# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Llama 3诞生整整一周后,直接将开源AI大模型推向新的高度。
Meta官方统计显示,模型下载量已突破120万次,在最大开源平台HF上已经有600+微调的Llama 3变体。
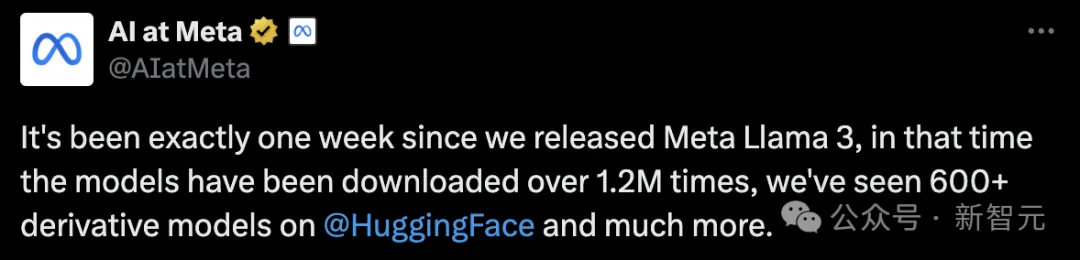
更值得一提的是,Llama 3 70B指令微调版已在大模型Chatbot Arena排行榜上并列第一(英语),总体榜单位列第六,并在多个基准测试上的表现均大幅超过已有竞品。
可见,Llama 3已经成为AI应用的最新优选。
问题来了,想要动手微调测试Llama 3,如何用?
最新安利来了!
最近,小编无意发现潞晨云上的算力价格非常便宜,比如H800-80GB-NVLINK只需5.99元/卡时,而4090甚至低至1.99元/卡时。
与此同时,还会附赠免费的测试代金券。


一通测试下来,小编们发现不仅便宜,而且非常方便好用和功能丰富。
最关键的是,它还有配套的从推理到微调和预训练的实践教程。
体验地址在这里:https://cloud.luchentech.com/
据介绍,在64卡H100集群上,经过潞晨Colossal-AI优化,相比微软+英伟达方案,可提升Llama 3 70B的训练性能近20%,推理性能也优于vLLM等方案。
想体验Llama 3等AI任务,还需要有GPU等算力支持。目前主流的AI云主机有AWS、AutoDL、阿里云等。但GPU资源不仅昂贵稀缺,供应商普遍还要求使用者必须预先进行高额投入,按年或提前数个月预付定金。
潞晨云不仅提供了便捷易用的AI解决方案,还为力求为广大AI开发者和其他提供了随开随用的廉价算力:
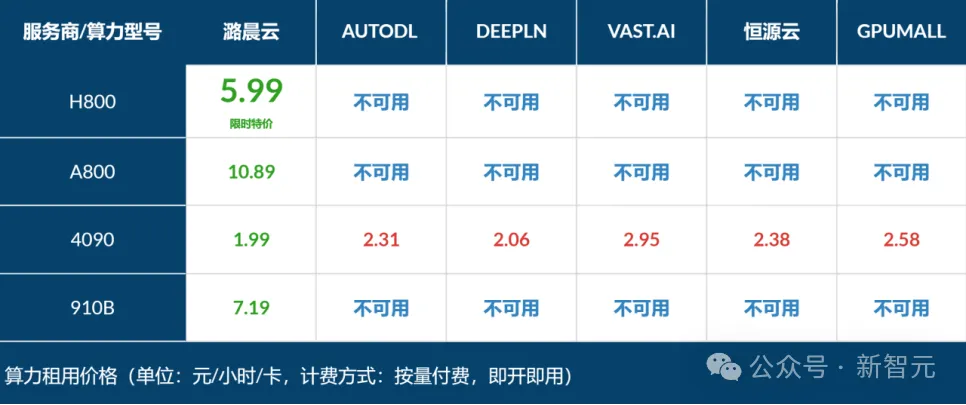
原价19.99元/卡时的H800-80GB-NVLINK,限时特供低至5.99元/卡时!
