# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在深度学习时代,联邦学习(FL)提供了一种分布式的协作学习的方法,允许多机构数据所有者或客户在不泄漏数据隐私的情况下协作训练机器学习模型。然而,大多数现有的 FL 方法依赖于集中式服务器进行全局模型聚合,从而导致单点故障。这使得系统在与不诚实的客户打交道时容易受到恶意攻击。本文中,FLock 系统采用了点对点投票机制和奖励与削减机制,这些机制由链上智能合约提供支持,以检测和阻止恶意行为。FLock 理论和实证分析都证明了所提出方法的有效性,表明该框架对于恶意客户端行为具有鲁棒性。
现今,机器学习(ML),更具体地说,深度学习已经改变了从金融到医疗等广泛的行业。在当前的 ML 范式中,训练数据首先被收集和策划,然后通过最小化训练数据上的某些损失标准来优化 ML 模型。学习环境中的一个共同基本假设是训练数据可以立即访问或轻松地跨计算节点分发,即数据是
「集中式」的。
然而,在一个拥有多个「客户端」(即数据持有者)的系统中,为了确保数据集中化,客户端必须将本地数据上传到一个集中设备(例如中心服务器)以进行上述的集中式训练。尽管集中式训练在各种深度学习应用中取得了成功,但对数据隐私和安全的担忧日益增长,特别是当客户端持有的本地数
据是私有的或包含敏感信息时。
联邦学习(FL)可以解决训练数据隐私的问题。在一个典型的 FL 系统中,一个中心服务器负责聚合和同步模型权重,而一组客户端操纵多站点数据。这促进了数据治理,因为客户端仅与中心服务器交换模型权重或梯度,而不是将本地数据上传到中心服务器,并且已经使 FL 成为利用多站点数据同
时保护隐私的标准化解决方案。
然而,现有的 FL 大多不能保证来自客户端的上传模型更新的质量。例如,我们可以将恶意行为定义为通过投毒攻击故意降低全局模型学习性能(例如准确性和收敛性)的行为。攻击者可以通过操纵客户端破坏 FL 系统,而不是黑进中心服务器。这项工作专注于防御客户端投毒攻击。
一种解决方案是将 FL 与如全同态加密(FHE)和安全多方计算(SMPC)等复杂的密码协议相结合,以减轻客户端的恶意行为。然而,采用这些复杂的密码协议为 FL 参与者引入了显著的计算开销,从而损害了系统性能。
FLock.io 公司及其合作研究者们(上海人工智能实验室 Nanqing Dong 教授、帝国理工大学 zhipeng Wang 博士、帝国理工大学 William Knoettenbelt 教授及卡内基梅隆大学 Eric Xing 教授)通过提出一种基于区块链和分布式账本技术的安全可靠的 FL 系统框架来解决传统联邦学习(FL)依赖于集中
式服务器进行全局模型聚合,从而导致单点故障这个问题,并将此系统设计命名为 FLock。
