
清华系团队出手!一张 4090 即可「爆改」,1.3B小钢炮震撼开源
清华系团队出手!一张 4090 即可「爆改」,1.3B小钢炮震撼开源端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。
来自主题: AI技术研报
9579 点击 2026-05-13 15:24
 搜索
搜索
端侧多模态,卷出新天花板。仅1.3B,性能反超,效率翻倍,一张4090就能「爆改」。刚刚,清华系团队面壁智能开源了新一代「小钢炮」MiniCPM-V 4.6,再次证明了在端侧AI领域,中国团队已然站在世界前沿。
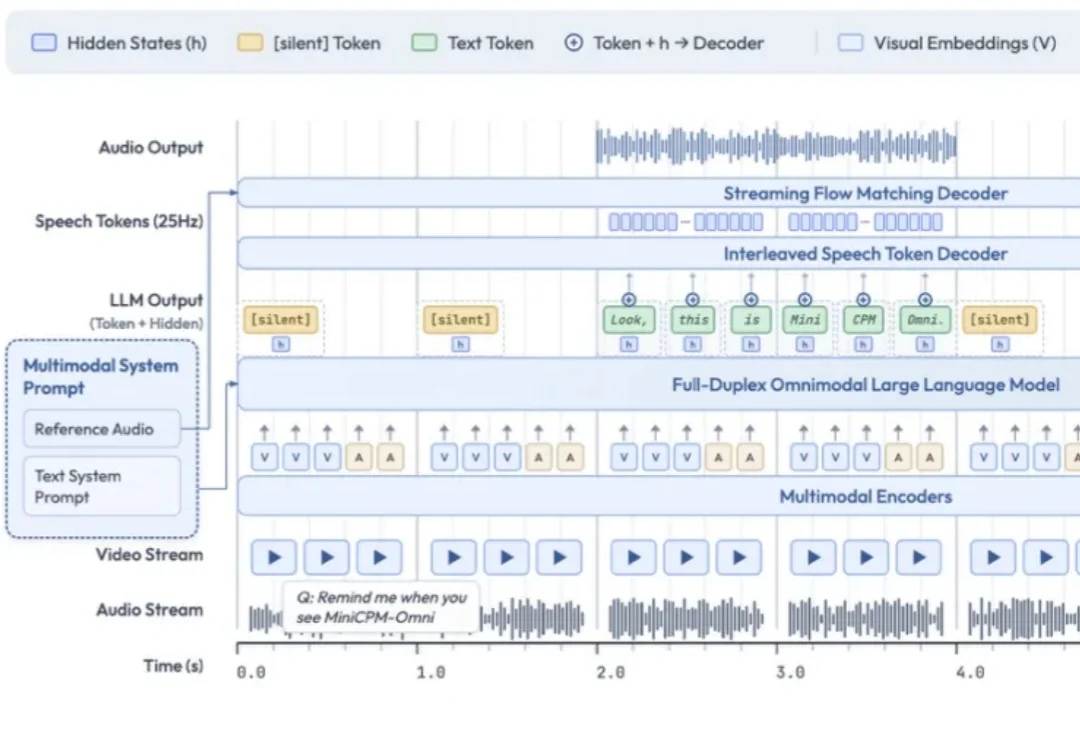
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。

OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究

面壁智能2B小模型VoxCPM 2惊艳开源,一众外国网友疯狂了!30种语言与9大方言它是信手拈来,复刻的贺炜激昂解说与徐志胜脱口秀,相似度简直直击灵魂。这哪是工具,分明是降维打击的生产力核武器!
面壁智能宣布完成新一轮数亿元人民币融资。本轮由深圳市创新投资集团(深创投)和汇川产投联合领投,道禾长期投资、国泰君安创新投、武岳峰科创等跟投。
把Agent接入工作流,本该是件提效的乐事。

面壁智能为你单独造了个“养虾池”,把数据、模型、“龙虾”都留在本地。

为了 OPC 设计的开源“龙虾”架构,要安全,更要有用。
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
空气炸锅“叮”了一声。