# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。

最近,Huggingface的机器学习团队宣布开源了一个迄今为止,规模最大的、质量最高的、即用型(ready-to-use)数据集FineWeb
FineWeb是在对CommonCrawl数据集(2013年夏天到2024年3月,共95个dump)进行去重、清洗后,得到的一个高质量、包含15T+个tokens(根据GPT-2的分词器)的Web数据集,也是目前公开可用的、最干净的语言模型预训练数据集,其主要用作英语领域的公共数据研究。
在数据处理部分,研究团队针对LLM应用场景,对整个数据处理pipeline进行了优化,并在大规模数据处理库datatrove上运行实现。
模型的消融实验性能结果也显示,FineWeb比其他开源数据集的质量更高,并且仍有进一步过滤和改进的空间,研究团队也表示在未来将继续探索如何提升FineWeb数据集的质量。
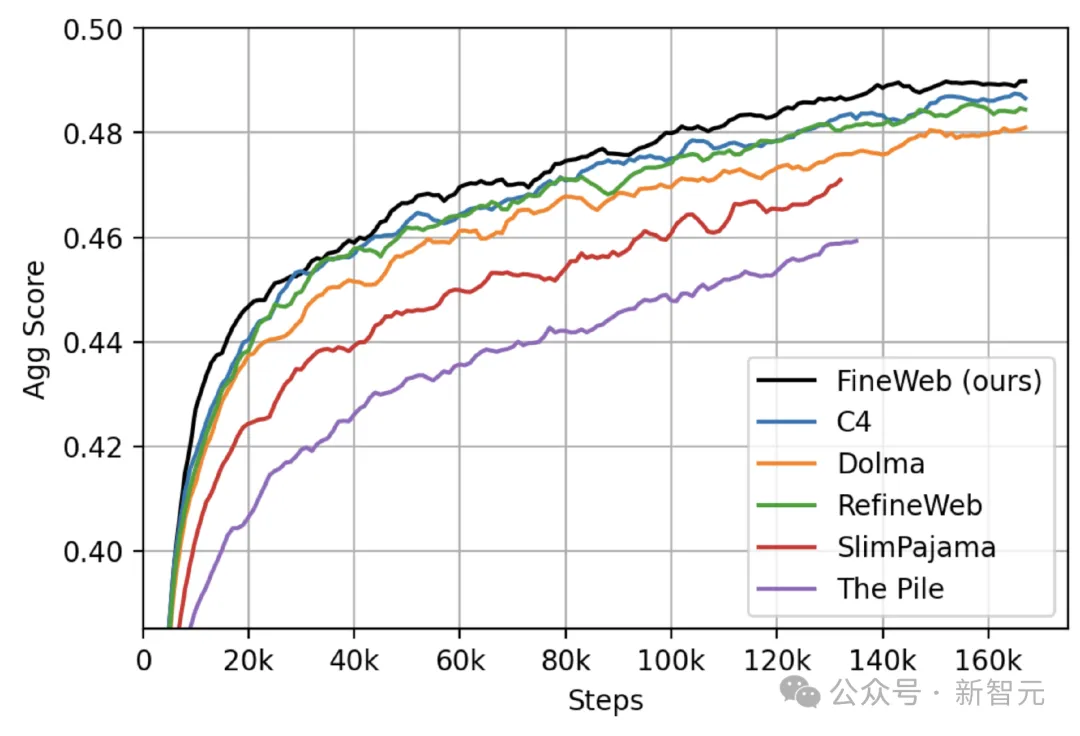
为了验证FineWeb数据的质量,研究人员选择RefinedWeb、C4、Dolma v1.6、The Pile、SlimPajama数据集作为对比,训练了一系列「1.8B参数量的小模型」进行数据集性能消融实验和评估。
选择的评估指标为commonsense_qa (acc_norm)、hellaswag (acc/acc_norm)、openbookqa (acc/acc_norm)、piqa (acc/acc_norm)、siqa (acc/acc_norm)、winogrande (acc/acc_norm)、sciq (acc/acc_norm)、arc (acc/acc_norm)和mmlu (acc/acc_norm)的平均值,每项指标均具有三个特点:
1. 在同一数据集的不同样本上的训练差异很小;
2. 训练期间,指标单调增加;
3. 在已知高质量的数据集(C4、The Pile、RedPajama)上运行,模型的分离程度(seperation)更高。
实验过程中用到的prompt都已经过格式化,以便计算和对比多项选择问题中完整答案的对数似然。
从结果来看,使用FineWeb数据集训练的模型性能在各个阶段都是最好的。
数据的命名规则为CC-MAIN-(year)-(week number)
使用datatrove
为了加快下载速度,需要确保安装 pip install huggingface_hub[hf_transfer] 并设置环境变量 HF_HUB_ENABLE_HF_TRANSFER=1
数据字段
text (字符串):主要文本内容
id (字符串):源自CommonCrawl样本的原始唯一标识符
