# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近期,硅谷 AI 公司 OpenAI 可谓是话题度拉满,先是一出「宫斗戏」引起舆论哗然,后是公布 Sora 效果炸裂受到了全网的一致好评。在这期间,一桩诉讼案件同样引爆了热点 —— 因 ChatGPT 涉嫌侵犯纽约时报著作权,OpenAI 及微软被起诉并要求支付巨额版权费 [1]。一方是传统新闻行业的代表刊物,一方是新兴人工智能技术发展中的佼佼者。双方展开这场「里程碑式」拉锯战的同时,也将科研圈长期存在的问题再次拉上了台面:
在 AI 高速发展的浪潮中,如何在保持技术创新的同时不失对于数据安全问题的考量?
的确,随着近年来产业化模型的逐步发展,数据安全在个人隐私、模型安全、版权问题等多方面都受到了严峻的挑战,如:语言模型因引入个人信息而埋下的隐私泄露隐患;扩散生成模型因训练数据中涵盖色情、暴力等不良图像而导致具备产生违法内容的能力。此外,诸如国家互联网信息办公室颁布的《生成式人工智能服务管理暂行办法》[2],以及欧盟的《一般数据保护条例》[3](GDPR)等也意味着对于数据安全的约束也逐渐从道德层面转向了法律、法规层面。人们对于数据安全的需求逐渐从幕后转向了台前,对于机器学习相关研究者以及现有人工智能服务的提供者而言也是亟待解决的问题与挑战。
直观而言,移除敏感数据并重新训练(Retrain)是一种合理的消除数据影响并保证模型安全的方法。然而,训练模型对时间和算力的消耗不容小觑,对于一些已经产业化并投入使用的大模型,重新训练的额外开销会急剧增大。如何快速有效的消除数据对模型带来的影响 —— 机器遗忘,便成为了一个新兴的热门研究方向。
机器遗忘(Machine Unlearning, 也可称机器「反」学习),这种方法旨消除特定训练数据(如敏感或非法信息)对已完成预训练模型的影响,同时保持该模型的实用性。在评估一种机器遗忘方法时,我们需从三个关键维度出发:
1. 高效:算法是否高效运行;
2. 精准:特定数据是否被精准遗忘;
3. 稳定:遗忘后模型是否具有稳定泛化能力。
遗憾的是,现有的机器遗忘方法都无法同时满足这三个维度的要求。近日,密歇根州立大学(Michigan State University)、宾夕法尼亚大学(University of Pennsylvania)和 IBM 研究院(IBM Research)的研究者们分析了已有机器遗忘方法的局限性,基于权重显著性提出了一种简单、直观但表现优异的机器遗忘框架 ——SalUn(Saliency Unlearn)。实验结果表明,在图像分类和图像生成任务上,SalUn 都能够出色地满足高效、精准和稳定这三个维度的要求,证明了其在机器遗忘领域的创新性和重要性。

论文的共同一作樊翀宇在密歇根州立大学交流期间(目前是华中科技大学的本科生,即将加入密歇根州立大学攻读博士学位),与清华姚班毕业生刘剑成协作完成了这项研究。目前,相关论文已被人工智能领域的顶级会议 ICLR 2024 录用为 Spotlight。

