# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人物说话的过程中,每一个细微的动作和表情都可以表达情感,都能向观众传达出无声的信息,也是影响生成结果真实性的关键因素。
如果能够根据特定面容来自动生成一段生动逼真的形象,将彻底改变人类与人工智能系统的交互形式,例如改善有障碍患者的交流方式、增强人工智能辅导教育的趣味性、医疗保健场景下的治疗支持和社会互动等。
最近,微软亚洲研究院的研究人员抛出了一个重磅炸弹VASA-1框架,利用视觉情感技巧(VAS,visual affective skills),只需要输入一张肖像照片+一段语音音频,即可生成具有精确唇音同步、逼真面部行为和自然头部运动的超逼真说话面部视频。

从法律角度来看,「视频证据在未来的价值将大大降低」。
但也有网友指出,细看的话,视频也存在瑕疵,例如牙齿的大小一直在变化;但如果不知道这个视频是AI生成的话,不知道还能否分辨出来?
在VASA框架下,首款模型VASA-1不仅能够产生与音频完美同步的嘴唇动作,还能够捕捉大量面部细微差别和自然的头部动作,有助于感知真实性和生动性。
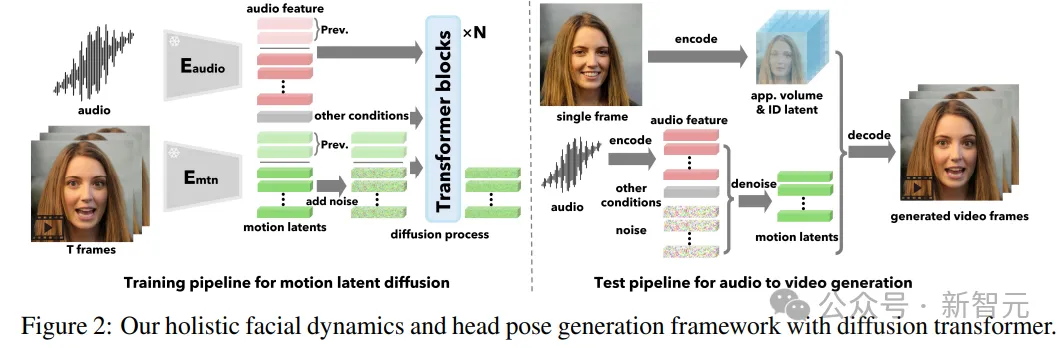
框架的核心创新点为基于扩散的整体面部动力学和头部运动生成模型,以及使用视频来开发出这种富有表现力和解耦的面部潜空间(disentangled face latent space)。
研究人员还使用了一组全新的指标对模型能力进行评估,结果表明该方法在各个维度上都显著优于之前的方法,可以提供具有逼真面部和头部动态的高质量视频,还支持以高达40 FPS的帧速率实时生成512×512视频,启动延迟可忽略不计。
可以说,VASA框架为模拟人类对话行为中,使用逼真化身进行实时互动铺平了道路。
一个好的生成视频应该具备几个关键点:高保真度、图像帧的清晰度和真实性、音频和嘴唇动作之间的精确同步、表情和情感的面部动态,以及自然的头部姿势。