在该研究中,团队借助区块链、智能合约和代币经济学设计一种可以抵抗恶意节点攻击(尤其是投毒攻击)的 FL 框架。该工作的成果近期被 IEEE Transactions on Artificial Intelligence (TAI) 接收。

方法介绍
灵感来源
FLock 的机制设计受到了证明权益(PoS)区块链共识机制和桌面游戏《The Resistance》(一种角色扮演类游戏,该游戏的一个变种叫阿瓦隆)的启发。
PoS 要求参与者通过奖励诚实行为并通过削减权益来惩罚不诚实行为,鼓励诚实行为。例如,在以太坊上,希望参与验证区块并识别链头的节点运营商将以太币存入以太坊上的智能合约中。某位验证者从总验证者池中随机选择作为区块提出者提出新区块, 其他验证者则检查新区块并证明它们是否
有效。如果验证者未能完成其中相应的任务,他们就即会受到惩罚或削减;诚实节点则会收到奖励。
《The Resistance》游戏则通过投票机制,每轮游戏中玩家独立推理并投票,从而实现全局共识。《The Resistance》有两个不匹配的竞争方,其中较大的一方被称为抵抗力量,另一方被称为间谍。在《The Resistance》中,有一个投票机制,在每一轮中,每个玩家进行独立推理并为一个玩家投
票,得票最多的玩家将被视为「间谍」并被踢出游戏。抵抗力量的目标是投票淘汰所有间谍,而间谍的目标是冒充抵抗力量并生存到最后。
整体设计
基于 PoS 和《The Resistance》的启发,FLock 提出了一个新颖的基于区块链的 FL 全局聚合的多数投票机制,其中每个 FL 参与客户端独立验证聚合本地更新的质量,并为全局更新的接受度投票。参与者需要抵押资产或代币。
每一轮 FL 训练中,参与者将被随机选中参与两种类型的行动,提议(上传本地更新)和投票。聚合者(可以是区块链矿工或者其他 FL 链下聚合者)将对收到的本地更新进行聚合从而得到全局聚合。如果大多数投票接受全局聚合,提议者将退还其抵押的代币,而投票接受的投票者不仅会退还,而
且还会获得投票拒绝的投票者的抵押代币的奖励,反之亦然。
基于股权基础聚合机制的整体设计如下图所示。
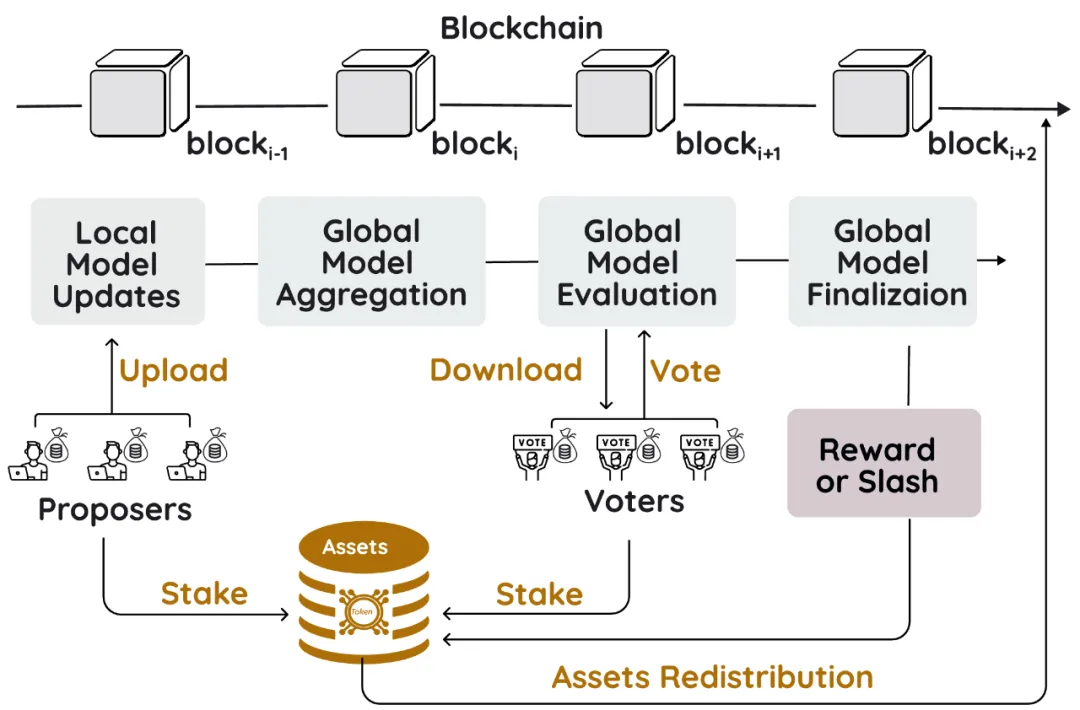
算法细节如下所示:

该算法的最终目标是让恶意参与者的长期平均收益为负值,进而使其抵押代币削减到低于某个允许阈值,从而被提出 FL 系统。
实验结果
FLock 的实验在 Kaggle Lending Club 数据集和 ChestX-ray14 数据集上显示分析了该方案的可行性和鲁棒性,包括:
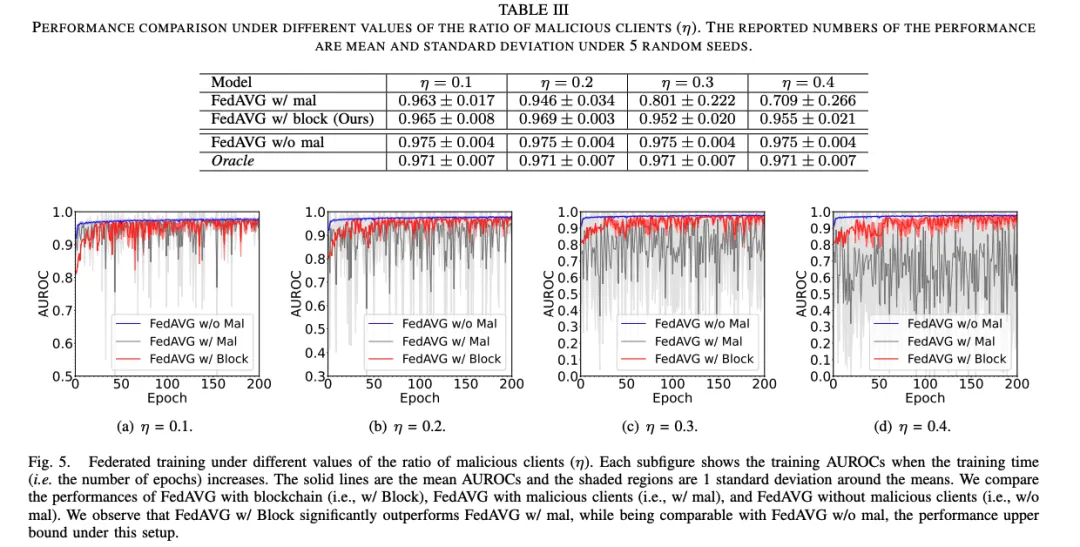
