# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2024 年 4 月 20 日,即 Meta 开源 Llama 3 的隔天,初创公司 Groq 宣布其 LPU 推理引擎已部署 Llama 3 的 8B 和 70B 版本,每秒可输出token输提升至800。
2024 年 2 月,初创公司 Groq 展示了其 LPU 处理器对大语言模型任务提供的超高速推理的支持。彼时,Groq的 LPU 已能够实现每秒能输出 500 个 token,比英伟达的GPU快10倍,而成本仅为 GPU 的 10%。
4 月 20 日,即 Meta 开源 Llama 3 的隔天,初创公司 Groq 宣布其 LPU 推理引擎已部署 Llama 3 的 8B 和 70B 版本,每秒可输出token输提升至800,引起社区热议。
根据 Groq 官方在 2 月发布的 Demo 演示,基于其自研的 LPU 上运行的开源模型 Mixtral 能够在 1 秒内回复包含数百个单词的事实性的、引用的答案(其中四分之三的时间用来搜索)。
据悉,Groq 模型目前可在 Mixtral 8x7B SMoE 和 Llama2 7B 上运行,每100 万 token 价格为 0.27 美元。其在Mixtral 8x7B SMoE 可以达到 480 token / S,极限情况下,用 Llama2 7B 甚至能实现 750 token / S。
有网友对比了 Groq、GPT-4 和 Genimi 在简单代码调试问题上的耗时,Groq 的速度比 Gemini 快 10 倍,比 GPT-4 快 18 倍。其中:
参考 Groq 公开的资料, LPU(语言处理单元)是一种专为计算密集型应用设计的端到端处理单元系统,尤其适用于需要处理序列数据的应用程序,如大型语言模型(LLM)。
LPU 采用了一种商用、可扩展的张量流处理器架构,它通过独特的设计实现了在单个芯片上并行处理大量张量操作的能力。与传统 GPU 所采用的 SIMD(单指令、多数据)模型不同,LPU 架构采用更精简的方法,减少了对复杂调度硬件的需求。
这种设计优化了每个时钟周期的利用效率,确保了一致的延迟和吞吐量。LPU 在执行深度学习模型,如 Transformer 架构时,能够实现高效的数据流处理。
此外,LPU 的能源效率表现优于 GPU,因为它减少了管理多线程的开销,并避免了核心利用率不足的问题,从而提供了更多的每瓦计算量。LPU 的架构还支持将多个 TSP(张量流处理器)连接在一起,避免了 GPU 集群中常见的瓶颈问题,展现出极高的可扩展性。
随着更多 LPU 的添加,可以实现性能的线性扩展,简化了大规模 AI 模型的硬件要求,并使开发人员能够更容易地扩展其应用程序。
在Groq首次发布演示Demo后,诸多大佬和从业人员就LPU能否取代GPU的话题分享了自己的看法和分析结果。
原阿里副总裁、Lepton 创始人贾扬清对比了 Groq 硬件和英伟达 H100 在运行 LLaMA 70b 模型时的成本。他发现,在同等吞吐量下,Groq 的硬件成本和能耗成本分别高达 H100 的 40 倍和 10 倍。例如,为了运行 LLaMA 70b 模型,可能需要数百张 Groq 卡,而使用英伟达 H100 则成本大幅降低。
华为的左鹏飞提出了不同的视角,他强调在讨论成本时应区分售卖价和成本价,并指出 Groq 卡的成本价可能远低于市场售价。他还提到,Groq 卡未使用高成本的 HBM,而是使用了成本较低的 SRAM,这可能影响成本效益分析。
Smol AI 的创始人 Shawn Wang 从每 token 成本的角度出发,认为 Groq 在高批量处理的假设下,其成本与定价相匹配,并且可能比基于 H100 的成本更低,显示出 Groq 在成本效益上可能具有竞争力。
表:SemiAnalysis 的 Groq 和 H100 的性价比对比
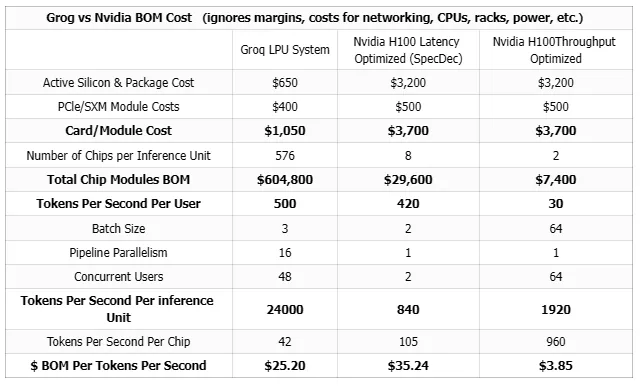
有分析认为,此前大模型的训练和推理工作大多基于 GPU 设计,采用 CUDA 软件技术栈。而 Groq LPU 的爆火则将市场风向将 AI 芯片的主战场由训练走向推理......
本文来自微信公众号“机器之心”



