# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。语料规模和质量对大模型性能以及应用的深度、广度有着至关重要的影响。当前行业大模型训练语料存在覆盖面不全、准确性不足、时效性不够等问题,导致大模型通常难以达到预期目标。实践经验表明,即使模型参数量级有所下降,只要数据语料质量足够高,其表现依然不俗。
为进一步提升大模型在行业的应用范围和应用成效,需统筹行业力量搭建社区平台,拓宽语料来源,构建语料标准规范,开展语料治理,保障语料安全,为大模型训练及应用提供满足业务场景需求,具备行业特性和标准化的高质量语料。
行业大模型语料是指用于训练垂直领域大模型的数据集,通常包含自然科学、社会科学等通用语料和行业专用语料。以证券期货行业为例,行业专用语料包括财经新闻、财务报告、法规文件、公开的交易数据等。通过收集和整理语料,可以训练大模型理解和生成行业特定概念和知识,支持行业分析、预测和辅助决策等智能任务。
(一)通用语料
引入百科、书籍等通用语料,可使大模型在执行行业特定任务时,减少对专业术语误解的风险(如专业术语的非专业用法、术语的双关语、与特定行业无关的上下文等),并且在面对跨领域的查询或交流时,能提供更为准确和自然的响应。
(二)行业专用语料
引入行业专用语料,旨在丰富大模型对于行业特有词汇、表达方式以及特定知识的理解,使模型能够针对性地处理行业相关的复杂查询,执行精准的数据分析,以及更有效地支持辅助决策。此外,基于行业专用语料训练的大模型在进行风险评估、预测、合规性检查等任务时,能展现出更高的可靠性和适用性。
通常行业管理部门、经营机构以及信息技术服务商都会建设自身语料库。一方面满足行业知识整理、业务研究、合规风控等自身需求,另一方面可进一步加工成全新的数据资产、研究报告等,对外进行服务。不同的机构在语料库建设方面的现状以及面临的问题均有所不同,且呈现出自身的特点。
(一)行业管理部门
管理部门在构建语料库的工作中,挑战主要在于数据集的规范和数据标准化,这是知识整理的基础。其语料库建设存在以下问题:1.数据分散:许多重要的数据散落在各业务系统中,重要信息和专家经验无法得到有效沉淀,数据共享存在壁垒。2.数据异构:日常积累的大量文本数据,来自于不同的部门和层级,格式、结构和内容不尽相同。3.数据敏感:管理部门数据通常涉及大量敏感信息,在处理和存储过程中必须确保安全合规。
(二)行业经营机构
经营机构语料库涉及海量的结构化及非结构化数据,挑战主要在于如何深度挖掘,以支持决策分析和客户服务。其语料库建设存在以下问题:1.处理难度大:来源于多渠道的经营和交易数据,格式、标准均不相同且模态多样,难以有效整合。2.加工深度浅:经营机构的语料库建设仅停留在表层信息,尚不涉及深层的语义理解和深度分析。3.隐私保护难:大模型语料涉及商业秘密及客户敏感信息,在训练和使用过程中经营机构须做好合规风控。
(三)信息技术服务商
信息技术服务商擅长整合通用语料,在配合构建行业语料库时面临的主要挑战是专业能力和服务质量。1.专业能力:信息技术服务商对行业语料的分类、分析和解读需要行业知识,其专业能力严重影响语料库的应用价值。2.服务质量:行业语料库建设是一项持续迭代的工作,需要信息技术服务商提供长期的高质量服务。
此外,合成数据也是大模型训练重要数据来源,在降低成本、提升数据质量、规避隐私问题等方面具有优势。如何探索行业数据合成的有效路径,是行业语料库建设的重大课题。
