# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果你手头有一个价值100亿美元的AI模型,通过了安全测试且让所有人受益,你愿意将它开源吗?
这个问题会让许多人陷入良久的思考,但小扎没有犹豫,他的回答是——我愿意!
这个惊人的言论,出自最近小扎在Dwarkesh Patel播客中的谈话。

此外,这期干货满满的谈话中,他还曝出了不少内幕消息,比如Meta为何会未卜先知,在2022年就大量买进H100;为何自己会笃信元宇宙等等。
而且,跟Sam Altman、马斯克等高歌猛进的乐观主义者不同,小扎对于AGI的短期实现是持悲观态度的。
在他看来,人类根本不可能在2025年之前实现AGI,因为最大的瓶颈就是能源限制。要解决能源问题,我们还需要几十年时间。
当主持人Patel问道:如果Meta砸了100亿美元开发出一个模型,它完全安全,甚至评估值还可以对模型微调,你会开源吗?
小扎坚定不移地表示:会。
主持人鲁豫脸表示不信:「花了100亿美元研发费用的模型,真的说开源就开源?」
小扎表示,Meta会对此进行评估的,毕竟公司一向以开源英雄著称,在开源方面有悠久的历史,拥有PyTorch、React和开放计算等项目。
在开放计算项目中,Meta将所有服务器、网络交换机和数据中心的设计都开源了。这样,整个行业都以他们的设计为标准,直接让供应链围绕这种设计建立起来。
这就大大降低了价格,直接为相关人员节省了数十亿美元。
而且,开源就能集思广益,如果有人能找到更便宜的运行方法,提升10%的效率,那就能直接节省数十亿甚至数百亿美元,这本身就是很值钱的,因此开源好处多多。
不过,他也承认:如果模型成为产品时,情况就变得复杂了。此时,就需要仔细权衡开源在经济上的利弊,不过,目前Meta并不处于这种情况。
这是显而易见的,因为Meta绝对不会把Instagram的代码开源。
同时,小扎也痛批了竞争对手一把。
他表示,移动生态最糟糕的一点就是,我们可以开发什么,是由苹果和谷歌这两个守门人把门的。
因为每当Meta构建出一些产品,这俩就会分走一大笔钱。
更让小扎不满的是,很多次Meta想要推出新产品或新功能,苹果都会说不行。
小扎直呼:如果世界里只有这几家运行封闭模型的公司,它们将直接控制API!
就是为了打破这种局面,Meta深信自己去构建一个模型是值得的。
对此,Ate-a-Pi开玩笑道:因为扎克伯格是个好人!
当然,他确实是个好人。但更重要的是这背后商业上的考量:
1. 允许在Meta之外进行社交产品的调试:
- 社交产品总会有bug!
- Meta以及所有社交平台的产品,都需要对互动的内容进行控制(例如对孩子说有害的话)
- 将技术推向市场,可以让Meta在小规模环境中观察到这些bug
2. Meta面临的最大威胁是character.ai:
- AI朋友将更多、更友好、更易于获取,超越你的现实朋友(目前被FB、Ins和WhatsApp等「控制」)
- 但Meta目前还不能直接下场,因为这会让人感到不安,尤其是在技术还未完善时,会产生一种怪异的不自然感
- Meta曾尝试过Tom Brady和Snoop Dogg风格的AI朋友,但为了安全,有趣的互动受到了很高的限制
- 如果AI朋友的表现足够好,小扎或许不得不「解散」他建立的社交网络
3. 摧毁竞争对手:
- 技术或产品的早期领先可以帮助一家初创公司克服分销上的不利
- Meta拥有终极的分销优势 ,而小扎不希望其他人分一杯羹
- 通过开源,他可以有效限制character.ai、OpenAI等公司收入的增长
- 这些公司必须在资本的限制下加速创新,而他并不会受到资本的限制
- 最终,防止大型竞争对手的出现
4. 分布式研发:
- 他希望其他人能够开发出有趣的社交创意,并进行复制(此前就曾将Snap的创新融入Instagram)
- 现在更甚,因为你必须给微调的Llama 3打上标注
不得不说,小扎的这波操作可谓是体现了他对社交无人能及的理解,仿佛就像来自另一个星球一样。