dump (字符串):采样于CommonCrawl dump
url (字符串):text 所在原始页面的 url
date (字符串):抓取日期(CommonCrawl提供)
file_path (字符串):包含此示例的单个 CommonCrawl warc 文件的 s3 路径
language (字符串):数据集中的所有样本均为en
language_score (float):fastText 语言分类器报告的语言预测分数
token_count (int):使用gpt2分词器获得的token数量
数据切分
default 子集包括整个数据集。
如果只想使用特定 CommonCrawl 转储中的数据,可以使用dump名称作为子集。
根据研究人员的实验结果来看,使用不同dump训练后的效果有所差异:对于相对较小的训练(<400B个token),建议使用最近的 CC-MAIN-2023-50 和 CC-MAIN-2024-10
数据创建
虽然最近经常会有大模型对权重进行开源,但这些版本通常不包含模型的训练数据。
FineWeb的目标是为开源社区提供一个海量的、干净的预训练数据集,可用于推动真正开源模型(带数据的开源模型)的极限。
源数据由 CommonCrawl 基金会在 2013-2024 年期间抓取的网页组成。
研究人员从每个网页的 html 中提取主页文本,仔细过滤样本并对每个 CommonCrawl dump/crawl进行重复数据删除。
虽然团队最初打算对整个数据集进行重复数据删除,但我们的消融表明,对单独进行重复数据删除的转储/爬网样本进行的训练优于对所有一起进行重复数据删除的转储/爬网样本进行的训练。
研究人员使用datatrove 库来处理数据,脚本已开源。
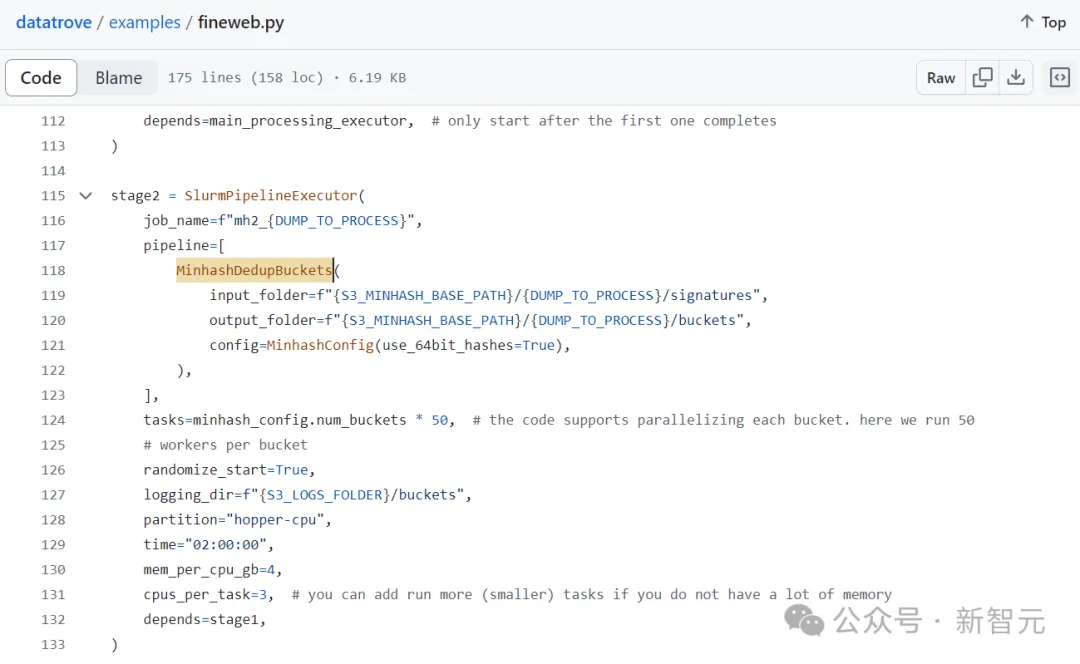
具体流程包括六步:
1. Url过滤,使用block-list和subword检测技术对源自恶意和 NSFW 网站的文档进行过滤;
2. Trafilatura,从CommonCrawl的warc文件中提取原始 HTML 文本;
3. FastText LanguageFilter,删除en语言评分低于 0.65 的文档;
4. 质量过滤,使用Gopher Reptition, C4 Quality filters(去除terminal_punct规则)和FineWeb自定义过滤器(删除列表样式的文档、具有重复行的文档以及可能具有错误行格式的启发式方法)
5. MinHash重复数据去冗余,每次抓取都单独进行去重,参数为5-gram、14x8哈希函数;
6. PII 格式化,对电子邮件和公共 IP 地址进行匿名化
