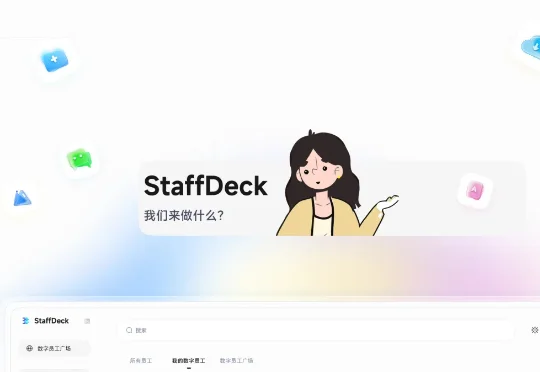
面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效
面壁智能发布数字员工全流程构建平台StaffDeck,给AI发工号、定岗位、做绩效为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。
来自主题: AI资讯
8167 点击 2026-07-18 10:51
 搜索
搜索
为了解决当前AI Agent存在的这些问题,面壁智能联合东北大学-面壁智能数据智能联合实验室、清华大学THUNLP实验室、OpenBMB与AI9Stars,正式开源了数字员工全流程构建与管理平台——StaffDeck。

端侧AI持证上岗了。

投资界从知情人士处获悉,面壁智能已完成新一轮融资,投资方包括国家级基金、央企、汽车制造商等各类产业方、知名财务投资人等。至此,面壁智能2026上半年累计融资金额超50亿元,估值超200亿,一跃成为端侧智能领域公开估值最大的独角兽企业。
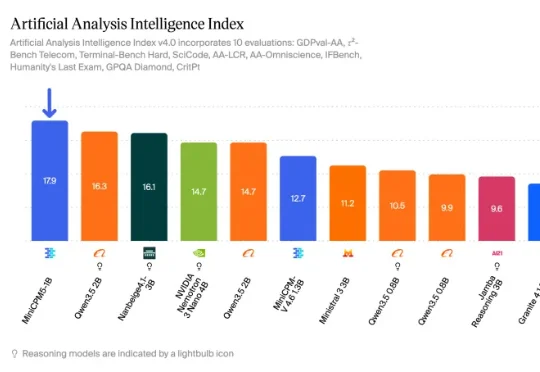
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。
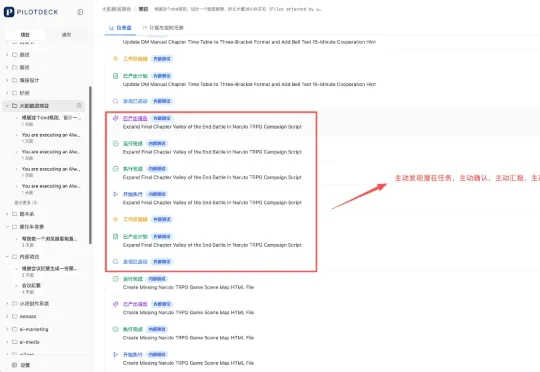
收到面壁智能的内测邀请,我翻了翻产品逻辑,发现它想解决的问题和我当时的处境一模一样。AI 能不能不只是回消息,而是做项目。AI 能不能记住规则,能在你睡觉的时候继续干活,能自己发现你漏了什么。

刚刚,清华团队开源硬核Agent系统PilotDeck,在开发者圈已经传疯了。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团!
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。

造AI这件事,现在的主角变成了AI。

一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。

刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