对于使用较稳定的长期需求,在潞晨云还可以按月、按年租用,获得进一步折扣。
潞晨云还为新用户准备了多种形式的优惠代金券活动,注册即可白嫖H800、A800、4090、910B等高端算力,构建属于自己的AI大模型!(新注册用户自动获得代金券额度)
手把手教你部署和训练Llama 3
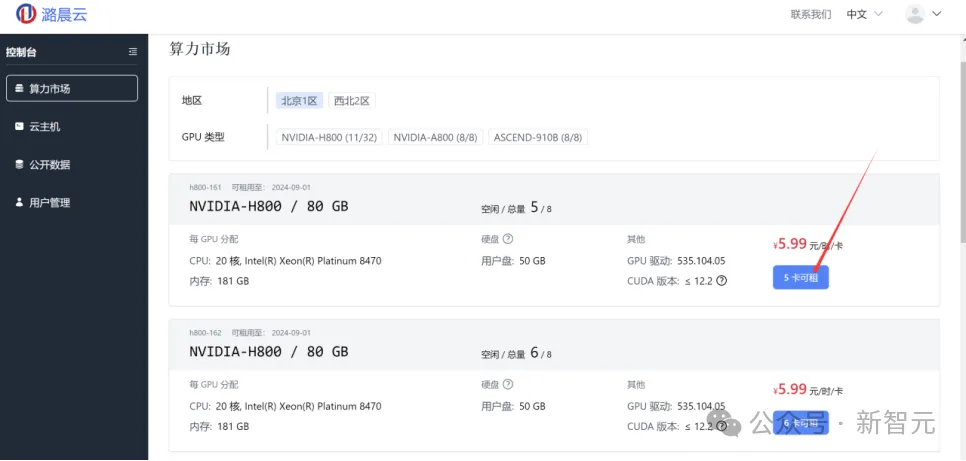
可以看到如图所示的控制台页面,右边是两台可用的服务器,每台上有8块可租用的GPU,我们选择一个,点击「8卡可租」按钮,进入算力市场界面。
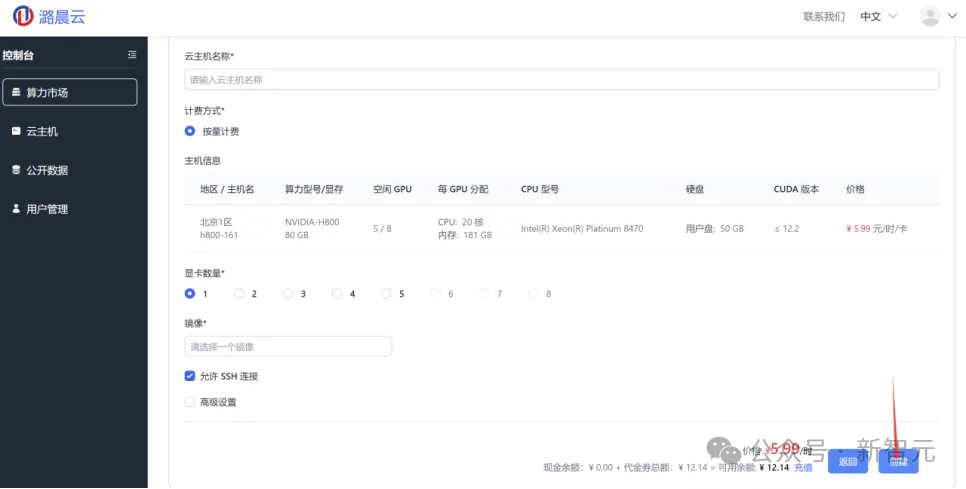
在租用配置选择界面,为自己的云主机取一个名字并选择任务所需数量的显卡,Llama 3 8B推理可以在单卡H800上完成),因此,此处选择1卡H800。
Colossal-Inference现已适配支持了Llama 3推理加速。在潞晨云,你可以选择推理镜像,使用Colossal-Inference进行推理优化提速,体验Llama 3的自然语言生成能力。
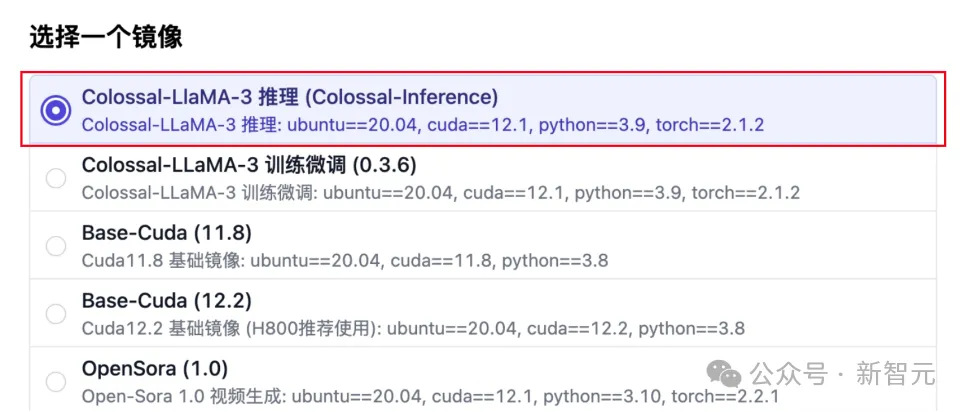
Llama 3模型权重已准备好,无需额外安装步骤。
运行生成脚本
进行多卡TP推理,如下例使用两卡生成
