# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于每一位热爱打游戏的人而言,都曾经想过这样一个问题,「这游戏要是我来做就好了!」
可惜的是,游戏开发有很高的门槛,需要专业的编程技巧。
近日,来自上海交大的团队开展了一个名为「Instruction-Driven Game Engine, IDGE」的项目,他们针对未来游戏的开发,提出了一个酷炫的新范式:利用自然语言指令开发游戏,玩家说怎么玩就怎么玩,让 UGC 贯穿于游戏的每个角落。
IDGE 顾名思义,是一个指令驱动型的新概念「游戏引擎」,它能够支持用户输入对游戏规则的自然语言描述,来自动生成一个「玩家专属」的游戏。

01:
概述
什么是 IDGE
游戏引擎是游戏开发的核心,传统意义上的游戏引擎由复杂的编程语言驱动。这种壁垒阻碍了游戏爱好者实现他们开发游戏的梦想。
文中提出的指令驱动游戏引擎 IDGE,让使用者只需提供一段自然语言的指令,就能设计出新的游戏,并基于该引擎进行游玩。这种指令作者称之为「游戏剧本(Game Script)」,它详细描绘了用户想要的游戏的全貌。
从对话模型到游戏引擎
IDGE 是一个基于大语言模型(LLM)的神经引擎,如今的对话式大语言模型,如 ChatGPT,能够通过一个 system prompt 来扮演各种角色,和用户进行对话交互。
传统的游戏引擎也可以被看作是一个精密版的交互系统。引擎根据玩家利用编程语言实现的游戏规则,在每次玩家进行了输入以后,都会计算一次最新的游戏状态,并且将最新状态渲染成游戏画面展示给玩家。对于 IDGE 来说,其主体流程与传统游戏引擎类似,但游戏规则是用自然语言描述而不是用编程语言编程实现,游戏状态的计算也由 LLM 推理得到。
以大家最熟悉的石头剪刀布为例,对于 IDGE 而言,我们实现游戏的方式是给定一段游戏剧本作为 system prompt:
现在玩一个名为石头剪刀布的游戏,两位玩家同时发出代表游戏元素的动作;石头、剪刀和布。游戏的结果由 3 个简单的规则决定:石头战胜剪刀;剪刀战胜布;布战胜石头。如果动作相同则进入下一轮游戏。
以下是一个实际游戏的例子:
IDGE:开始剪刀石头布,请出示你的动作
IDGE:player 1 的动作是剪刀,player 2 的动作是剪刀,游戏继续,请出示你的动作
IDGE:player 1 的动作是剪刀,player 2 的动作是石头,player 2 获胜,游戏结束
稳定性和多样性的双重挑战
乍一看,IDGE 的运作方式跟传统的对话模型是一样的,用户皆以多轮对话的形式和模型进行互动。但是,作者认为 IDGE 相比于普通的对话模型,会遇到两大挑战。
如何建模游戏引擎的任务
文章中,作者基于对游戏的理解,提出了一种全新任务,称为「Next State Prediction」。相比于自然语言,由一串字符(token)定义了一句完整的话,一局完整游戏由一系列游戏中状态(in-game state)组成,这些状态代表了游戏当前的所有信息。因此对于一个游戏引擎来说,它的任务就是,根据之前的游戏状态,预测下一个游戏状态。
然而一个游戏状态序列相比于字符序列要大得多,这很可能造成输入的溢出。针对这种情况,作者引入了独立性假设,即某一时刻的游戏内状态只和此前的 1 个有关,那么问题的求解就简化成了:
其中 z 为游戏剧本,对于一整局游戏来说是全局变量,x_t 是 t 时刻的玩家输入。