模型在生成过程可以接受一组可选的控制信号来指导生成,包括主眼凝视方向、头部到相机的距离和情绪偏移等。
VASA模型并不是直接生成视频帧,而是在音频和其他信号的条件下,在潜空间中生成整体的面部动态和头部运动。
给定运动潜码后,VASA使用面部编码器从输入图像中提取的外观和身份特征作为输入,然后生成视频帧。
研究人员首先构建了一个人脸潜空间,并使用现实生活中的人脸视频对人脸编码器和解码器进行训练;然后再训练一个简单的扩散Transformer对运动分布进行建模,针对测试期间的音频和其他条件下,生成运动潜码。
1. 表情和解耦面部潜空间构建(Expressive and Disentangled Face Latent Space Construction)
给定一组未标注的说话人脸视频,研究人员的目标是建立一个具有高度解耦和表现力的人脸潜空间。
在主体身份改变的情况下,解耦可以对视频中的人脸和整体面部行为进行高效的生成建模,还可以实现对输出的解耦因子控制,相比之下,现有方法要么缺乏表现力,要么缺乏解耦。
另一方面,面部外观和动态运动的表情可以确保解码器能够输出具有丰富面部细节的高质量视频,潜生成器能够捕捉细微的面部动态。
为了实现这一点,VASA模型建立在3D辅助人脸再现(3D-aid face reenactment)框架的基础上,与2D特征图相比,3D外观特征体积可以更好地表征3D中的外观细节,其在建模3D头部和面部运动方面也很强大。
具体来说,研究人员将面部图像分解为规范的3D外观体积、身份编码、3D头部姿势和面部动态编码,每个特征都由独立的编码器从人脸图像中进行提取,其中外观体积需要先通过提取姿势三维体积,再将刚性和非刚性三维扭曲到规范体积来构建得到。
解码器将上述潜变量作为输入,并重建面部图像。
学习解耦潜空间的核心思想是,通过在视频中不同图像之间交换潜变量来构建图像重建损失,但原版模型中的损失函数无法很好地区分「面部动态」和「头部姿势」,也无法识别「身体」和「运动」之间的关联性。
研究人员额外添加了成对的头部姿势和面部动态来传递损失,以改善解耦效果。
为了提升身份和运动之间的纠缠,损失函数中引入了面部身份相似性损失。
2. 基于扩散Transformer的整体人脸动态生成(Holistic Facial Dynamics Generation with Diffusion Transformer)
给定构建的人脸潜空间和训练的编码器,就可以从现实生活中的人脸视频中提取人脸动态和头部运动,并训练生成模型。
最关键的是,研究人员考虑了身份不可知的整体面部动态生成(HFDG),学习到的潜编码代表所有面部运动,如嘴唇运动、(非嘴唇)表情、眼睛凝视和眨眼,与现有方法中「使用交错回归和生成公式对不同因素应用单独的模型」形成了鲜明的对比。
此外,之前的方法通常基于有限的身份进行训练,不能对不同人类的广泛运动模式进行建模,特别是在具有表现力的运动潜空间的情况下。
在这项工作中,研究人员利用音频条件下的HFDG的扩散模型,在来自大量身份的大量谈话人脸视频上进行训练,并将Transformer架构应用于序列生成任务。
3. Talking Face视频生成
在推断时,给定任意的人脸图像和音频片段,首先使用训练的人脸编码器提取3D外观体积和身份编码;然后提取音频特征,将其分割成相同长度的片段,并使用训练的扩散Transformer以滑动窗口的方式逐个生成头部和面部运动序列;最后使用训练后的解码器生成最终视频。
研究人员使用公开的VoxCeleb2数据集,包含大约6000名受试者的谈话面部视频,并重新处理数据集并丢弃「包含多个人物的片段」和低质量的片段。
对于motion latent生成任务,使用embedding尺寸为512、头编号为8的8层Transformer编码器作为扩散网络。
模型在VoxCeleb2和收集的另一个高分辨率谈话视频数据集上进行训练,该数据集包含约3500个受试者。
可视化结果
通过视觉检查,我们的方法可以生成具有生动面部情绪的高质量视频帧。此外,它可以产生类似人类的对话行为,包括在演讲和沉思过程中眼睛凝视的偶尔变化,以及眨眼的自然和可变节奏,以及其他细微差别。我们强烈建议读者在线查看我们的视频结果,以充分了解我们方法的功能和输出质量。
生成可控性
在不同控制信号下生成的结果,包括主眼凝视、头部距离和情绪偏移,生成模型可以很好地解释这些信号,并产生与这些特定参数密切相关的人脸结果。

当将相同的运动潜在序列应用于不同的受试者时,方法有效地保持了不同的面部运动和独特的面部特征,表明了该方法在解耦身份和运动方面的有效性。

下图进一步说明了头部姿势和面部动态之间的有效解耦,通过保持一个方面不变并改变另一个方面,得到的图像忠实地反映了预期的头部和面部运动,而不会受到干扰,展示了处理训练分布之外的照片和音频输入的能力。

模型还可以处理艺术照片、歌唱音频片段(前两行)和非英语演讲(最后一行),并且这些数据变体不存在于训练数据集中。

下表给出了VoxCeleb2和OneMin-32基准测试的结果。
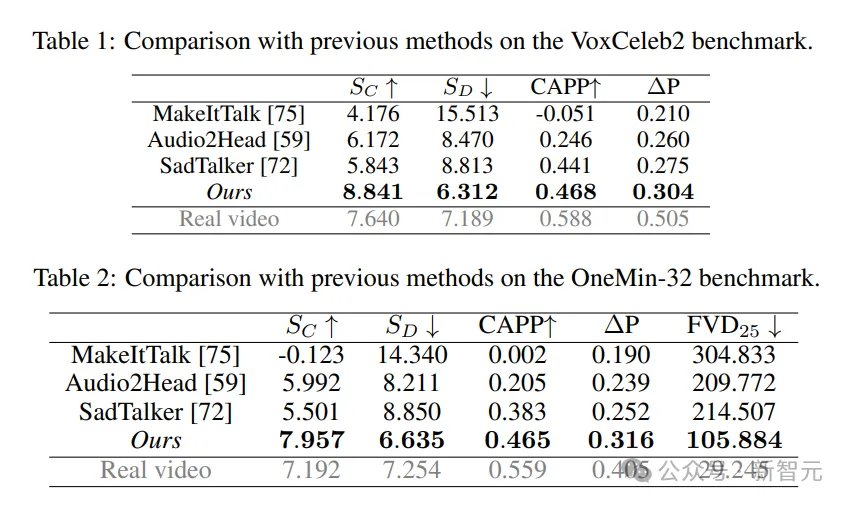
在这两个基准测试中,该方法在所有评估指标上都取得了所有方法中最好的结果。
在音频嘴唇同步分数(SC和SD)方面,该方法远远优于其他方法,比真实视频产生更好的分数,是由于音频CFG的影响。
从CAPP分数上反映的结果来看,模型生成的姿势与音频的匹配效果更一致,尤其是在OneMin-32基准上。
根据∆P,头部运动也表现出最高的强度,但仍然与真实视频的强度仍有差距;并且FVD得分明显低于其他模型,表明该结果具有更高的视频质量和真实性。
文章来自微信公众号“新智元”