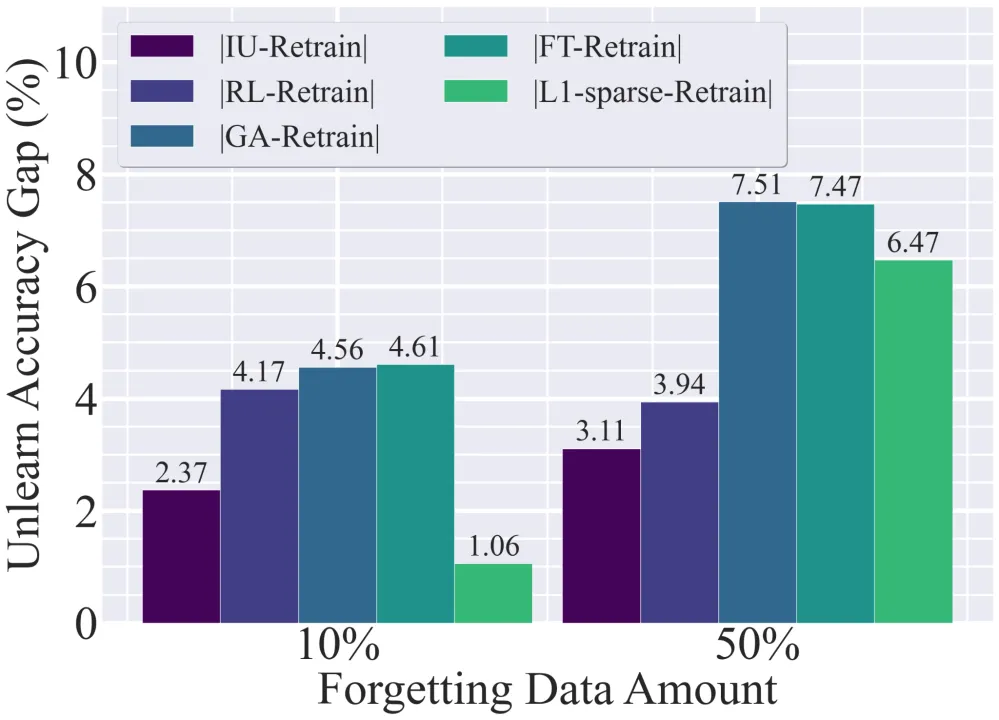
1. 在分类任务下的不稳定性:现有方法在图像分类中不同遗忘任务下的表现仍存在差异性。从下图可以看到,在遗忘数据量为 10% 时,一些基线方法如 l1-sparse [6] 可以接近理想的遗忘效果,但当遗忘数据量逐步增加,特别是达到 50% 时,现有方法与理想的遗忘差距显著增大。
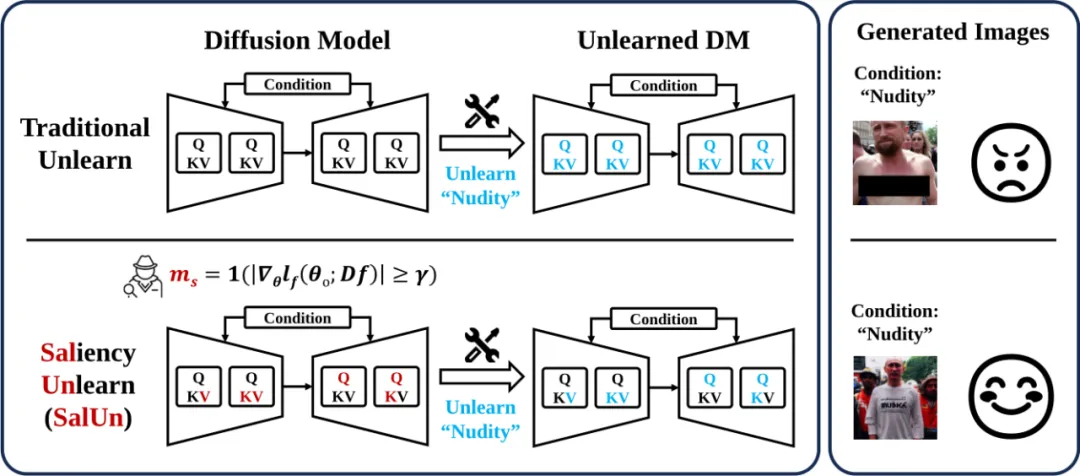
2. 在生成任务下无法泛化:目前已有的机器遗忘方法集中于图像分类任务,不能适应图像生成。如下图所示,当现有的遗忘方法直接迁移到生成模型上时,往往不是过度遗忘就是遗忘不足 —— 模型要么模型对于非遗忘类图像的生成质量不佳,要么仍然具有生成被遗忘类别的能力。

