算力革命与云厂商三重进化:Agent云的架构升级与“度量衡革命”
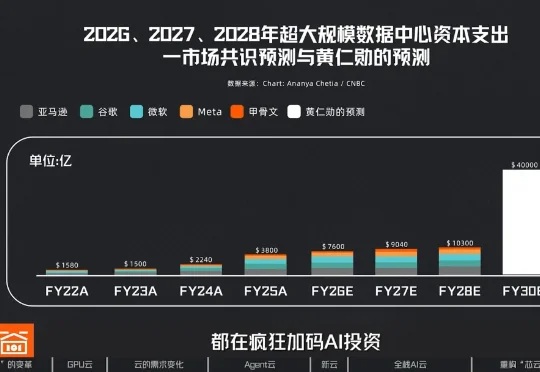
算力革命与云厂商三重进化:Agent云的架构升级与“度量衡革命”随着Agent开始走进各大企业“干活”,AI时代的算力服务,正在变成竞争最激烈的领域。存储、光模块、高速互联等AI基础设施板块持续走强。前几年一度被边缘化的CPU,又重新成为了市场关注的焦点。CoreWeave、Nebius等一批NeoCloud公司快速崛起。微软、谷歌、亚马逊等云巨头都在疯狂加码AI投资。
来自主题: AI资讯
8192 点击 2026-07-24 08:54