# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
啊?是不是看花眼了?
最近 AI 圈里又闹出一个大新闻,《斯坦福团队抄袭中国 AI! 》
估计刚看到这个标题,很多人跟世超一样都蒙了。啊?是不是看花眼了?
哪个斯坦福?确定没搞反?


您猜怎么着,这还真就是 QS 排名前五的那个美国斯坦福。
别说国内网友,业内大佬也绷不住,直呼时代变了。
确切的说,应该是斯坦福的一个本科生团队,抄了清华博士创业公司的产品,也就是面壁智能的开源模型:MiniCPM-Llama3-V 2.5小钢炮。
事儿要从 5 月 29 号说起。
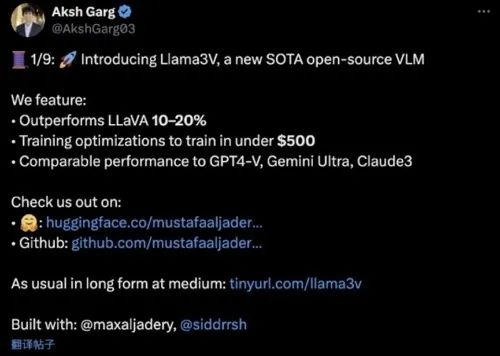
这天有两个斯坦福的印度年轻人,一个还跟佛祖( Siddharth 悉达多 )同名,在在世界上最大 ai 开源社区——HuggingFace上发布了他们的大模型 Llama-3-V 。
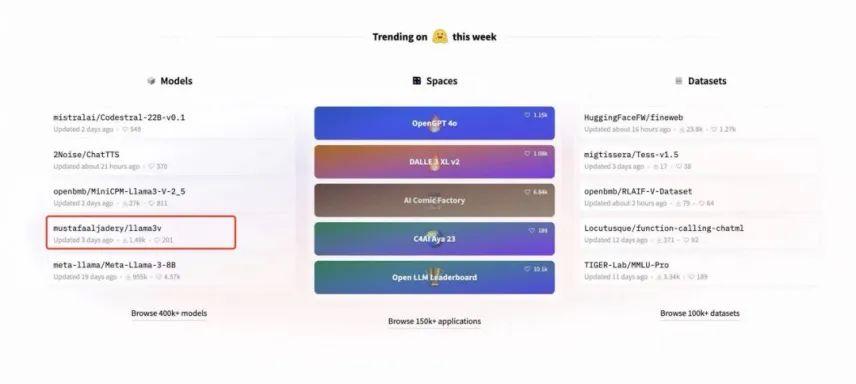
看着他们光鲜亮丽的实习简历,又是特斯拉又是 SpaceX 的,很快,网友们就把这个号称 “500 刀就能练成比肩 GPT-4V 、 Gemini Ultra” 的后起之秀,顶上了 HuggingFace首页,推文浏览量也超过 30 万。
刚开始可能还有人觉着:我大美利坚江山代有才人出啊,你看看,本科生就能做出比肩大厂的成绩,什么叫世界一流啊~
很快,一些眼尖的业内人士发现不对劲了,你这玩意怎么看着跟21 号那个 MiniCPM 小钢炮差不多,不会是抄的吧,咋不标注来源?