数据生成和数据定义
除了问题的建模,如何构造数据也是 IDGE 的核心问题。
本文以扑克牌游戏作为 IDGE 的第一个探索场景。在文中,作者通过一个扑克牌模拟程序,获取了大量的游戏日志,由此作为 IDGE 的数据来源。
游戏剧本
作者制定了一个结构化的剧本模板,如下图所示。通过填充相应的配置参数,表达不同的游戏。
可以看到,剧本支持 7 种主要的参数:玩家人数、底注、初始筹码、花色种类、单牌的大小排序、组合牌的大小排序、游戏流程。
除了结构化的描述,游戏剧本还包含了对某些特定游戏规则的自然语言描述,如上图中的「Specific Rules」所示,这里的描述要求引擎把手牌最小的玩家视作为赢家,和传统的德州扑克相反。自然语言的引入,大大增加了游戏剧本的多样性。
数据效率
除了生成数据,作者还强调了数据的效率问题。由于模拟器是一局一局游戏生成的,那么会造成的结果是,一些出现概率较低的情况会更低,导致数据不平衡。作者提到,这是引擎(engine)相比于智能体(agent)的一个重大区别:智能体通常遵循一组特定的策略,而引擎则尽可能地保证对所有可能的策略都是无偏的。
一个直观的例子就是扑克牌里的顺子,正常来说它出现的情况远远低于对子。那么在这样的数据上训练得到的引擎,会在对子上过拟合,而在顺子上欠拟合,即使训练数据量非常大。
针对这个问题,作者给出了一个简单的小技巧,即调整数据采样的比例,让所有情况尽可能地均衡。下图左侧为随机采样下各个牌组出现的频率直方图,对子和高牌要远远高于其它组合,而右侧为均衡之后的直方图。
训练方法
为了使模型兼备稳定性和多样性,作者提出了一种课程学习的方法。一次训练分为三个阶段。
预热(Warmup)
一个游戏引擎涵盖了多类型的任务,对于一个扑克引擎来说,它需要学会发牌、翻牌、换牌、下注等。一次性让模型去学习大量的子任务,会带来冷启动问题。因此,作者提出了一个预学习过程,即让模型先在一个称为「核心集」(Core Set, CS)的指令微调数据集上进行预学习。核心集里包含了各种各样的基本函数,为模型提供了一个良好的初始化。
作者提到,核心集的作用类似于传统计算机系统的工具库,为系统的上层功能提供支持。只不过不同的是,对于大语言模型来讲,这些工具都以指令的形式存在。
标准(Standard)
预热过后的第二阶段,即让模型在标准的引擎数据上进行微调。
多样(Diverse)
最后一个阶段也是最难的阶段,模型需要超越标准数据中的结构化游戏剧本,学习理解自然语言描述的剧本。相对于人工标注大量的自然语言剧本,作者提出了一种简单而高效的方法,称为「片段重述」(Segment Rephrasing, SR)。具体来说,随机采样剧本的某些片段,用 GPT3.5 以自然语言将其重述。相比于结构化,经过重述后的游戏剧本会具有更加丰富的语言表达,更加难以理解。
这一个过程作者还利用了一个小技巧,即在经过重述后的数据上训练的同时,采样一定比例的标准化数据,目的是减轻模型的灾难性遗忘。作者发现这有助于提高最终的稳定性。
以上三个阶段,预热、标准、多样,对应了课程学习的三种难度等级。从训练的角度来看,它对应着模型从标准化到指令化的迁移。
实验结果
作者选择了扑克牌作为测试的游戏,并设计了两部分的实验来验证 IDGE 的性能。
模拟器数据