运行吞吐Benchmark测试
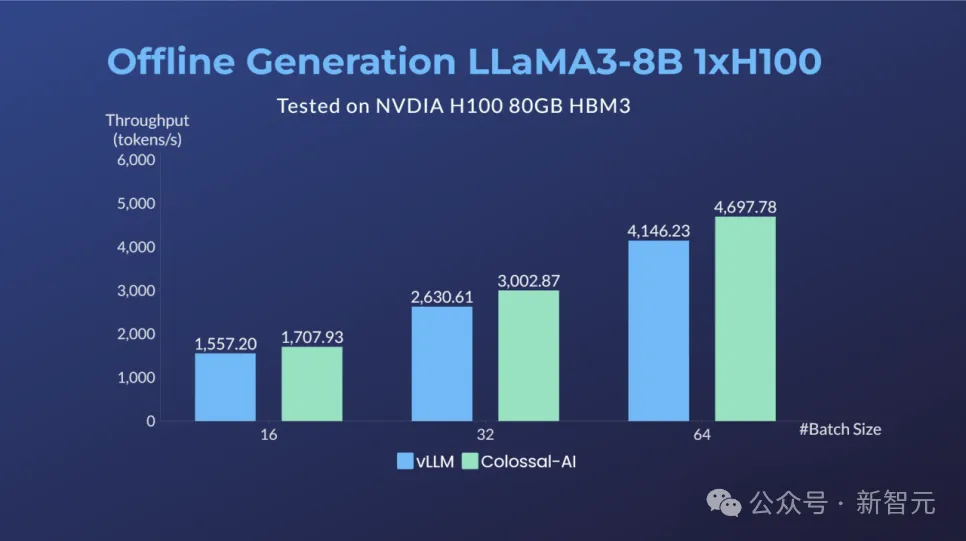
单卡H100对Llama 3-8B进行Benchmark结果与vLLM对比(例:输入序列长度128,输出长度256)
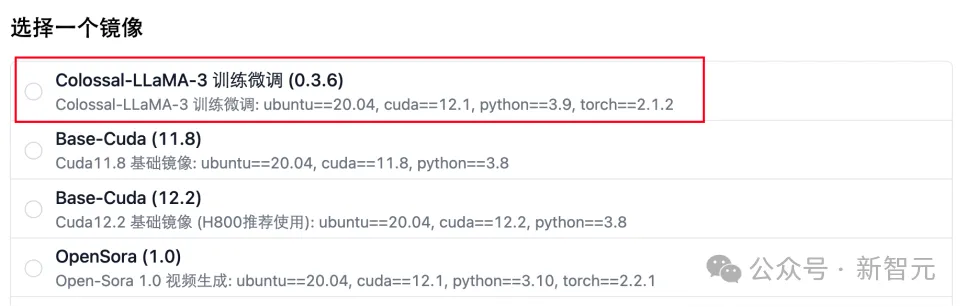
潞晨云在原有 Llama 2 汉化项目中,支持了 Llama 3 的继续预训练与微调。在这里,你可以通过选择训练镜像,快速对 Llama 3 进行继续预训练与微调。
1. 编译安装 Colossal-AI
2. 创建训练需要的文件夹
3. 修改 hostfile
注:可通过 apt install iproute2 -y 在镜像中安装 ip addr 指令查看镜像内 ip 地址
当前路径:/root/ColossalAI/applications/Colossal-LLaMA/
1. 继续预训练
2. 微调
运行成功后,data_output_dirs 文件夹内会自动生成 3 个子文件夹,其中,arrow 文件夹中的数据可用来直接训练。
此外,潞晨云还提供了简单数据集以供测试,处理好数据集可见:/root/notebook/common_data/tokenized-cpt-data