之所以人家一眼丁真鉴定为抄,主要是它宣称的体积小、性能强、多模态的特点,很难不让人把它和清华的 MiniCPM 对比。
但他又申明自己是原创的,没引用人家 MiniCPM 。
不过面对别人的指责,这大学生团队还嘴硬,说 MiniCPM 是引用了 LLaVA-UHD 的,我们也引的这个,读书人的事,那能叫抄吗?真是装糊涂的天才。
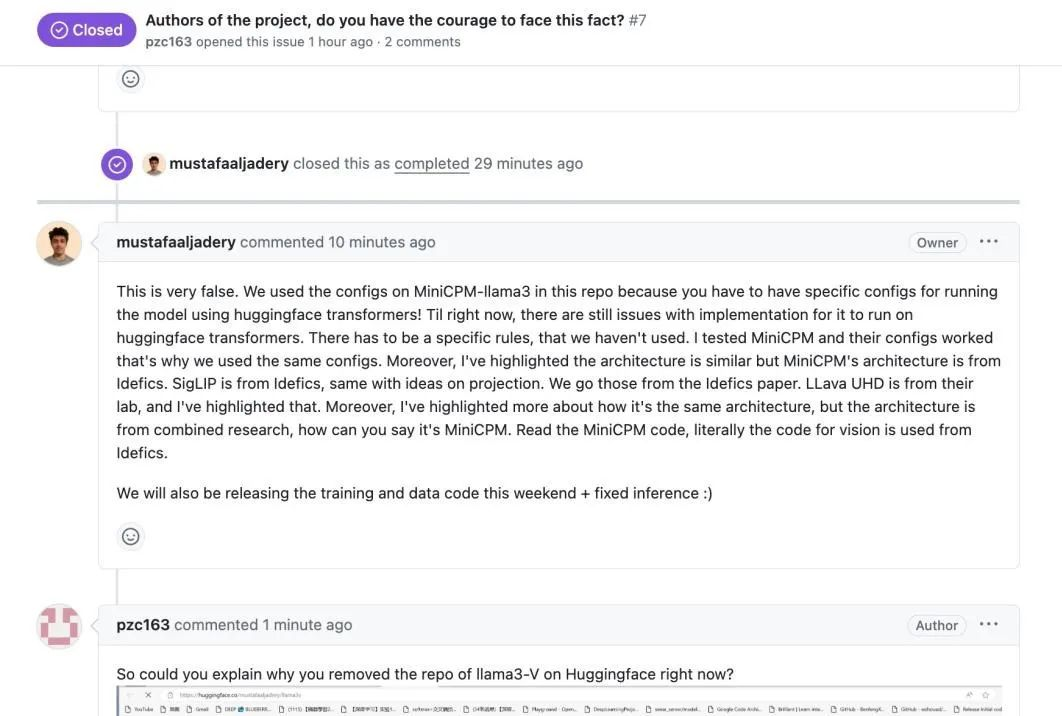
问题是 MiniCPM 和 LLaVA-UHD 原来的样子早就不一样了,而你这个 Llama3-V 的长相跟 LLaVA-UHD不能说一模一样,至少是毫不相关,但是跟人家小钢炮就像一个妈生的。
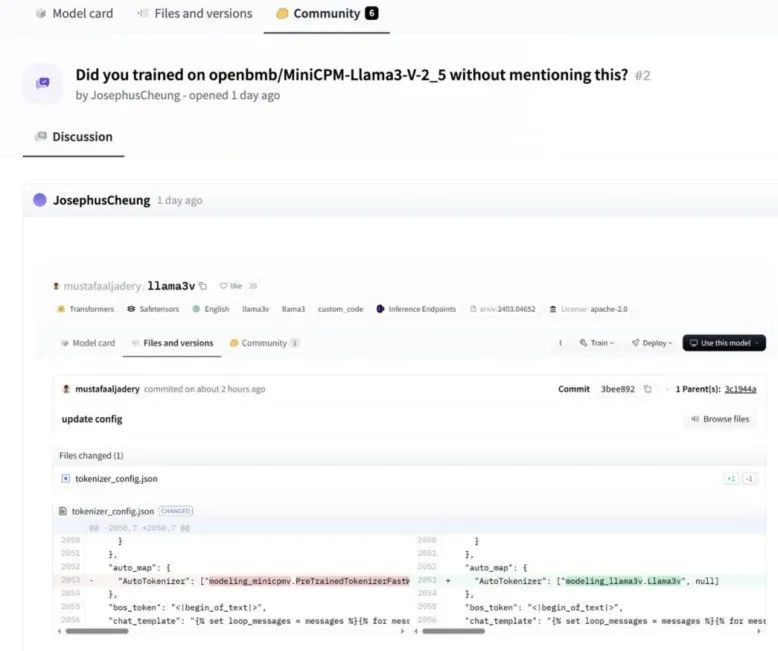