对于不同任务的分析表明,当遗忘任务逐步变难时,遗忘数据和剩余数据在这些任务下可能产生更强的耦合进而导致已有方法无法在保证遗忘效果的同时维持模型的泛化能力。为了达到更加精准的移除,本文在机器遗忘中引入模块化(modularity)思想,提出了基于权重显著性(Weight Saliency)的机器遗忘方法 ——SalUn。
一般而言,显著性是指模型在做出决策或预测时认为最相关或最重要的数据特征。而权重显著性将此概念扩展到模型的内部权重,确定哪些权重对模型的结果影响最大。SalUn 利用遗忘损失梯度预估相关的权重显著性,筛选出对遗忘数据敏感的权重,并着重对这部分权重进行遗忘。通过对于模型权重的精确掩模,SalUn 在消除模型中对应数据影响的同时尽可能减少对模型泛化能力的损害,以达到遗忘精准度和泛化稳定性之间更好的平衡,在不同任务下的遗忘中达到了一个统一、有效且简单的解决方案。
具体而言,对于机器遗忘更新后的权重(θu)可以经权重掩码(ms)表示为:
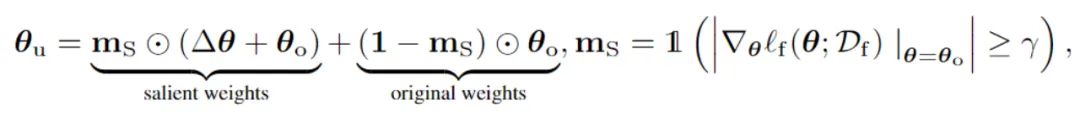
其中,权重掩码使用遗忘损失函数ℓf 的梯度作为显著性预估,并基于阈值 γ 进行筛选。文中发现,当ℓf 使用基于梯度上升(Gradient Ascent)的遗忘损失函数时即可取得较好效果,即:
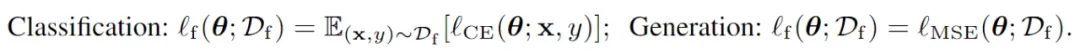
可以发现,SalUn 的一个优点便是它即插即用的能力:权重掩模对于现有的遗忘方法均可无门槛使用,并在遗忘表现上获得一定的提升。特别是,当将权重显著性与随机标签(Random Label)遗忘法相结合时,取得了目前 SOTA 的遗忘效果。随机标签遗忘为需遗忘的数据重分配一个随机标签,然后在重标签的数据集上微调模型。因此,优化过程及损失函数可分别表示如下:
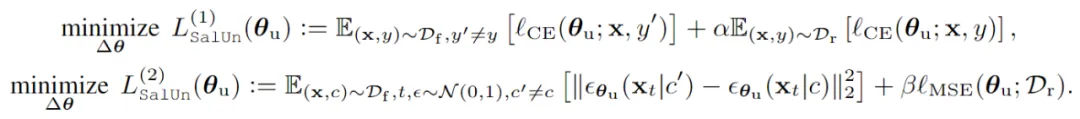
在图像分类任务中,两个主要的测试场景为类遗忘和随机数据遗忘。类遗忘是针对特定数据集上训练的模型,遗忘指定类的全部数据;随机数据遗忘则随机指定一定比例的训练数据进行遗忘。在两种场景中,与 Retrain 的表现误差会越小意味着遗忘表现越好。已有文献表明 [6],相较于类移除,随机数据移除更有挑战性,因此文中考虑图像分类时主要关注于 CIFAR-10 中 ResNet-18 模型在不同比例下的随机数据遗忘。相较于其他基线方法,SalUn 在所有实验中与 Retrain 间的平均差距均为最小,取得了目前的 SOTA 效果。
在图像生成任务中,主要的测试场景包含类遗忘和概念遗忘。其中,类遗忘与图像分类中类似,旨在消除模型中针对特定类的生成能力。文中探讨了将 Stable Diffusion 模型消除 ImageNette 数据集中不同类的效果。下图展示了 SalUn 遗忘「教堂」类前后模型生成效果的比较,可以发现在遗忘后模型在保持其余类生成效果的同时,无法根据文本提示「An image of church」(一张教堂图片)正确的生成对应图像。

略区别于类遗忘,生成模型中的概念(concept)遗忘通常指消除更为广泛的「概念」,如暴力、色情等。由于扩散模型训练数据量过于庞大,从中筛选并删除相关数据变得异常困难。如前文所述,目前 Stable Diffusion 仍然存在生成 NSFW 内容的能力,这自然成为了一种机器遗忘的应用场景。对此,文中测试了 SalUn 针对「裸体」概念的移除效果,并使用 I2P [4] 测试集对于遗忘效果进行测试。在此应用场景下,SalUn 相较于已有的概念移除的方法,能更好的消除「裸体」概念。
原论文中展示了更多研究细节以及经过 SalUn 遗忘前后的生成图像示例,感兴趣的读者可参考。
本文来自微信公众号”机器之心“



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