行业语料库的构建与治理对于发展行业大模型,激活数据要素价值尤为关键。一个结构良好、内容优质、管理规范的语料库可以为行业参与者提供具备深度洞察力的知识库,促进行业数字化转型和高质量发展。具备公信力的语料库需要行业共建共享,客观上助推行业语料社区的建设和公共服务的发展。
(一)高质量的语料库是行业大模型落地等创新的基础
语料决定了模型的训练质量、性能表现以及应用领域的广度与深度。语料库建设除了考虑质量维度,还需关注开放程度。建设统一、开放、标准的行业大模型语料库,有利于提高行业语料的利用效率和价值,促进行业大模型的训练开发,加速大模型的落地应用。
(二)高质量的语料库是行业数字化转型的重要抓手
高质量语料应具备大规模、多样性、真实性、连贯性、合法性和无偏见等特点。目前行业高质量语料相对缺乏,推动其建设是实现信息化向数字化、智能化转型的重要之举。
(三)高质量的语料库是激活数据要素价值,破除数据壁垒的有效手段
大模型语料通常需要跨机构、宽口径数据,可能会涉及数据安全、隐私保护、知识产权等问题。可探索第三方数据托管等方式,以激活数据要素价值,有效解决跨机构数据共享问题。
建设具备公信力的行业大模型语料库是一项长期性、专业性的系统性工程,涵盖基础设施、公共服务平台、行业规范标准、激励机制等方面。在建设方法、实现路径上需形成合力,多措并举,久久为功(见图)。
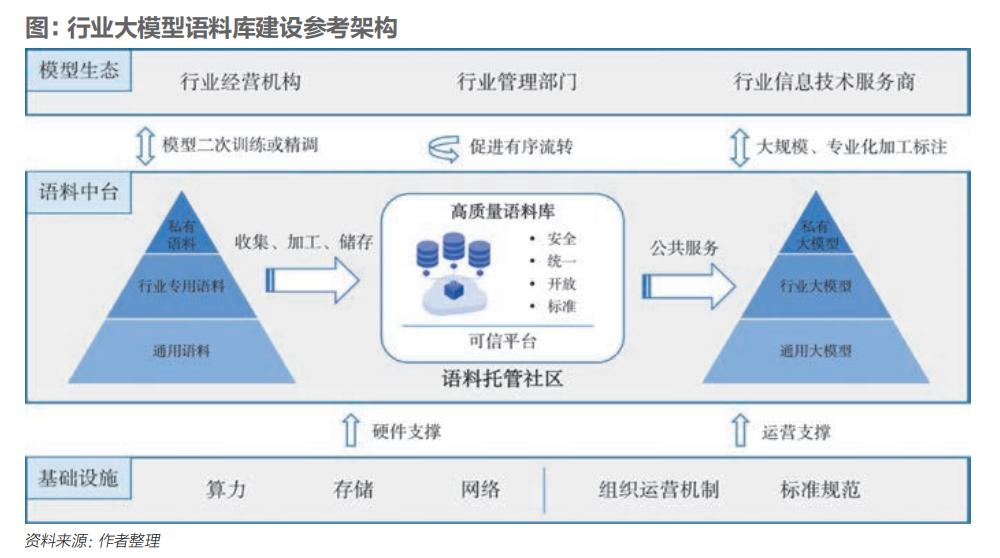
(一)充分借鉴通用语料库的成果和经验
国际通用语料库,如国外的The Pile、C4、Wikipedia(维基百科)等数据集,以及国内的“书生·万卷”多模态预训练语料、中国网络空间安全协会发布的中文通用语料,都可作为建设行业大模型语料库的基础。为了扩大通用语料库资源,要兼顾自立自强和对外开放,可考虑对Wikipedia、Reddit(美国娱乐、社交及新闻网站)等特定数据源建立过滤后的境内镜像站点,供国内数据处理者使用。
(二)聚焦语料的供给、托管、加工、安全与评测
实践经验表明,基于行业语料库,重新训练通用大模型,通用语料和专业语料规模配比通常约为1:1。因此,融合汇聚行业专用语料,加大语料供给,是行业大模型建设的前提。
一种有效思路是建设数据社区,探索基于可信机构或基于可信技术的平台,为数据主体提供托管服务。行业机构可利用托管数据,基于行业大模型做二次训练或精调,以提升私有模型能力。托管的语料资产也可在社区范围内有偿交易,有序流转。
语料加工处于大模型训练开发的上游环节,直接影响语料库生产速度、适用范围与质量水平。数据加工,特别是数据标注已形成产业化,行业信息技术服务商可在数据社区进行大规模、专业化数据加工与标注工作,促进行业语料库的建设与规范。
语料安全是建设行业语料库的“红线”。要加强监督,保障入库数据内容合规、权益清晰。要完善法律法规,优化政策制度,以多种途径与方式形成监管合力,严防恶意篡改模型和渗入有害数据等行为。探索利用基于人类反馈的强化学习(RLHF)和可扩展监督(Scalable Oversight)等技术方法,保证大模型的输出符合人类价值观,防止大模型生成有害内容。
(作者为中国证监会科技监管司司长,本文仅代表个人学术观点,不代表所在机构意见;编辑:张威;本文首发于2024年4月22日出版的《财经》杂志)
题图来源 | pexels
本文来自微信公众号“财经五月花”(ID:Caijing-MayFlower),作者:姚前



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