等放一块儿仔细一瞅,好家伙,模型结构跟人家像也就算了,配置文件怎么都一模一样。
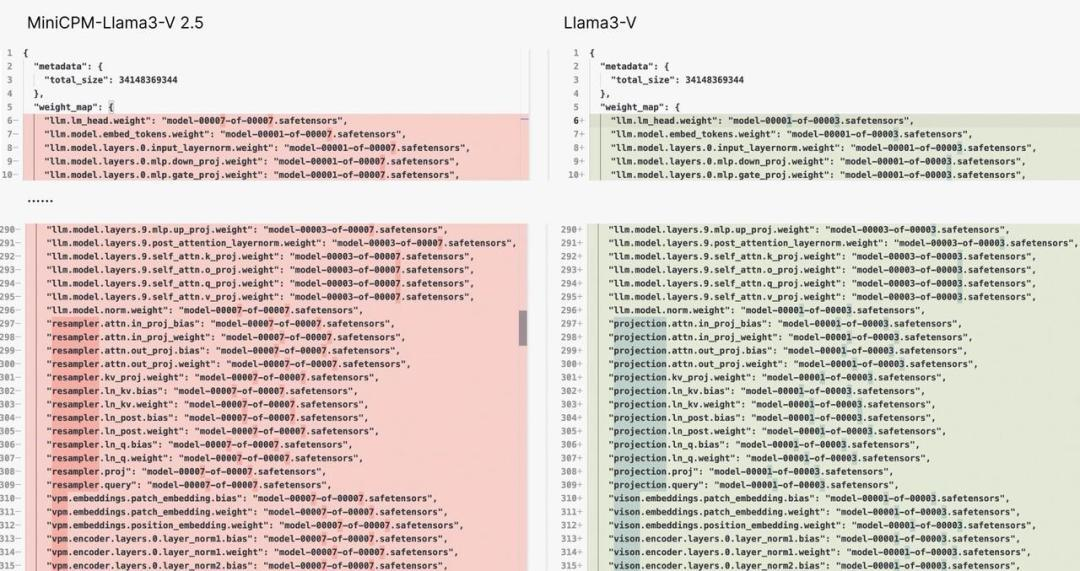
再一看代码,除了加点格式化,改了几个变量名,别的都毫无区别,甚至人家清华专门定义的特殊符号,你这代码里都没变过。
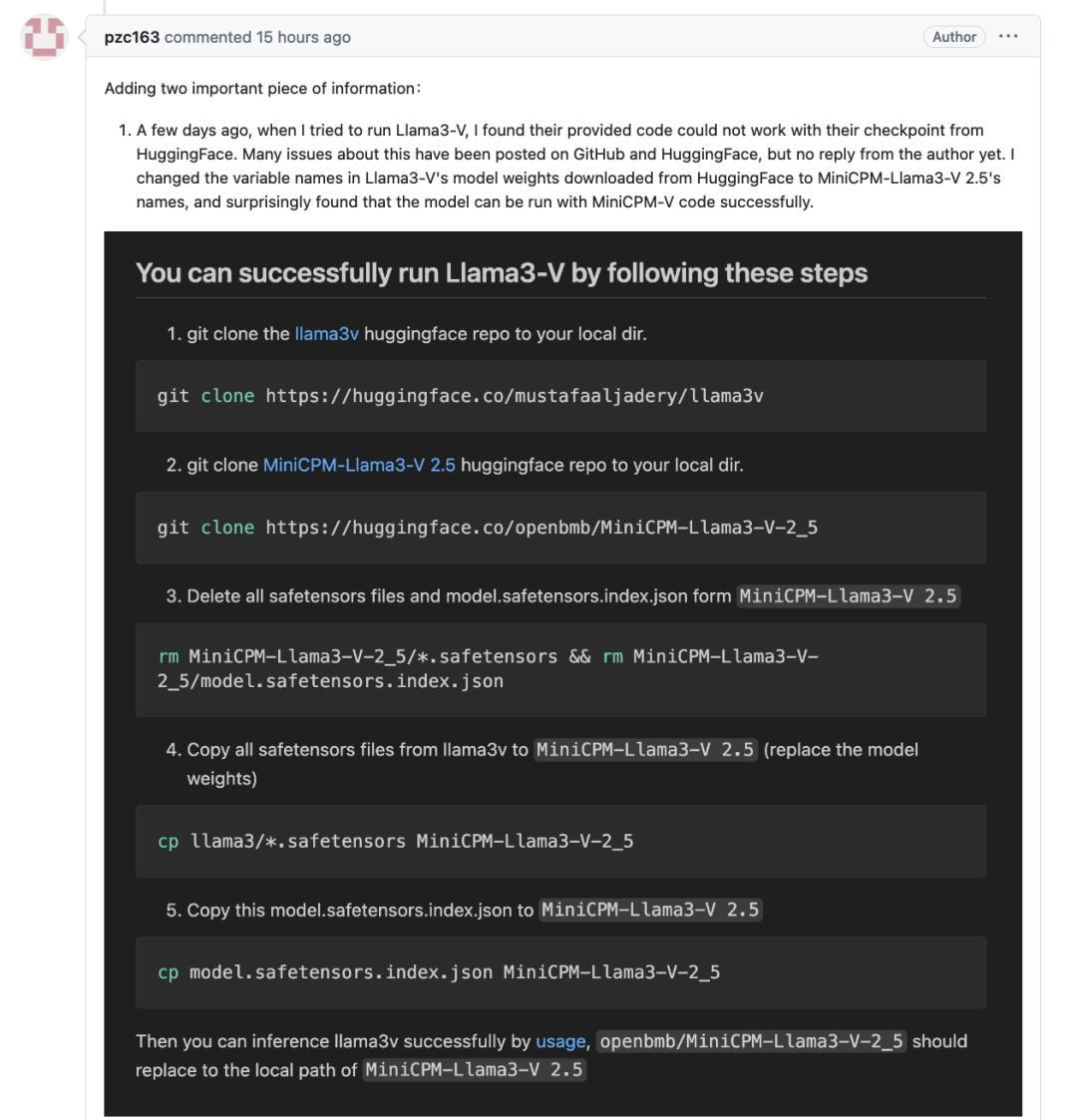
更搞笑的是,有网友发现运行 Llama3-V 时,用斯坦福团队提供的权重文件(神经网络微调用的参数 )是跑不起来的,但如果把其中的变量名改为 MiniCPM-Llama3-V 2.5 的,就会丝滑启动。
都锤成这样了,印度老哥还是始终咬死不认。
很快,收到消息的面壁智能官方也下场开锤,表示 Llama3-V 项目的作者并不完全理解 MiniCPM-Llama3-V 2.5 的架构,甚至也不理解他们自己的代码。
换句话说,还挺阴阳的, “你抄都没抄明白啊。”

除此之外,面壁团队还甩出一个雷神之锤的证据, Llama3-V 居然可以识别清华简!
清华简是清华校友捐赠的重要文物,这些埋藏于战国时代的竹简躲过了秦始皇焚书,保存着包括古本《尚书》、先秦史料、医方哲学等极其珍贵的原始档案,简单来说就是上古版《永乐大典》。
清华简识别其实是 MiniCPM-Llama3-V 2.5 研发时内置的彩蛋,所有训练识别的数据,都是面壁智能和清华大学合作,一个字一个字扫描标注的,从未公开。这些完全私有的数据斯坦福团队不可能拿到,但是两个模型却都能实现识别,甚至犯错的地方都一模一样。

到这,可以说他们抄袭是百分百,板上钉钉的事了。鼓破万人捶,面对全世界网友的唾沫星子,这俩印度哥们怎么做的呢?