除此之外,在2023年第四季度财报中,小扎也曾详细说明过了以上内容。

简而言之,开源可以改进我们的模型。
首先,将模型转化为产品还需要大量工作,而且无论如何市场上都会有其他开源模型。
因此,我们认为成为开源的领导者不仅不会显著削弱我们产品的差异化,而且还会带来优势。

我之前以为,面向社交、商业或媒体领域的这些工具,只需解决AI挑战的一个子集就能交付。但现在看来,为了提供我们设想的最佳服务,模型必须具备推理、规划、编码、记忆等多种认知能力。
FAIR从事通用智能研究已有十多年,现在通用智能也将成为我们产品工作的重点。
关于AGI的短期实现,小扎是持悲观态度的。
在他看来,2025年之前是不可能实现AGI的,最大的瓶颈,就是能源限制。
能源将限制AI的发展,而如果要解决这些问题,可能需要几十年时间。
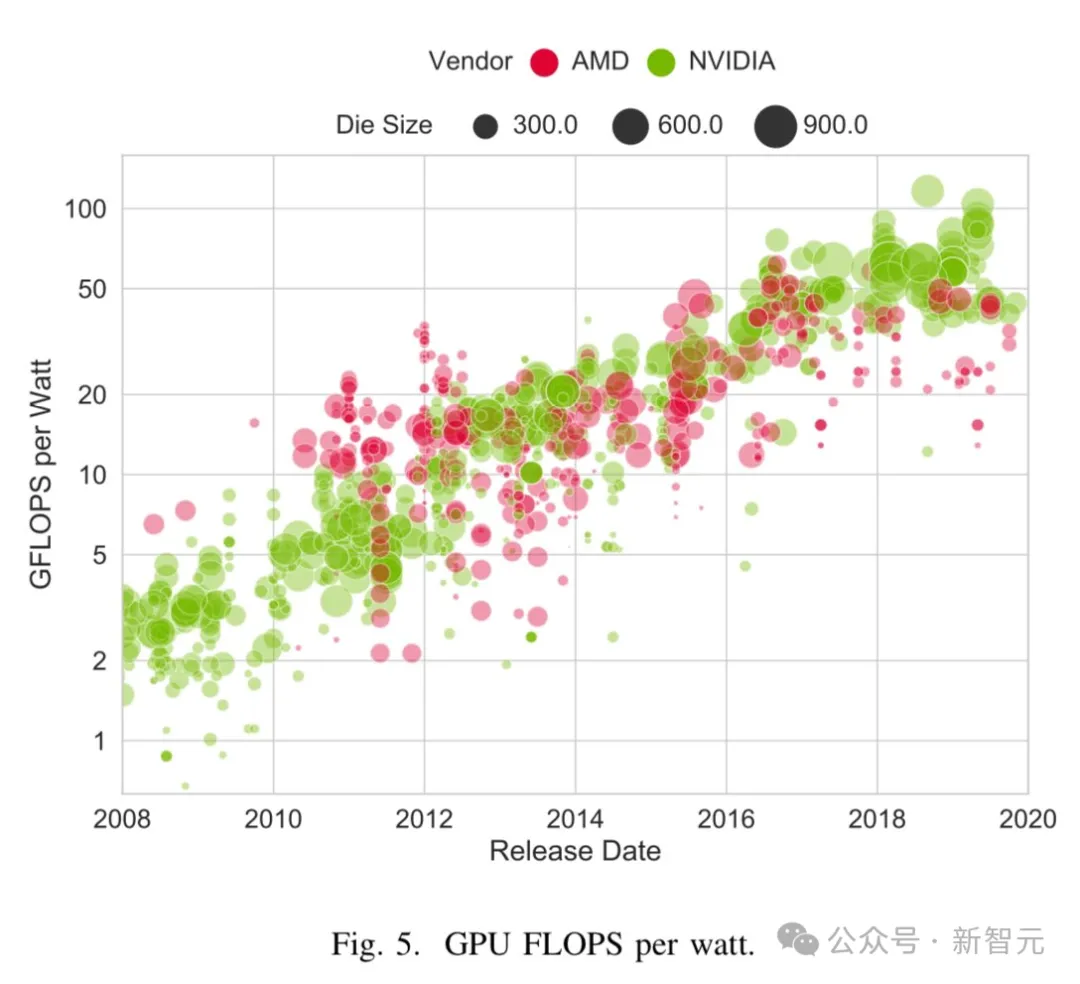
虽然坐拥至少数万块英伟达GPU,但小扎却觉得,单纯把计算集群造大,早晚会遇到边际效应的那一点,感觉有点在内涵Sam Altman。

