# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

传统的 3D 重建算法需要不同视角拍摄的多张图片作为输入从而重建出 3D 场景。近年来,有相当多的工作尝试从单张图片构建 3D 场景。然而,绝大多数此类工作都依赖生成式模型(如 Stable Diffusion),换句话说,此类工作仍然需要通过预训练的生成式模型推理场景中的 3D 信息。
因此,不依赖任何生成式模型并从单张图片重建整个 3D 场景仍然存在巨大挑战。
本文提出了一种基于单曝光压缩成像(Snapshot Compressive Imaging, SCI)系统和神经辐射场(NeRF)的三维场景拍摄与重建方法,首先将多视角图像信息记录到一张压缩图像之中,而后在重建阶段通过一个基于 NeRF 的 3D 重建算法将场景还原。
一个典型的 SCI 系统使用 2D 传感器,可以在单次测量中将高维数据(如视频、多帧图像、高光谱图像等)压缩成一张 2D 图片。在进行测量后,需要通过重建算法将 2D 测量数据还原为原始的高维数据,该过程涉及求解逆问题。近年来,深度学习的发展促进了 SCI 重建算法的快速发展。然而,当前的重建算法并没有考虑被拍摄场景的 3D 结构,只能单纯地逐帧还原 2D 图像。且当前的重建算法依然存在准确性低、稳定性差、泛化性不足等问题。
和已有的单张图像生成 3D 方法相比,本文中的方法不需要依赖任何预训练的模型即可从单张图片中重建 3D 场景。和传统 SCI 重建方法相比,该工作借助 NeRF 强大的 3D 场景估计能力和图像渲染能力,实现了高质量的 3D 场景重建,并可以渲染高帧率的场景图像。
同时,由于 NeRF 实行测试时间优化 (Test-time Optimization, TTO),该方法具有极佳的泛化性。在各种合成数据集和真实数据上,对结果的定性和定量评估都证明了该方法优异的性能表现。

