# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。

➤ 论文地址
🔗 https://www.nature.com/articles/s41467-025-61040-5
自 OpenAI 发布 GPT-4 以来,多模态大模型深刻地改变了人工智能研究和产业的基本范式,在理解和推理图文语义信息方面展现出革命性能力,但其庞大的参数量和高昂的计算成本,使其严重依赖云端高性能服务器部署。这极大地限制了模型在移动设备、离线环境、能源敏感场景或注重隐私保护场景中的广泛使用。

图1 研究团队发现,随着算法、数据、算力的协同发展,达到 GPT-4V 水平的模型参数规模随时间增长迅速缩减,而端侧算力水平快速增强。
针对这些挑战,研究团队致力于实现“轻量级、高性能”的多模态大模型,从模型结构、训练方法、数据处理等方面进行了系统性探索,提升了多模态大模型拓展定律将计算转换为模型能力的效率。(1)在模型架构方面,团队提出 LLaVA-UHD 高清高效视觉编码方案,通过自适应分块方式将图像分割为无重叠的不同区域分别编码,然后通过压缩层减少冗余特征。得益于高清高效视觉编码方案,MiniCPM-V 支持最高 180 万像素的任意长宽比高清图像输入、具备领先的 OCR 能力,同时实现领先的视觉编码压缩率。(2)在训练方案方面,团队提出 VisCPM 跨语言跨模态联合泛化训练技术。基于该方法,团队在指令微调过程中引入了少量多语言语料,即可激活中英法日韩等 30 多种语言的多模态交互能力。(3)在数据构造方面,基于团队提出的RLAIF-V 高效自动反馈构造方案,团队在最后的训练阶段显著减少了模型的幻觉行为,在模型可信度上显著超过 GPT-4V。
结合这些关键创新,MiniCPM-V 模型以 80 亿参数量实现了超过 GPT-4V、Gemini Pro 和 Claude 3 等国际主流商用模型的多模态能力水平。团队近期最新提出的 MiniCPM-o 模型,进一步在视觉、语音和全模态实时流式交互能力上达到 GPT-4o-202405 水平,并支持在端侧设备上的高效推理,延续了“轻量级、高性能”这一核心特点。
高清高效视觉编码架构
视觉编码是多模态大模型构建中最核心的问题之一,传统方法(图 2)中编码所需的特征序列长度随输入图像的尺寸增大而迅速增加,极大限制了视觉编码的效率和所支持的输入图像尺寸。
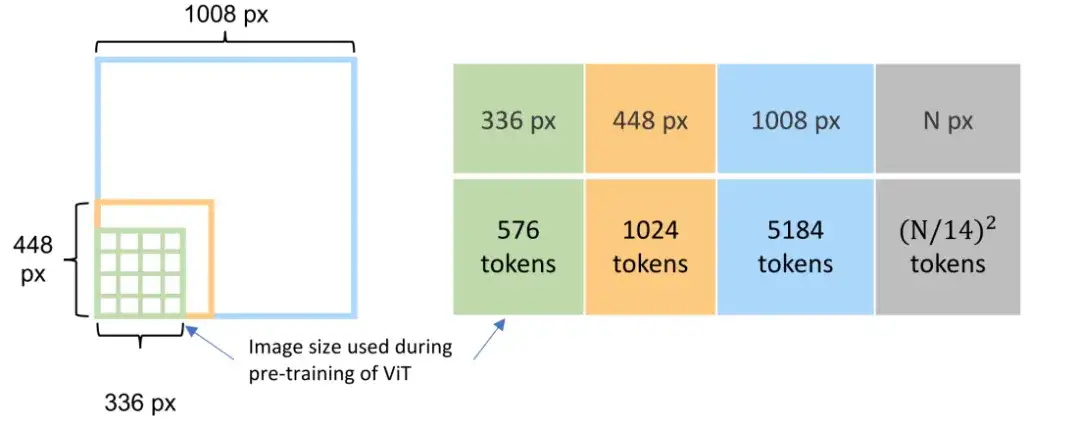
图2 视觉编码的特征序列长度随着图像尺寸呈平方级速度增长。
为此,团队提出 LLaVA-UHD 创新方案,通过自适应分块方式将图像分割为无重叠的不同区域分别编码,然后通过压缩层减少冗余特征(图 3)。通过将互相分割为无重叠的不同区域,LLaVA-UHD 可以充分复用在相对低分辨率规格(如 224^2、336^2 等)下预训练的强大视觉编码器(如 CLIP、SigLIP 等)的原生编码能力,同时显著降低了 ViT 编码的计算量和显存开销。团队还通过压缩层的设计,进一步降低了 LLM 的计算和显存开销。
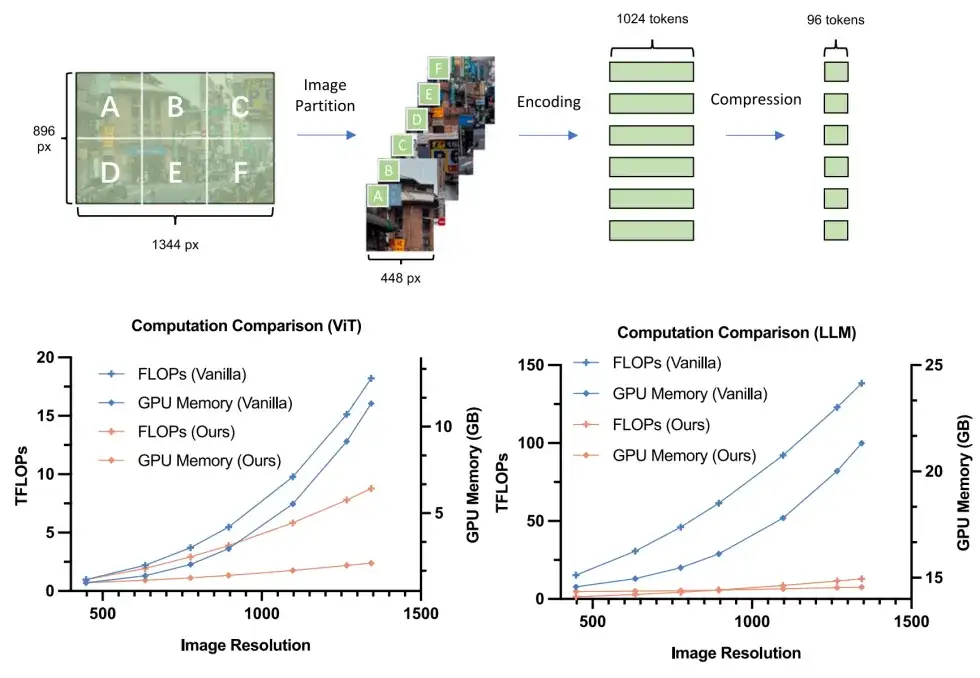
图3 LLaVA-UHD 高效高清编码架构显著降低了计算和显存开销
高效泛化训练方案
多模态大模型构建需要大量的高质量多模态训练数据,而目前中文多模态数据规模和质量相比英文数据仍相对落后。针对这一问题,研究团队经过大量实验和观察提出跨语言跨模态泛化技术 VisCPM,通过在多语言 LLM 基座上进行多模态训练,单一语言上的多模态交互能力可以高效泛化到其他语言。
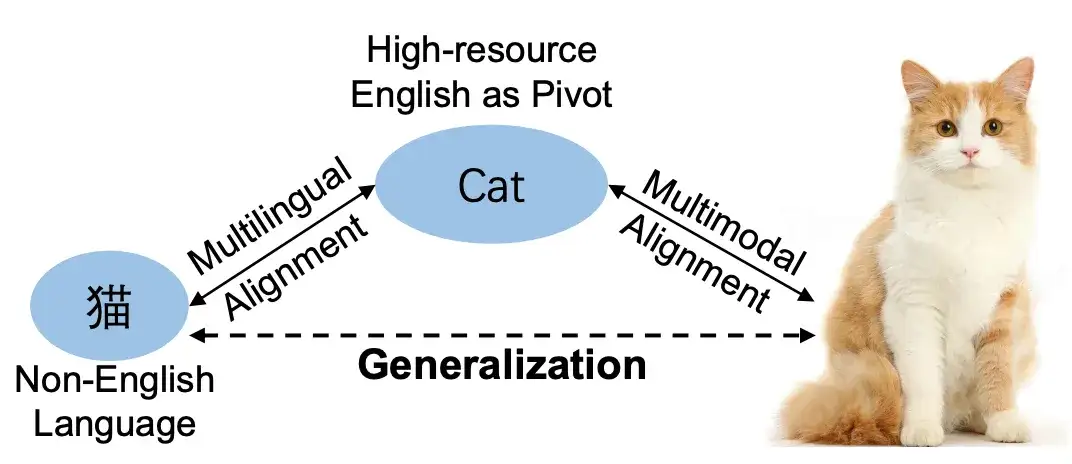
图4 VisCPM 高效跨语言跨模态泛化
基于 VisCPM,研究团队在中文多模态训练数据有限的情况下实现了强大的中文多模态理解能力,并进一步将模型的多模态理解能力推广到西班牙语、法语、日语等数十种语言(图 5)。