在采访中,他表示如今世界上最棘手的事情就是:虽然Llama-3的8B比Llama-2 的70B更好,但指数曲线还能持续多久?
尽管如此,他也认为投资100亿美元,甚至1000亿美元,来建设基础设施是值得的,或许会让我们得到一些惊人的东西。
是的,如今GPU的供应限制,已经让很多公司投入大量资金来构建基础设施。
在到达某一点的时候,投入更多资本的性价比就变低了。
而且在到达这一点之前,我们就会遇到能源的限制。因为目前还没人建立过一千兆瓦的单一训练集群。
主持人提问道:如果你有1万亿美元呢?
小扎表示,这还是取决于指数曲线会走多远。
现在的数据中心,规模大概是50兆瓦或100兆瓦,特别大型的能达到150兆瓦。
但300兆瓦、500兆瓦甚至1吉瓦的数据中心,需要花费数年时间才建成,如果是1吉瓦,就需要一个核电厂的能源。

此外,也存在架构瓶颈。
小扎认为,如果持续给Llama-3 70B提供更多数据,或者通过token进行优化,它会持续改进。
不过,我们在此基础上构建的东西,不可能无限进步。
也就是说,小扎基本陷入了渐进主义的陷阱,他不相信GPT-4的性能可以提升100倍,或AGI在短期内能实现。
那该如何衡量,模型创造的价值是否超过了部署成本呢?
总之,放出这种言论的小扎,现在并没有在筹集资金。而Sam Altman、马斯克、Dario Amodei等疯狂筹资的大佬,都预计AI模型能力将大幅提高。

这其中有多少是真实水分,有多少是炒作需要,我们就不得而知了。
只能说,相比之下小扎目前看起来更像个老实人。
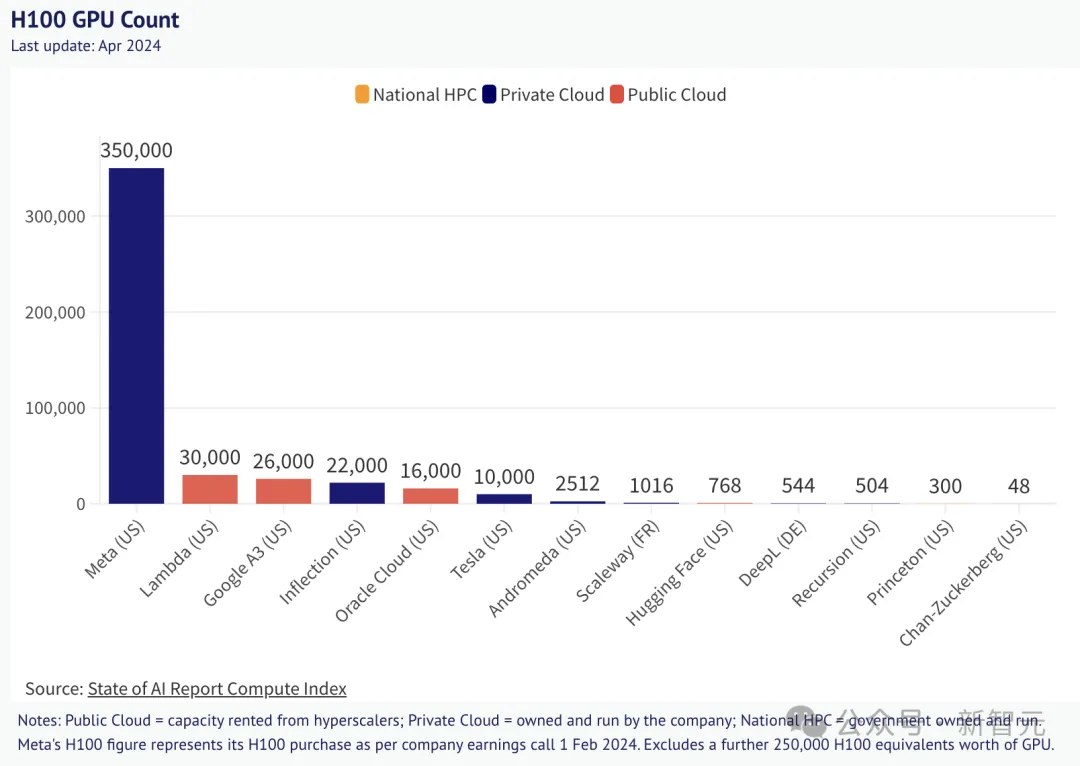
在2022年公司股价遭遇重创之际,小扎还是铤而走险,购买了大批H100。
当年第三季度财报显示,Meta资本支出高达320亿-330亿美元。
其中一部分大多流向数据中心、服务器和网络基础设施构建,以及在元宇宙上的巨额投入。