答,删库跑路!
他们马上删掉了 HuggingFace 上的 Llama3-V 模型,并表示: “ 非常感谢那些在评论中指出与之前研究相似之处的人。我们意识到我们的架构非常类似于OpenBMB 的 MiniCPM-Llama3-V 2.5 ,他们在实现上比我们抢先一步。我们已经删除了关于作者的原始模型。 ”
不是,过分了啊,还要点脸不?
然后他们又光速滑跪道歉甩锅三连,说我们哥俩只是宣传推广的,代码都是外包给另一个南加州大学老哥干的,冤枉啊!
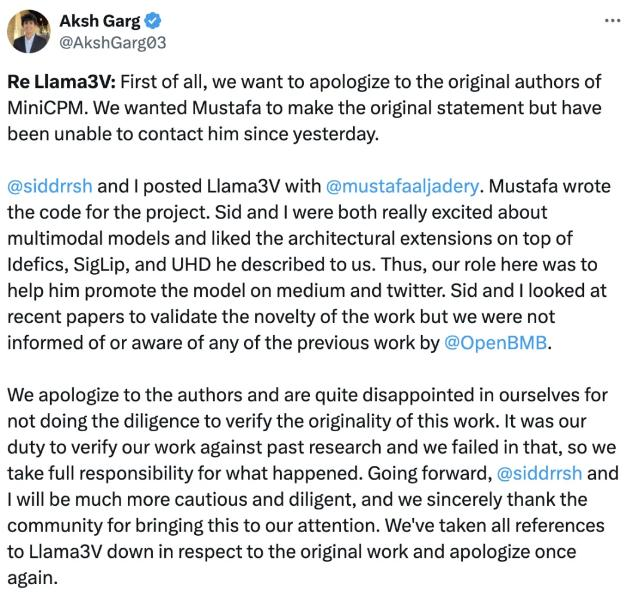
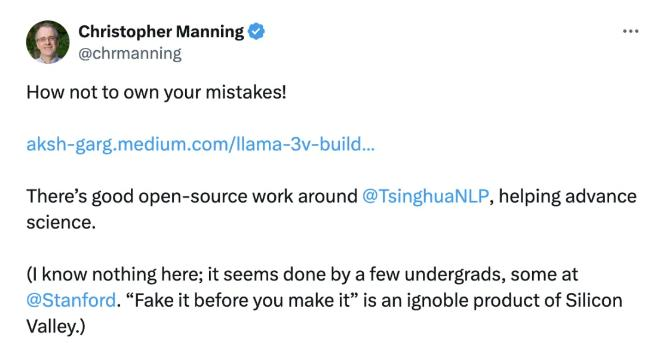
但事已经闹大了,丢面儿的斯坦福大学官方也急忙下场,他们的人工智能实验室主任,谷歌 Deepmind 的研究员 Christopher David Manning 直接发文开喷, “ 典型的不承认自己错误! ”
并对 MiniCPM 这一中国开源模型表示赞扬。
而被抄的面壁智能联合创始人刘知远,则对他们喊话:“团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。”
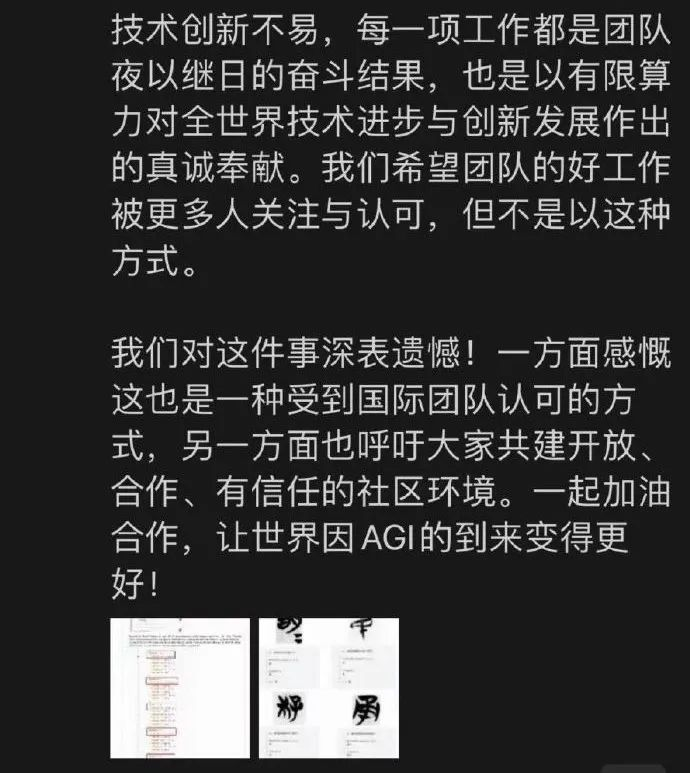
面壁 CEO 李大海也诙谐回应道: “ 我们对这件事深表遗憾。一方面感慨这也是一种受到国际团队认可的方式,另一方面呼吁大家共建开放、合作、有信任的社区环境。 ”
“ 我们希望团队的好工作被更多人关注与认可,但不是以这种方式。”

话虽这么说,但这次的事确实也让大家注意到,国产 AI 好像也不是刻板印象中那样了。
