# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上周,微软空降了一个堪称GPT-4级别的开源模型WizardLM-2。
却没想到发布几小时之后,立马被删除了。
有网友突然发现,WizardLM的模型权重、公告帖子全部被删除,并且不再微软集合中,除了提到站点之外,却找不到任何证据证明这个微软的官方项目。
GitHub项目主页已成404。
包括模型在HF上的权重,也全部消失了.....
全网满脸疑惑,WizardLM怎么没了?

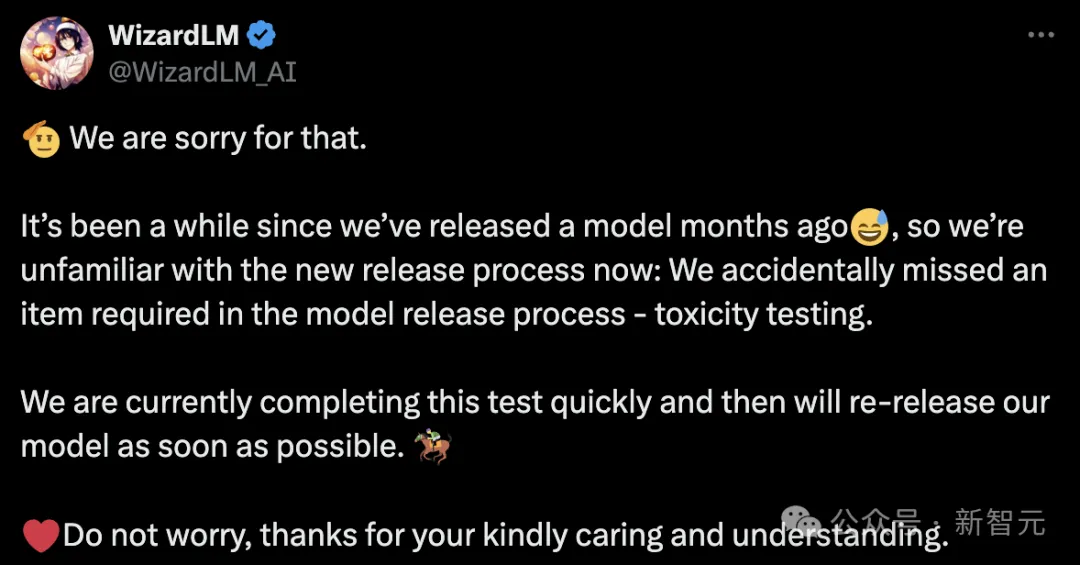
然鹅,微软之所以这么做,是因为团队内部忘记对模型做「测试」。
随后,微软团队现身道歉并解释道,自几个月前WizardLM发布以来有一段时间,所以我们对现在新的发布流程不太熟悉。
去年6月,基于LlaMA微调而来的初代WizardLM一经发布,吸引了开源社区一大波关注。

随后,代码版的WizardCoder诞生——一个基于Code Llama,利用Evol-Instruct微调的模型。
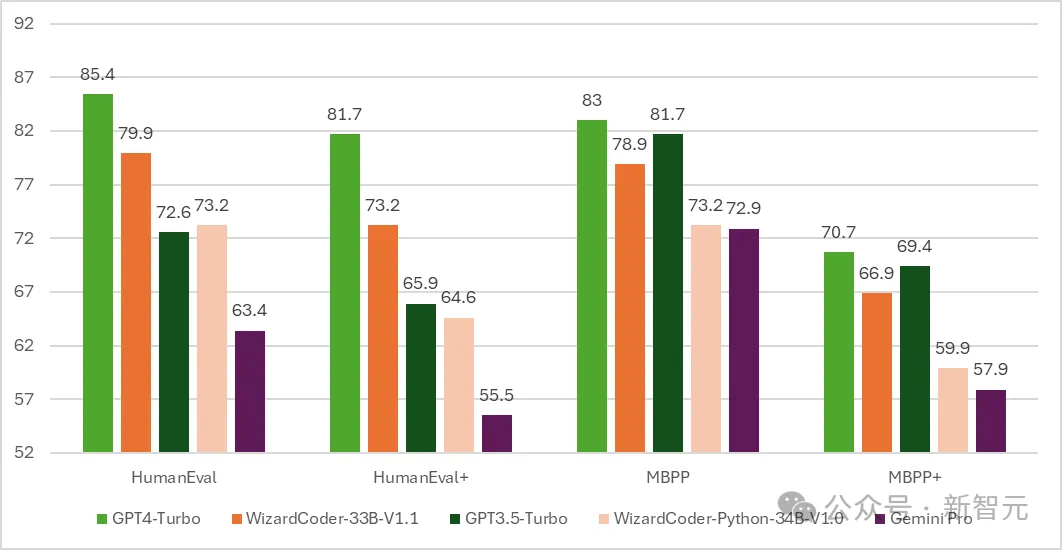
测试结果显示,WizardCoder在HumanEval上的pass@1达到了惊人的 73.2%,超越了原始GPT-4。
时间推进到4月15日,微软开发者官宣了新一代WizardLM,这一次是从Mixtral 8x22B微调而来。
它包含了三个参数版本,分别是8x22B、70B和7B。

