国产模型,打平了Claude Fable 5!已上线OpenRouter
国产模型,打平了Claude Fable 5!已上线OpenRouterOpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。
来自主题: AI资讯
8976 点击 2026-06-15 15:13
 搜索
搜索
OpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。
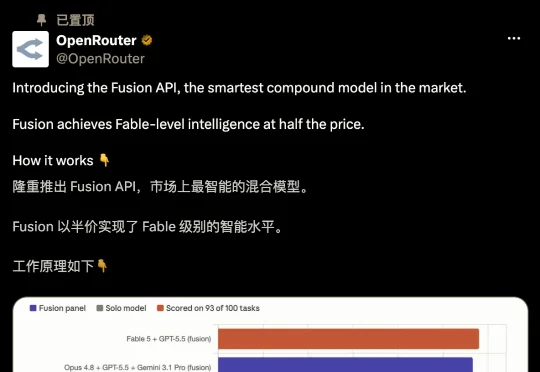
AI网关OrcaRouter最近上线了一套可编程路由策略Routing DSL,多个模型同时答题,自动仲裁出最优解。几个你现在就能调用的“常规模型”,给它来个组合编排,跑出来的综合胜率,直接掀翻了Fable 5的单体基准线。Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个拼一组,结果就反超了。

刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。

过去很长一段时间里,AI 行业衡量模型进步的方式都相当直观:参数更大、榜单更高、推理更强、上下文更长。每一次模型发布,行业都会盯着数学、代码、知识问答和多模态基准测试,看它是否又向通用智能迈近了一步。
如果你在三年前问AI圈:未来最强的AI长什么样?

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴
被ICML 2026接收为Spotlight!

世界杯已经开打了,相信在做有很多朋友抄起了手里的大模型,遛一遛是鸭是鹅
好家伙,这次不是模型圈自嗨。