第一部分测试数据来自于扑克牌模拟器。作者借助模拟器,生成了一组测试集,涵盖了总共 10 种扑克牌游戏的变体,分别是 Texas hold’em、5-card draw、Omaha、Short-deck hold’em、2-to-7 triple draw、A-to-5 triple draw、2-to-7 single draw、Badugi、Badeucey、以及 Badacey。
和常见的准确率不同的是,作者汇报的是每局游戏的成功率(sucess rate)。每一种类的游戏连续玩 20 局,如果一局游戏中引擎的预测全部正确,那么成功率就 + 1。结果如下:
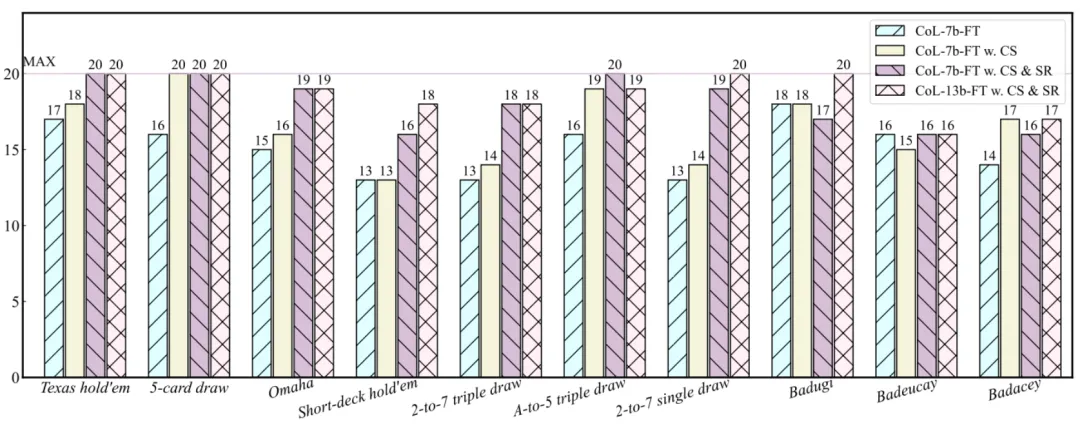
结果证明,核心集的预热以及最后的重述,都十分利于模型的训练。
值得注意的是,作者挑选的是 CodeLLaMA-7b/13b 来进行的实验。他发现经过程序语言预训练的模型表现要优于自然语言预训练的模型。为此,他给出的解释是:程序语言和 IDGE 的标准化数据类似,都是高度结构化的,因此 code-pre-trained LLMs 会更加擅长 IDGE。
作者还发现了一个有趣的现象,就是通过 prompt 驱动的 GPT3.5 和 GPT4 在这个任务上的成功率是 0。由此,作者做了进一步分析,将所有局的游戏状态按照功能进行分类,得到了一个重组后测试集。
按照状态分类后,各个模型的准确率如下:
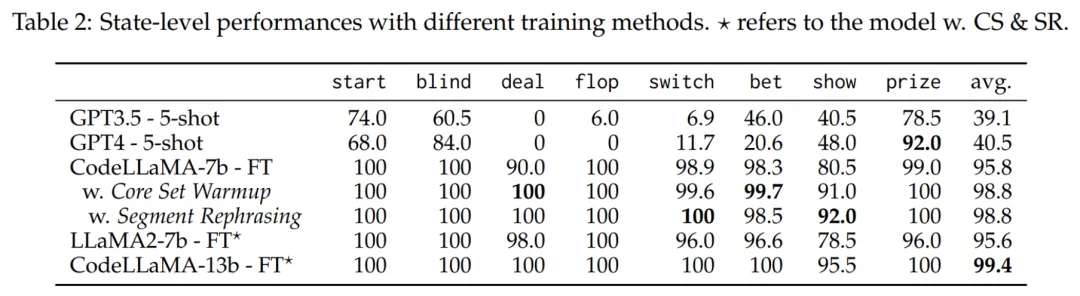
结果发现 GPT3.5/4 的数学能力表现出色(prize 指代的是计算奖池的功能)。但是,作者发现他们对牌的处理很差,例如在发牌(deal)上,准确率一直是 0。作者猜测,如今的大语言模型在训练时很少会遇到引擎的高精度数据,因此表现不佳。这些子功能上的错误累计,最终会以木桶原理的方式影响引擎整体的性能。
玩家手写数据
为了进一步验证引擎在真实场景下的表现,作者团队邀请了几名真人玩家,让他们自行发挥创意,每人用自然语言编写一个新的游戏规则。
总共产出了如下 5 个剧本:

可以看到,从剧本 1 到剧本 5 的难度逐渐提升。剧本 5 非常具有挑战性,定义了一个全新的 6 牌游戏,随即新出现了两个全新的 6 牌组合,三对(Three Pair)以及大葫芦(Big House)。
在用户为 IDGE 编写游戏剧本时,还能够通过手写几个样例,来提高引擎对剧本理解的准确性。表现如下:
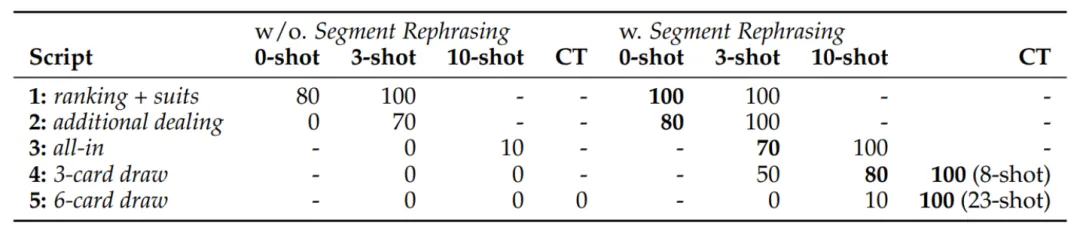
可以看到,对于剧本 1 至剧本 4,模型在零样本或少样本,能够取得非常不错的成绩。
然而对于剧本 5,模型显得理解起来出现了困难。对于这种情况,作者给出的解决方法是,用户自适应!具体来说,在用户游玩 IDGE 的时候,若发现模型给出错误解,手动纠正结果再送给模型。此时模型会收到一对「好」和「坏」的样本,作者利用 DPO 进一步更新模型的参数。用户可以持续进行这一过程,直到引擎性能令其满意为止。
从结果来看,对于剧本 4,引擎需要 8 个样本,在测试集上达到 100% 的准确率。而对于剧本 5,引擎收集了 23 个样本后,达到 100% 的准确率。
这提供了给了游戏制作者和玩家们一个全新的思路:根据玩家自己的游戏反馈,定制一个私有化可定制的的个人游戏引擎!
文章来自微信公众号“机器之心”,作者:机器之心编辑部




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
