# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
简介
我们推出 MiniCPM 系列的最新多模态版本 MiniCPM-V 2.0。该模型基于 MiniCPM 2.4B 和 SigLip-400M 构建,共拥有 2.8B 参数。MiniCPM-V 2.0 具有领先的光学字符识别(OCR)和多模态理解能力。该模型在综合性 OCR 能力评测基准 OCRBench 上达到开源模型最佳水平,甚至在场景文字理解方面实现接近 Gemini Pro 的性能。
MiniCPM-V 2.0 值得关注的特性包括:
全面测评
我们将 MiniCPM-V 2.0 与包括 Qwen-VL-Chat 10B、DeepSeek-VL-7B 和 CogVLM-Chat 17B 在内的几款前沿多模态大模型进行了比较,发现即便与参数规模更大的多模态大模型相比,MiniCPM-V 2.0 也展现出了优秀的性能。
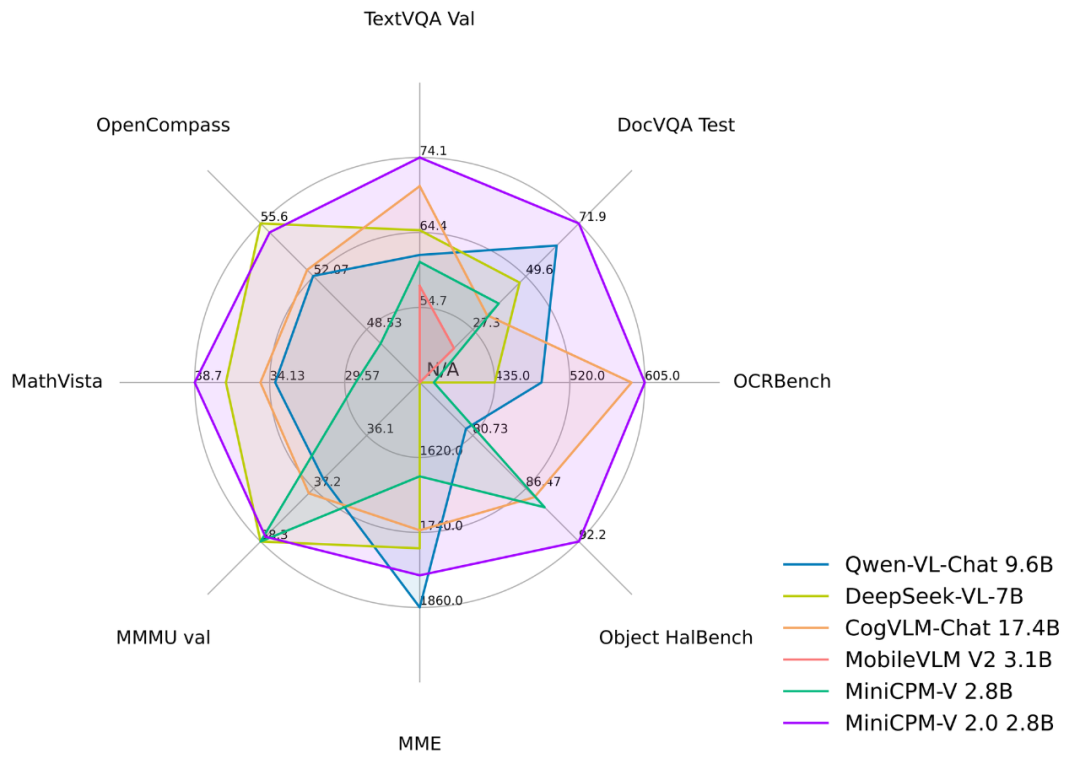
MiniCPM-V 2.0 在多个评测基准上与其他模型得分的雷达图
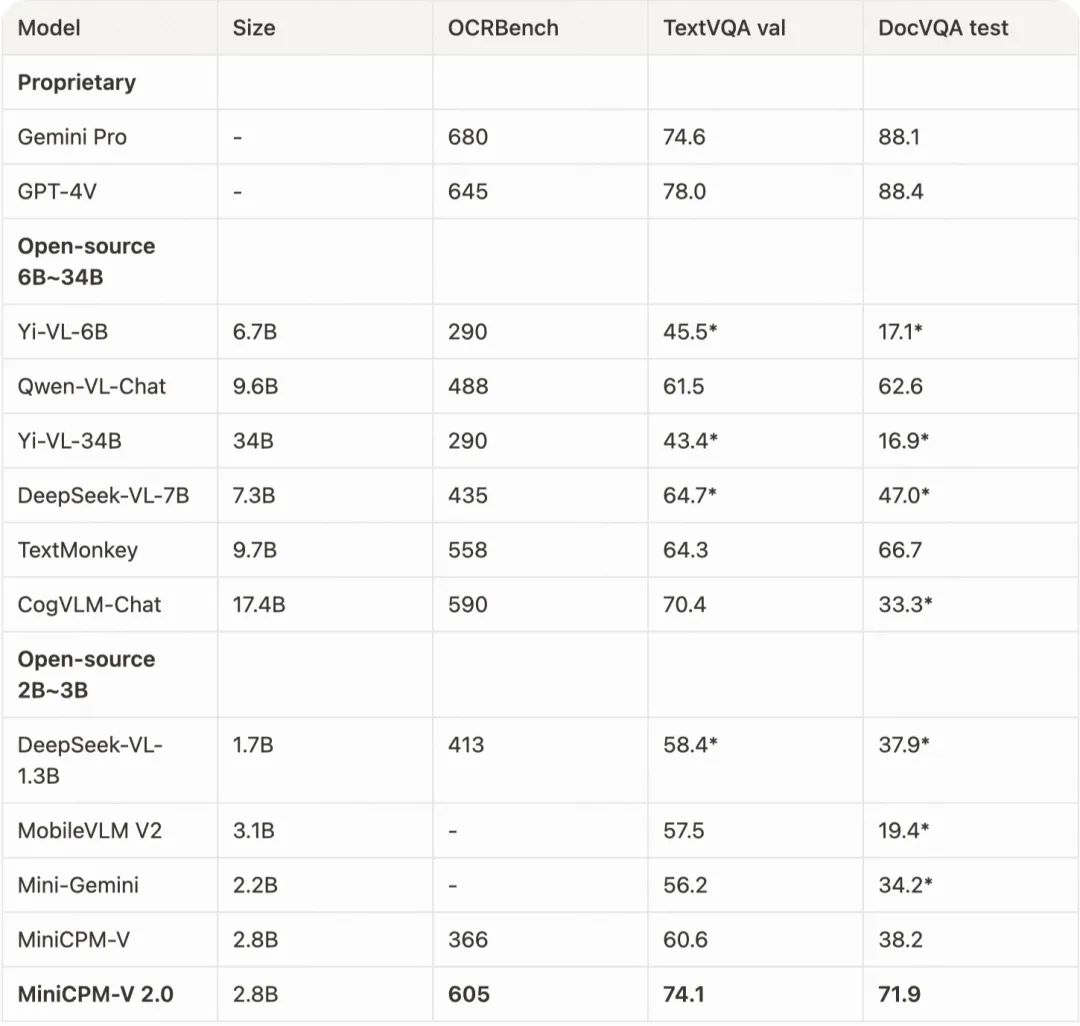
多个OCR评测基准上MiniCPM-V 2.0与其他模型的得分、参数
MiniCPM-V 2.0 拥有优秀的场景文字和文档理解能力。在涵盖了多个领域和任务的综合性 OCR 评测基准 OCRBench 上,MiniCPM-V 2.0 取得了开源模型中最先进的性能。同时,在主流通用场景文字理解评测基准 TextVQA 上,MiniCPM-V 2.0 的表现甚至与 Gemini Pro 相当。
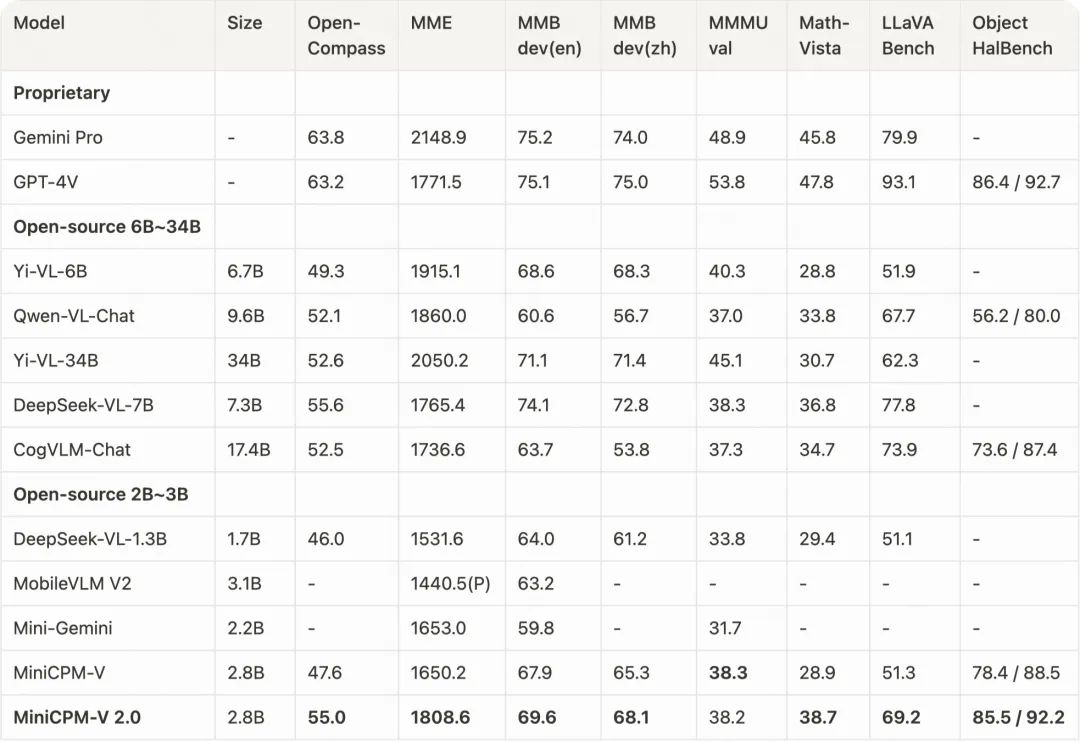
MiniCPM-V 2.0在主流多模态通用能力评测基准的得分
为了考察通用多模态理解能力,我们评测了 MiniCPM-V 2.0 在 OpenCompass 的表现。OpenCompass 是一个综合性评测榜单,涵盖了 11 个主流多模态大模型评测基准,包括 MME、MMBench、MMMU、MathVista 和 LLaVA Bench 等。