本文的主要贡献如下:
硬件设计
受益于新颖的光学硬件和成像算法的设计,单曝光压缩成像系统可以在一次压缩测量中,将高维数据(例如视频、高光谱图像)进行采样和压缩,从而实现了通过 2D 传感器(如 CCD/CMOS 相机)高效获取视觉信号。本文通过单次测量时间内拍摄快速移动的场景,将多视角图像信息压缩到单张图像中。
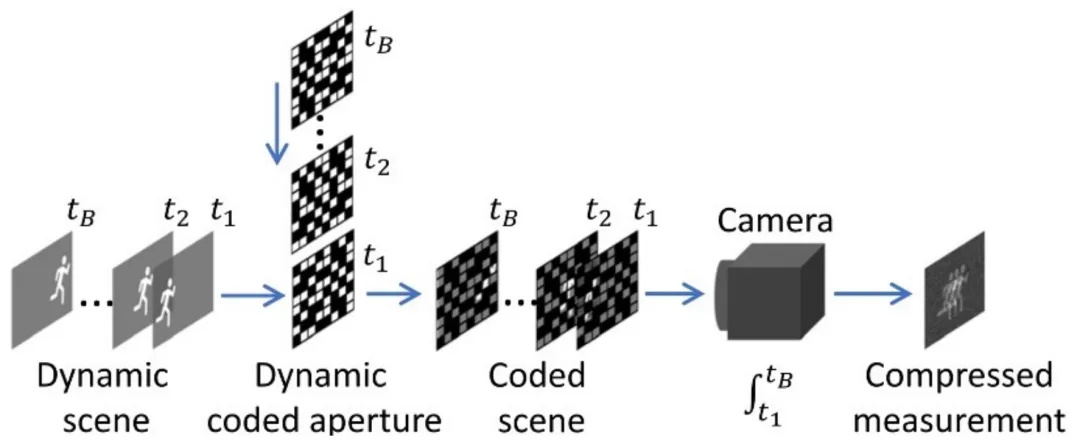
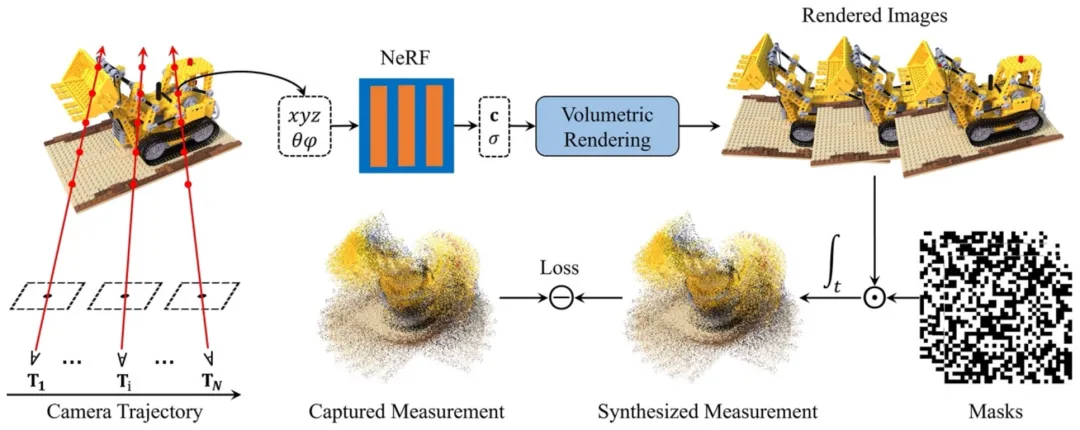
为从 SCI 图像中端到端重建 3D 场景,本文提出了一种基于 NeRF 的重建方法。由于传统的 NeRF 方法需要多视角图像及其对应的相机姿态作为输入,因此本文对 NeRF 的训练机制进行了大幅度改进。
首先,在训练 NeRF 时,将相机位姿作为优化参数,与 NeRF 的神经网络一同优化。由于在拍摄场景时测量时间很短,SCI 系统相对场景运动的幅度较小,因此该工作假设拍摄时系统作匀速直线运动,大幅降低了训练复杂度。对于比较复杂的运动轨迹,可以使用更复杂的运动模型来优化运行轨迹。
其次,通过模拟 SCI 系统的成像原理,将各个视角下渲染出的图像进行采样并压缩,得到一张合成的 SCI 图像来与真实测得的 SCI 图像计算误差并进行反向传导,从而实现使用单张图片进行端到端训练。通过以上训练机制,可以从 SCI 图像中直接获得重建好的 3D 场景(具体推导过程请见论文)。
最后,当场景重建好后,利用 NeRF 强大的图像渲染能力,可以获得恢复的图像。
定量实验
实验部分,本文基于 3D 重建领域常见的几个数据集合成了 SCI 数据集,并在该数据集上对本文提出的模型和几种已有的 SCI 图像重建算法进行了对比实验。首先通过实验,比较了几种方法在 SCI 图像 / 视频还原任务上的性能。

同时,本文还比较了几种方法在 3D 场景重建任务上的性能表现。由于已有方法只能逐帧还原 2D 图像,因此在进行 3D 场景重建任务比较时,将已有方法输出的图片使用 NeRF 重建对应场景并比较性能。

实验结果表明本文提出的方法性能显著优于已有方法。
除此之外,本文还通过搭建 SCI 成像系统获取了真实数据集,并进行了定性实验。实验结果表明在真实数据集上本文提出的方法仍显著优于已有方法。

本文提出了一种基于单曝光成像和 NeRF 的 3D 场景重建方法,实现了不依赖任何预训练生成模型的端到端单张图像重建 3D 场景。本文通过大幅度改进 NeRF 训练机制,利用 SCI 图像中隐含的 3D 信息,成功将其中的 3D 场景进行还原,并利用 NeRF 强大的图像渲染能力从场景中渲染高质量、高帧率图像。
实验结果表明,该方法不仅可以重建高质量 3D 场景,还在传统的 SCI 图像 / 视频还原任务上显著优于已有方法。这为未来在高速 3D 摄像、3D 场景加密与解密、图像与视频信息压缩等领域的应用开辟了新的可能性。
本文来自微信公众号“机器之心”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