最值得一提的是,在MT-Bench基准测试中,新模型取得了领先的优势。
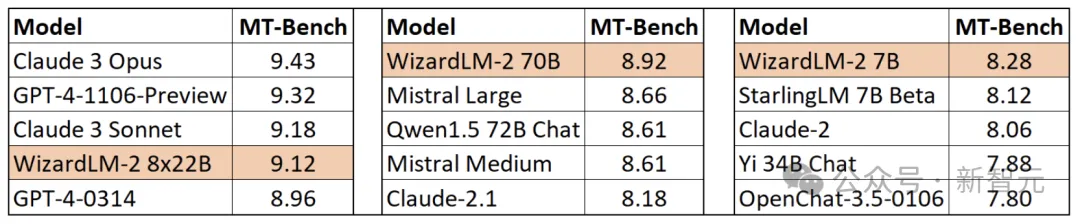
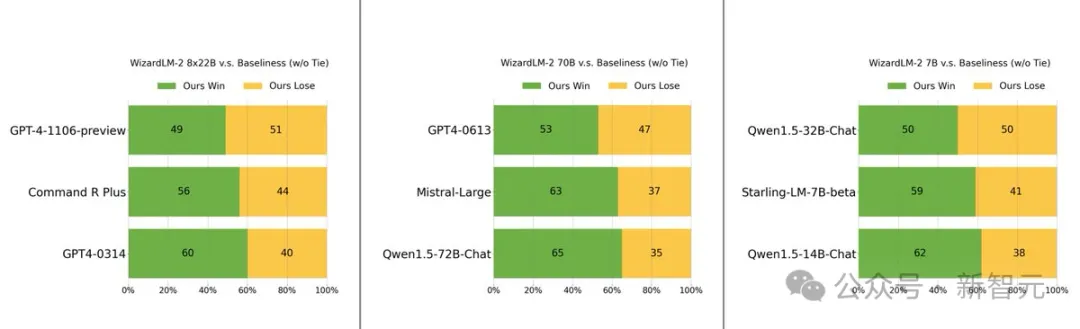
具体来说,最大参数版本的WizardLM 8x22B模型性能,几乎接近GPT-4和Claude 3。
在相同参数规模下,70B版本位列第一。
而7B版本是最快的,甚至可以达到与,参数规模10倍大的领先模型相当的性能。
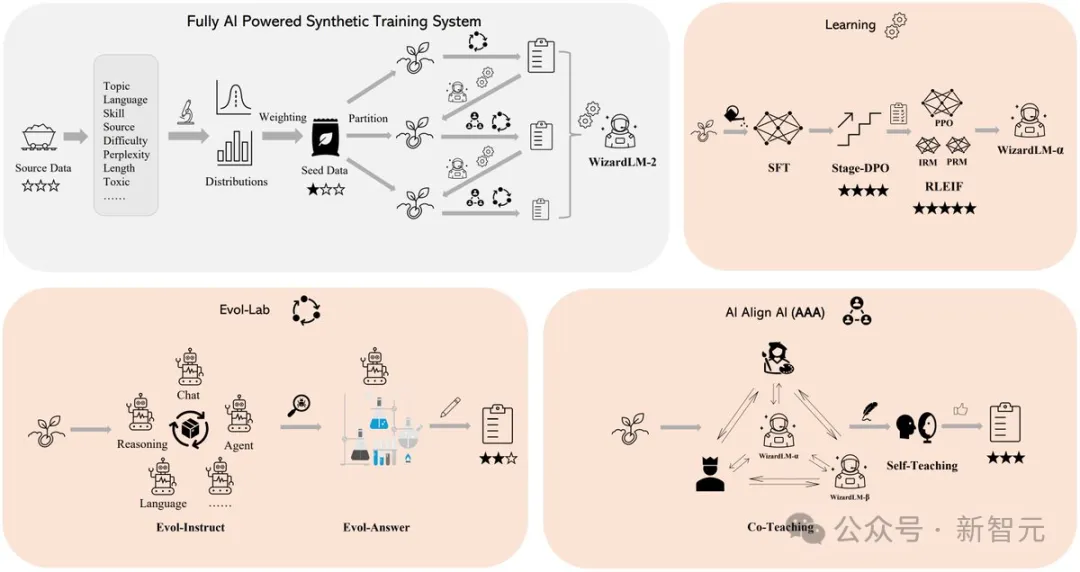
WizardLM 2出色表现的背后的秘诀在于,微软开发的革命性训练方法论Evol-Instruct。
Evol-Instruct利用大型语言模型,迭代地将初始指令集改写成越来越复杂的变体。然后,利用这些演化指令数据对基础模型进行微调,从而显著提高其处理复杂任务的能力。
另一个是强化学习框架RLEIF,也在WizardLM 2开发过程中起到了重要作用。
在WizardLM 2训练中,还采用了AI Align AI(AAA)方法,可以让多个领先的大模型相互指导和改进。
AAA框架由两个主要的组件组成,分别是「共同教学」和「自学」。
共同教学这一阶段,WizardLM和各种获得许可的开源和专有先进模型进行模拟聊天、质量评判、改进建议和缩小技能差距。

