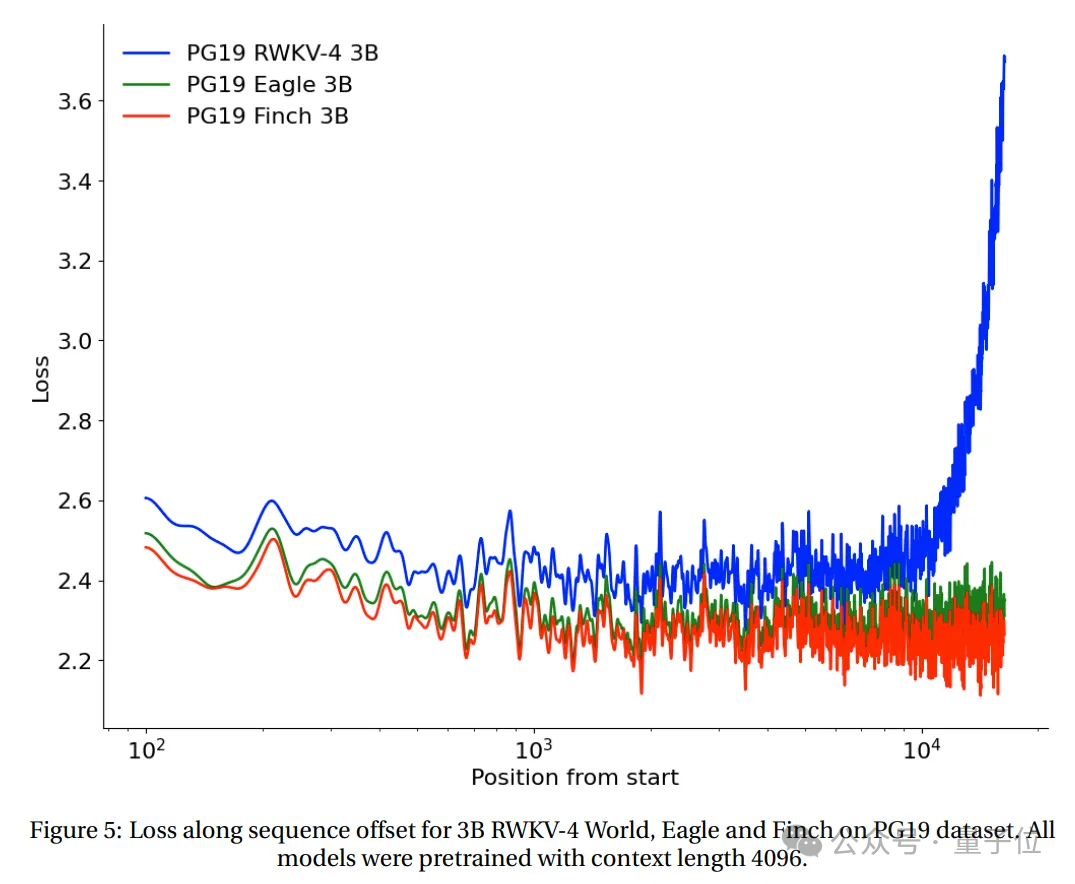
测试结果显示, Eagle在长序列任务上比RWKV-4有了显著的改进,而在上下文长度4096训练的Finch的表现比Eagle更好,可以良好地自动适应到20000以上的上下文长度。
速度和内存基准测试中,团队比较了Finch、Mamba和Flash Attention的类Attention内核的速度和显存利用率。

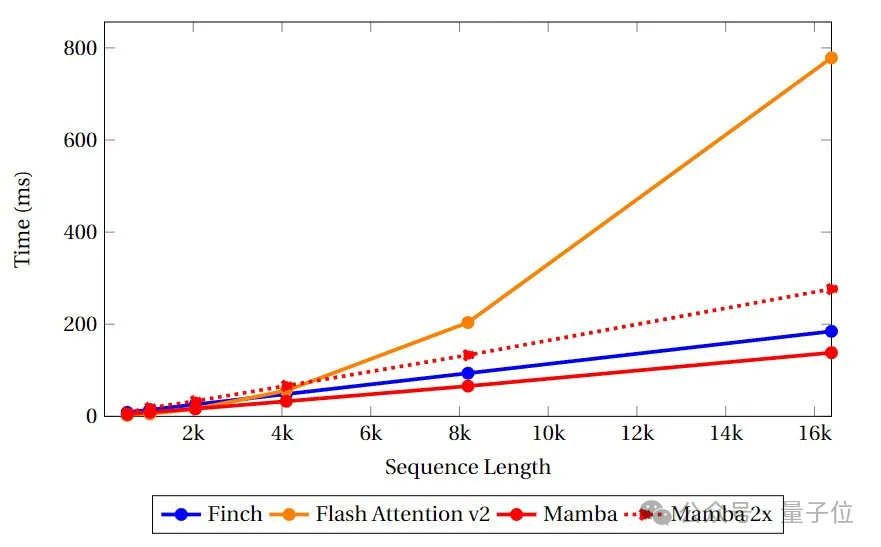
可以看到,Finch在内存使用方面始终优于Mamba和Flash Attention,而内存使用量分别比Flash Attention和Mamba少40%和17%。




以上研究内容,来自RWKV Foundation发布的最新论文《Eagle and Finch:RWKV with Matrix-Valued States and Dynamic Recurrence》。
论文由RWKV创始人Bo PENG(彭博)和RWKV开源社区成员共同完成。

共同一作彭博,毕业于香港大学物理系,编程经验20+年,曾在世界最大外汇对冲基金之一Ortus Capital就职,负责高频量化交易。
还出版过一本关于深度卷积网络的书籍《深度卷积网络·原理与实践》。
他的主要关注和兴趣方向在软硬件开发方面,在此前的公开访谈中,他曾明确表示AIGC是自己的兴趣所在,尤其是小说生成。
目前,彭博在Github有2.1k的followers。
但他的最主要公开身份是一家灯具公司禀临科技的联合创始人,主要是做阳光灯、吸顶灯、便携台灯什么的。
并且其人应该是一个喵星人资深爱好者,Github、知乎、微信头像,以及灯具公司的官网首页、微博上,都有一只橘猫的身影。
量子位获悉,RWKV当前的多模态工作包含RWKV Music(音乐方向)和 VisualRWKV(图像方向)。
接下来,RWKV的重点工作将放在以下几个方向:
论文链接:
https://arxiv.org/pdf/2404.05892.pdf



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