对于电子邮件,使用正则表达式将其替换为 email@example.com 或 firstname.lastname@example.org
对于IP地址,先采用正则表达式匹配,然后过滤掉以仅匿名分配给公共网络的 IP 地址,最后将匹配到的IP地址替换为以下随机生成的 IP 地址之一(22.214.171.124 、126.96.36.199 、 188.8.131.52 、 220.127.116.11 和 18.104.22.168),这些地址在创建数据集时未响应 ping 请求。
由于误报率过高,研究人员决定不对电话号码使用正则表达式匹配。
标注
研究人员使用 language、language_score和token_count标注来增强原始样本;与语言相关的标注由语言过滤器自动生成;token_count通过gpt2分词器获得。
数据集的社会影响
研究人员的目标是,在FineWeb数据集发布后,让整个机器学习社区更容易进行模型训练。
虽然过去已经公开发布了多个具有强大性能的开放权重模型,但通常没有附带相应的训练数据集,而预训练的关键就在于数据,不同数据集的特殊性和特征已被证明对模型的性能具有非常大的影响和作用。
由于创建高质量的训练数据集是训练能够出色完成下游任务的 LLM 的基本要求,因此,利用FineWeb,不仅可以使数据集创建过程更加透明,而且借助公开的处理设置,包括所使用的代码库,向社区公开发布数据集,可以帮助模型创建者减轻数据集管理的时间和计算成本。
关于偏见的讨论
通过在 URL 级别进行过滤,研究人员最大限度地减少数据集中存在的 NSFW 和有毒内容的数量,但最终发布的数据集中仍然存在大量可能被视为有毒或包含有害内容的文档。
由于FineWeb源自整个网络,因此其中常见的有害偏见都可能会在该数据集上重现。
研究人员故意避免使用基于与「gold」来源(例如维基百科或毒性分类器)的相似性来定义文本质量的机器学习过滤方法,因为这些方法会不成比例地删除特定方言中的内容,并将其过度分类为与特定社交身份相关的有毒文本。
其他已知限制
由于应用了一些过滤步骤,代码内容可能在该数据集中并不普遍。
如果用户需要训练一个可执行代码任务的模型,研究人员建议将FineWeb与代码数据集一起使用,例如 The Stack v2,或者还应该考虑用专门的精选资源(例如维基百科)来补充 FineWeb,因为其格式可能比FineWeb中包含的维基百科内容更好。
许可证
FineWeb数据集根据开放数据共享归属许可证 (ODC-By) v1.0 许可证发布,并且使用过程还须遵守 CommonCrawl 的使用条款。
本文来自微信公众号“机器之心”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