而现在看来,他好像拥有一种未卜先知的能力。
在采访中,小扎解释道,「当时Meta正大力发展短视频工具Reels,因此需要更多的GPU来训模型」。
「这也是我们提供服务的一次重大转变,我们不再针对你所关注的人或页面的内容进行排名,而是开始大力推荐『非关联内容』的内容」。
也就是说,向用户展示候选内容的语料库,有时会从几千个扩大到数亿个。
若想在这一数量级数据中完成训练推理,就需要一个完全不同的基础设施。
「因此,我们要订购足够多的GPU,以满足我们在Reels、内容排序和信息流等方面的需求。还要额外多购买一倍」。
另外,小扎曾在年初宣布,计划到年底要部署35万块英伟达H100。
他透露了更多的细节,这将是一个非常大的舰队。Meta内部将为训练LLM打造两个单集群,一个配备22,000块H100,另一个集群配备24,000块。
因为模型推理对Meta来说,是至关重要的一件大事,需要为Facebook、Ins等自家应用的用户提供服务。
用小扎的原话来说,就是:
我们所需的推理计算与训练的比率,可能远高于其他从事这一领域的公司,这是因为我们所服务的社区用户量非常庞大。
小扎还提到,对于Llama 3,主要专注于使用大量代码进行训练。在代码中训练模型,有助于其在不同的领域中进行推理。
与此同时,Llama 3是专为工具使用而设计。
「我们的开发者不需要手写所有代码,就可以让模型使用谷歌并进行搜索」。
他还提到了,下一代模型Llama 4将针对智能体行为而打造。
其实,整个AI圈更加期待的是,媲美GPT-4级别的开源模型Llama 3-405B能够发布。
小扎称,4050亿参数的Llama 3将具备更强的多模态能力,支持多种语言,以及更大的上下文窗口,并计划在今年晚些时候推出。
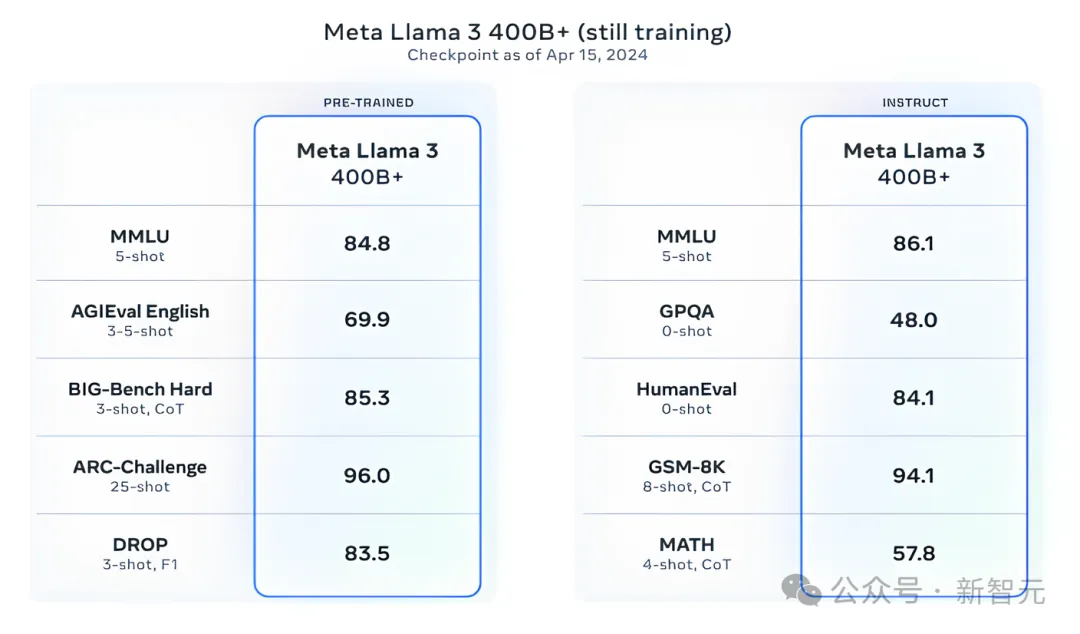
就目前训练结果而言,405B已经在大规模多任务语言理解的基准测试(MMLU)中,取得了大约85分的成绩。
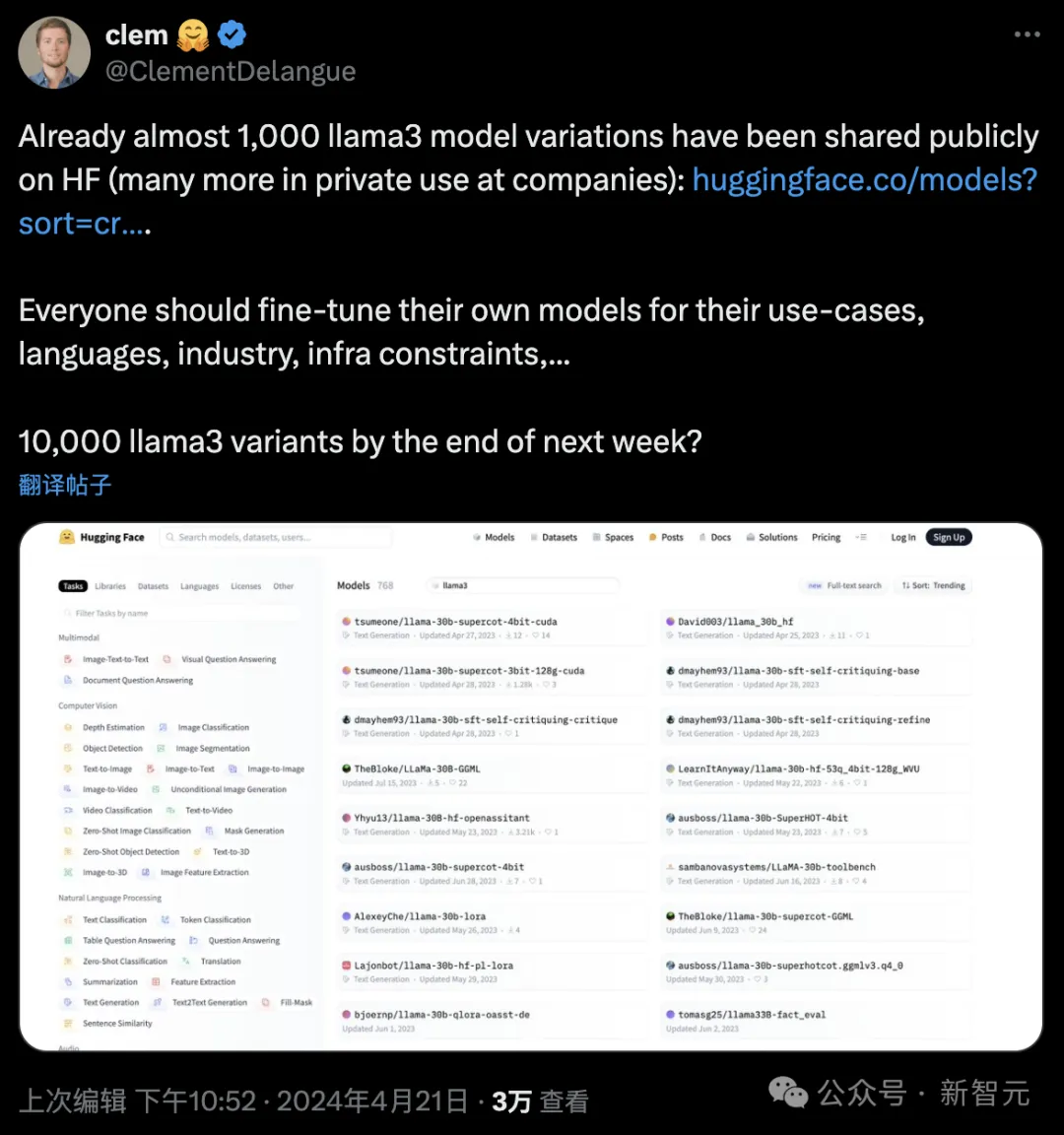
其实Llama3发布三天后,已经有1000个微调模型在Hugging Face上发布。
HF的创始人Clement Delangue非常期待,下周结束前,或许会有1万个开源Llama3变体上线。
其中,网友@meng__shao总结了,截止目前中文的微调模型已达到6个。