图5 多语言多模态能力
高效偏好对齐方法
学术界和工业界普遍发现多模态大模型容易生成与图像内容矛盾的内容,严重影响了多模态大模型的可信度与可用性。而传统方法依赖劳动密集型的人工标注或蒸馏昂贵的闭源模型以获得偏好学习数据,难以规模化扩展。
针对这一挑战,团队提出 RLAIF-V 高效偏好对齐技术,通过开源多模态模型构建人类标注水平的高质量多模态偏好数据。具体来说,团队将复杂的偏好标注任务拆解为更简单的原子命题判别任务(图 6),从而使得基于开源模型自动构造的偏好数据质量得到显著提升,达到与人工精标注结果超过 90% 的一致性,超过蒸馏 GPT-4V 等模型的偏好标注质量。
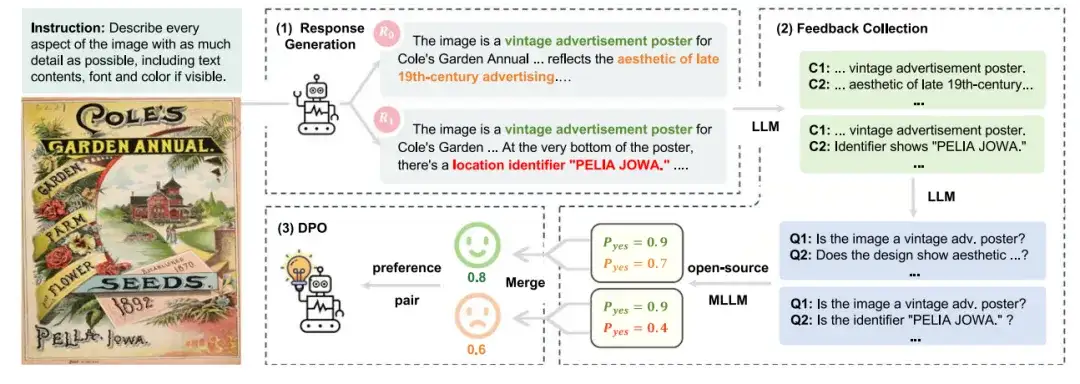
图6 RLAIF-V 高效偏好对齐框架
使用 RLAIF-V 高质量偏好数据进行偏好学习训练(Preference Learning),MiniCPM-V 在多项可信度评测上取得显著提升,超过 GPT-4V 等闭源商用多模态大模型(图 7)。