通过相互交流和提供反馈,模型可向同行学习并完善自身能力。
对于自学,WizardLM可通过主动自学,为监督学习生成新的进化训练数据,为强化学习生成偏好数据。
这种自学机制允许模型通过学习自身生成的数据和反馈信息来不断提高性能。
另外,WizardLM 2模型的训练使用了生成的合成数据。
在研究人员看来,大模型的训练数据日益枯竭,相信AI精心创建的数据和AI逐步监督的模型将是通往更强大人工智能的唯一途径。
因此,他们创建了一个完全由AI驱动的合成训练系统来改进WizardLM-2。
然而,在资料库被删除之前,许多人已经下载了模型权重。
在该模型被删除之前,几个用户还在一些额外的基准上进行了测试。
好在测试的网友对7B模型感到印象深刻,并称这将是自己执行本地助理任务的首选模型。

还有人对其进行了投毒测试,发现WizardLM-8x22B的得分为98.33,而基础Mixtral-8x22B的得分为89.46,Mixtral 8x7B-Indict的得分为92.93。
得分越高越好,也就是说WizardLM-8x22B还是很强的。

如果没有投毒测试,将模型发出来是万万不可的。
大模型容易产生幻觉,人尽皆知。
如果WizardLM 2在回答中输出「有毒、有偏见、不正确」的内容,对大模型来说并不友好。
尤其是,这些错误引来全网关注,对与微软自身来说也会陷入非议之中,甚至会被当局调查。

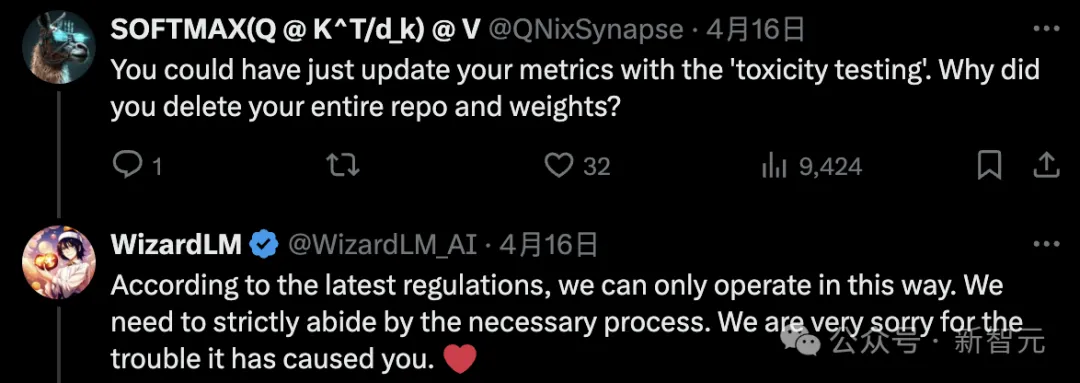
有网友疑惑道,你可以通过「投毒测试」更新指标。为什么要删除整个版本库和权重?
微软作者表示,根据内部最新的规定,只能这样操作。
还有人表示,我们就想要未经「脑叶切除」的模型。

不过,开发者们还需要耐心等待,微软团队承诺,会在测试完成后重新上线。
文章来自微信公众号“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