目前,最小版本的额Llama-3 8B已经在改变世界,不仅能在消费级设备上运行,还开辟了大量领域的应用。

那么,未来的Llama模型,或许是能够解决用户所有用例的Llama 10发布那天,是否足以取代现实中的程序员?
小扎表示,「我不确定我们是否正在取代人类程序猿,因为Meta正在给人们提供工具来做更多的事情」。
而且衡量人类智力不仅只有单一的阈值,因为每个人都有不同的技能。我认为,在某种程度上,人工智能可能会在大多数方面超过人类,这取决于模型的强大程度。但这个过程,是循序渐进的。

虽然烧了300亿美元不止,但小扎对元宇宙似乎依然没有放弃。
主持人提出了一个尖锐的问题:就是市场对你大加指责,你也要坚定去做元宇宙。这种笃定,究竟来源于什么?是什么样的价值观或直觉,让你如此笃信元宇宙?
小扎表示,自己只是单纯喜欢建造东西。
他喜欢围绕人们的交流、表达和工作来构建产品,这跟他大学时的专业有关。他学的是计算机科学和心理学,而建造元宇宙,就是两门专业的交叉点。
这是一种深刻的内驱力,让他觉得自己如果不做点新东西,就像犯了错一样。
而且,无论身处何处,元宇宙都能让你感受到与人的联结,在小扎看来,这是一个杀手锏。

技术的一个教训是,要尽可能将物理约束领域的东西转移到软件中,因为软件更容易构建和迭代。
不是每个人都有数据中心,但很多人都可以写代码,并且使用和修改源代码。
而元宇宙版本的软件,就是实现现实的数字存在。在社交、沟通、医疗行业等,元宇宙都会作用巨大。
而且,在为AI投资1000亿美元,或者为元宇宙投入巨额资金时,商业计划就能表明:如果产品奏效,这是很好的投资。
即使在生活中,小扎也是这样的。在考爱岛,他建了一个牧场,负责设计所有建筑。
「如果要养出世界上最好的牛,该怎么设计呢?这就是我。」
文章来自微信公众号“新智元”

00:41


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