与传统 FL 相比,FLock 抵抗恶意节点的能力:如下图所示,FLock (即 FedAVG w/block)在有恶意节点的情况下仍然保持了稳健的性能。
恶意参与者的抵押代币变化:同理论分析一致,恶意参与者的平均代币随着训练轮数 / 时间的增加而减少。并且,如果惩罚力度增大(即 \gamma 增大),则恶意参与者的平均代币的减少速度将会增大。
诚实参与者的抵押代币变化:相对应的,诚实参与者的平均代币随着训练轮数 / 时间的增加而增加。并且,如果惩罚力度增大大(即 \gamma 增大),则诚实参与者的平均代币的增加速度将会增大。
恶意参与者的存活时间:恶意参与者的存活时间将会随着惩罚力度增大而缩短。
诚实参与者的存活时间:FLock 的实验结果也指出,在恶意节点占比较多的时候(即 \eta 增大时),较大的惩罚力度也会造成部分诚实节点的存活时间缩短(因为每一轮的提议者和投票者是随机选取的)。因此,在实际应用中,要结合考虑恶意节点占比(即 \eta)设置惩罚力度(即 \gamma)。
总结与展望
FLock 提出了一种基于区块链、智能合约和代币经济学的可以抵恶意节点攻击的 FL 框架。该方案论证了区块链和 FL 结合的可行性,证明了区块链不仅可以在去中心化和激励参与者在金融和医学等领域的现实世界中的 FL 应用中发挥重要作用,而且还可以用来防御投毒攻击。
FLock 的方案已被进一步落地实现:https://www.flock.io/
团队将于近期推出首个版本的去中心化 AI 模型训练平台,基建包括了激励体系,联邦学习和一键微调脚本。平台将主要面向两类人群:Developer:欢迎各位 Kaggle 及 Huggingface 玩家早期入驻,完成模型训练与验证以获得激励;Task Creator:有模型训练或者微调需求的公司或者团队可以在
FLock平台上发布任务,FLock提供基建组织开发者,从而省去组建AI团队,寻找用户基础与数据的复杂过程,并简化工作流。有兴趣请邮件 FLock 团队:hello@flock.io
研究方面,FLock 也正在探索更加多维度的 decentralized AI 安全解决方案,如借助零知识证明解决 FL 中心节点作恶的问题。
研究地址:https://arxiv.org/pdf/2310.02554.pdf
Let's wait for more decentralized AI solutions from FLock!
与此同时,FLock.io 公司致力于将此技术投入到工程实践,也于最近官宣种子轮六百万美元的融资,由 Lightspeed Faction(光速美国)领投。
文章来自微信公众号“机器之心”,作者:机器之心编辑部




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