在小于 7B 参数的模型中,MiniCPM-V 2.0 取得了最佳性能表现,甚至在 OpenCompass 上超越了强大的 Qwen-VL-Chat 10B、CogVLM-Chat 17B 和 Yi-VL 34B。同时,MiniCPM-V 2.0 在 Object HalBench 上的表现与 GPT-4V 相当,具有出色的幻觉抵抗效果。
推理示例
MiniCPM-V 2.0 可以被部署在大多数的消费级显卡、MPS (Apple silicon 或 AMD 显卡) 的 Mac 电脑以及安卓或者鸿蒙系统手机上。
from chat import OmniLMMChat, img2base64
chat_model = OmniLMMChat('openbmb/MiniCPM-V-2.0')
im_64 = img2base64('./assets/hk_OCR.jpg')
# First round chat
msgs = [{"role": "user", "content": "Where should I go to buy a camera?"}]
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
# Second round chat
# pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": answer})
msgs.append({"role": "user", "content": "Where is this store in the image?"})
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
MPS (Apple silicon 或 AMD 显卡) Mac 电脑部署示例
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.to(device='mps', dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True)
model.eval()
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]
answer, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True
)
print(answer)
使用以下命令运行:
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
参考下方链接的教程进行部署 ????。
???? https://github.com/OpenBMB/mlc-MiniCPM
总结
我们开源了 MiniCPM-V 2.0。作为 MiniCPM 系列最新的多模态大模型,该模型具有强大的 OCR 识别和多模态理解能力,表现了出可信的行为、任意长宽比高清图像感知、良好的推理效率以及双语支持。我们希望此次发布能够促进社区对端侧多模态大模型的探索。
引用
1. MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies. 2024.
2. RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback. CVPR 2024.
3. LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images. 2024.
4. Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages. ICLR 2024.
文章来自微信公众号“OpenBMB开源社区”,作者:姚远*、余天予、王崇屹、崔竣博、朱宏吉、蔡天驰、赵威霖、张开活、洪亦歆、李好雨、胡声鼎、郑直、周界、蔡杰、贾超、韩旭、曾国洋、李大海、刘知远*、孙茂松