当前路径:/root/ColossalAI/applications/Colossal-LLaMA/
1. 修改 config 文件
2. 参考训练脚本
对于大规模预训练等场景,结合Llama 3 序列变长、embedding增大等特性,潞晨云针对3D混合并行场景进行了优化,通过自定义流水线切分、gradient checkpoint策略,可以进一步精细化控制每个GPU的内存占用和速度,从而达到整体训练效率的提升。
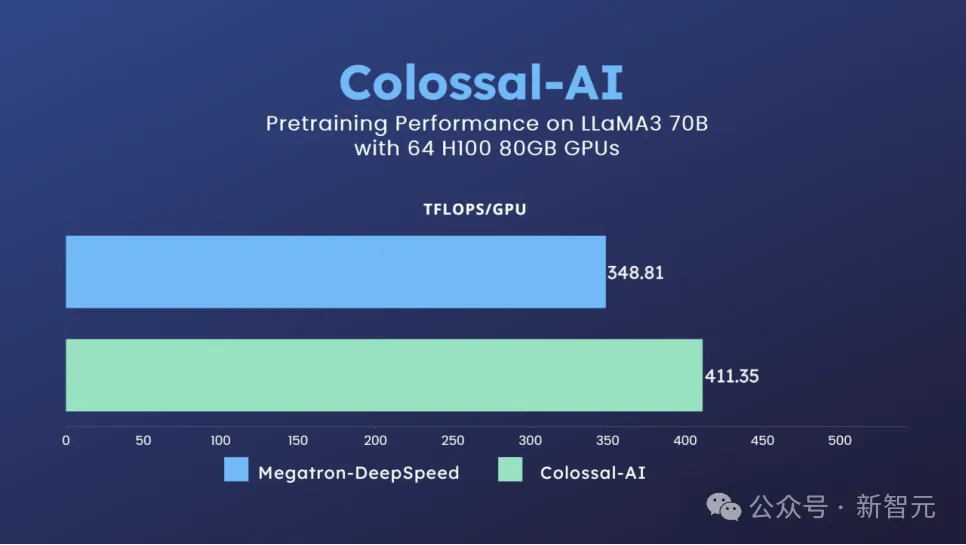
潞晨云使用整数线性规划搜索出在64x H100上最适合Llama 3 70B的切分、gradient checkpoint策略,最终训练可以达到每卡410+ TFLOPS的卓越性能。
详情可参考:https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/llama
此例子附上了潞晨云测试时使用的配置。使用方法如下:
欢度五一,百万福利大放送!羊毛速薅
潞晨云已准备首期百万元的代金券,后续还会不断放出,可以持续关注!
本文来自微信公众号“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