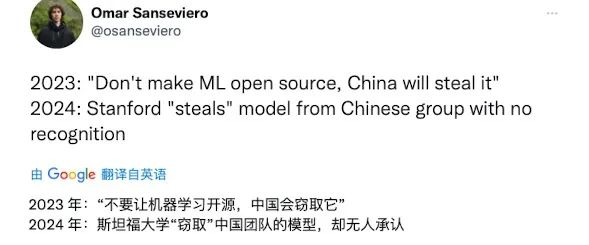
连开头的大佬, Hugging Face 的负责人 Omar Sanseviero 也表示,
“ 社区一直忽视了中国机器学习生态系统的工作。他们正在用有趣的大语言模型、视觉大模型、音频和扩散模型做一些令人惊奇的事情。 ”
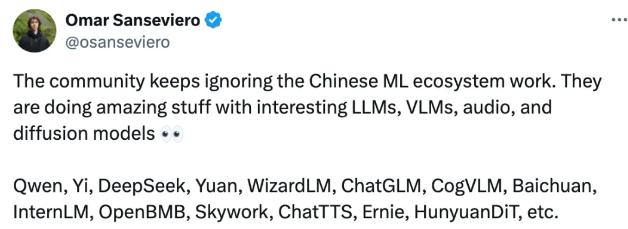
并提到鹅厂混元大模型,和最近爆火的 ChatTTS
拿这次的主角面壁智能来说,虽然各大厂商( 上个月谷歌安卓 15 ,过几天苹果 iOS18 )都在布局移动端大模型,但经过此次事件,大家发现这家中国公司,在这个赛道上也十分出色。
MiniCPM 不但体量小,只用 2.4B 的数据规模就能达到数倍于它的模型能力,不仅支持安卓系统,还支持鸿蒙,推理做题都毫不逊色。

视觉识别能力也相当不错,特别是中文图像场景下,表现比 ChatGPT-4V 更好。

除此之外,面壁官方还在今天中午官宣,「小钢炮」MiniCPM 决定免费公开!对学术研究完全开放,企业和个人只需填写问卷登记后就允许商用。

什么叫格局啊~( 战术后仰 )
世超觉得,网友们确实也应该改变一些成见。许多人以前都认为,国产 AI 都是套壳 ChatGPT , 这不行那不行,感谢 XXX 开源。
然而就像刘知远说的,尽管面对国际领先模型仍有差距,但中国大模型已经从以前的 nobody ,成长为了 AI 领取的关键推动者之一。
至于这两个年轻人,希望你们耗子尾汁,不要再耍这样的小聪明。
文章来源于“差评”,作者“纳西”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