图7 MiniCPM-Llama3-V 2.5 在各项可信度评测上超越 GPT-4V
高效端侧部署解决方案
相比于云端设备强大的算力与充足的显存,端侧低资源场景对模型的部署和推理优化带来了更多的挑战。对此,研究团队提出结合内存优化、编译优化、配置优化、NPU 加速的系统性优化方案(图 8),显著降低了推理延迟和计算开销。
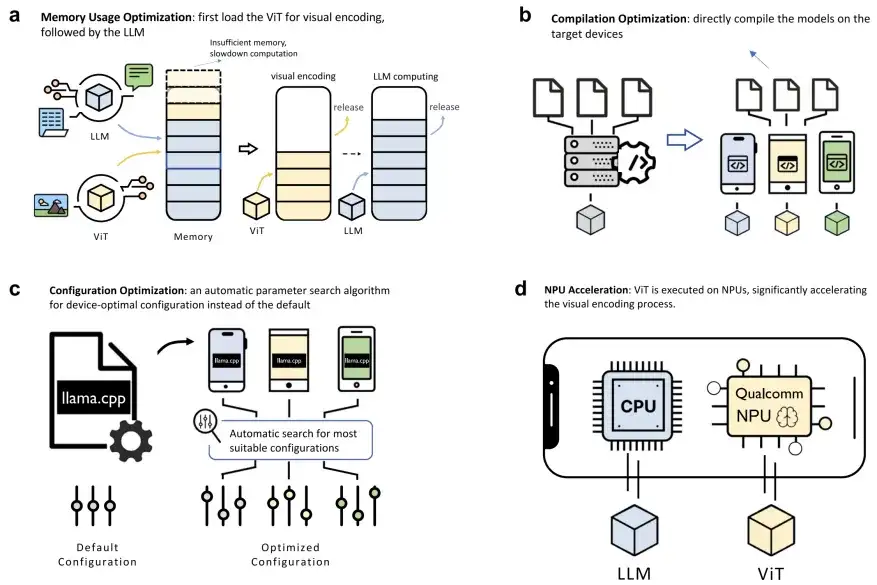
图8 高效端侧部署解决方案
基于这些优化,研究团队将编码延迟从原始的 64.6s 降低到 10.7s,并提高模型的解码速度达 6.3 倍,成功在消费级手机上满足人类阅读所需速度。并进一步在多个硬件平台上验证了该方案的低延迟高吞吐特性。

图9 推理延迟显著下降,解码速度满足人类阅读需求
总结
研究团队通过以“高效”为核心,充分挖掘多模态大模型从模型架构、训练方案、数据构造到硬件部署的各方面的潜能,实现了在手机上运行 GPT-4V 级别强大多模态大模型的突破。MiniCPM-V 连续多天在 Hugging Face Trending、GitHub Trending 和 Papers With Code Trending Research 榜单排名第一,GitHub 开源项目获得星标近 2 万次,模型下载量超过 1000 万次,并入选 Hugging Face 2024 年度最受欢迎和下载开源模型榜单。
更多细节,请参考原论文。
文章来自公众号“OpenBMB开源社区”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
