# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
机器学习三大顶会之一的ICLR 2024,正在维也纳如火如荼地举行。
虽然首个时间检验奖、杰出论文奖等“重头戏”已经陆续颁布,但在其它环节中,我们却发现了一件更有意思的事情。
同样是作为ICLR重要组成部分的特邀演讲(Invited Talk),每年都会邀请在机器学习领域有突出贡献和影响力的专家学者进行演讲。
而今年,中国只有一位!
并且仅从他的演讲主题The ChatGLM’s Road to AGI中,我们就能挖到更多的线索——
ChatGLM,正是由清华系初创智谱AI所推出的千亿参数大语言模型。

那么被ICLR官方唯一“翻牌”的智谱AI团队,又在长达1个小时的特邀演讲中说了些什么?
我们继续往下看。
在“大模型之战”开启以来,智谱AI的ChatGLM不夸张地说,是一直处于国内第一梯队的玩家之一。
事实上,智谱AI从2019年就已经入局LLM的研究;从目前的发展来看,智谱AI与OpenAI在AIGC的各个模态上均已呈现出生态对标之势:
虽然生态对标得很紧密,但从技术路线上来看,智谱的GLM与GPT是截然不同的。
当下基于Transformer架构的模型大致可以分为三类:
仅编码器架构(Encoder-only)、仅解码器架构(Decoder-only)、编码器-解码器架构(Encoder-Decoder)。
GPT是属于“仅解码器架构”的玩家,而GLM则是借鉴“编码器-解码器架构”的思路去发展;因此也有一番独树一帜的味道。
而作为此次唯一被ICLR邀请做演讲的中国大模型公司,智谱AI团队在现场先分享了自己是如何从ChatGLM一步步走向GLM-4V,即从LLM迈向VLM。
我们可以从下面这张发展时间线中,先有一个整体脉络上的感知。
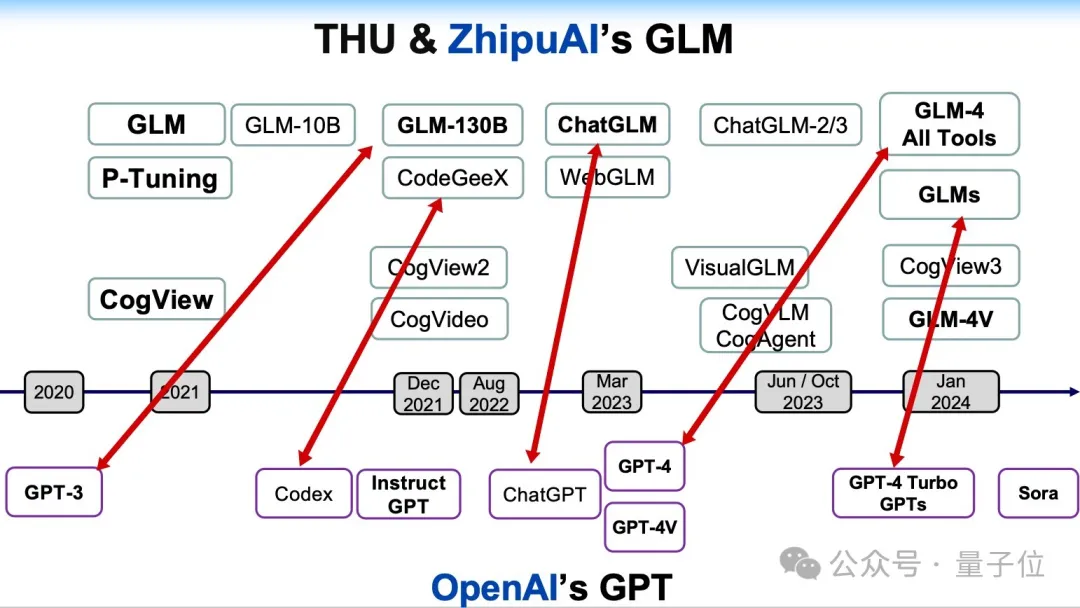
具体到技术上的实现,比较关键的节点便是CogVLM的提出,主打让大模型带上视觉。

CogVLM模型主要包含四个组件,分别是ViT编码器、MLP适配器、大型预训练语言模型和视觉专家模块。
这个方法可以说是改变了视觉语言模型的训练范式,从浅层对齐转向深度融合。
值得一提的是,CogVLM还被Stable Diffufion 3用来做了图像标注。

基于此,智谱AI团队在本次特邀演讲环节中,更多地介绍并亮出了近期的前沿成果。
例如CogView3,是一个更快、更精细的文生图模型。
其创新之处便是提出了一个级联框架,是第一个在文本到图像生成领域实现级联扩散的模型。
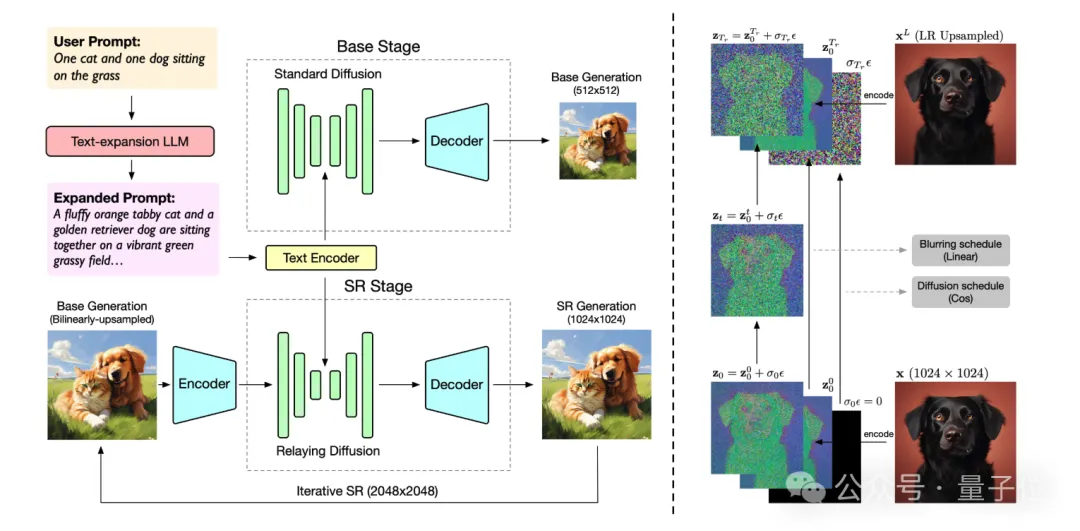
从实验结果来看,CogView3在人类评估中比当前最先进的开源文本到图像扩散模型SDXL高出77.0%,同时只需要大约SDXL一半的推理时间。
CogView3的蒸馏变体在性能相当的情况下,只需SDXL的1/10的推理时间。
同样是基于 CogVLM,智谱AI所做的另一项研究CogAgent,则是一款具有视觉Agent能力的大模型。
CogAgent-18B拥有110亿的视觉参数和70亿的语言参数, 支持1120*1120分辨率的图像理解。在CogVLM的能力之上,它进一步拥有了GUI图像Agent的能力。
据了解,CogAgent-18B已经在9个经典的跨模态基准测试中实现了最先进的通用性能;并且在包括AITW和Mind2Web在内的GUI操作数据集上显著超越了现有的模型。
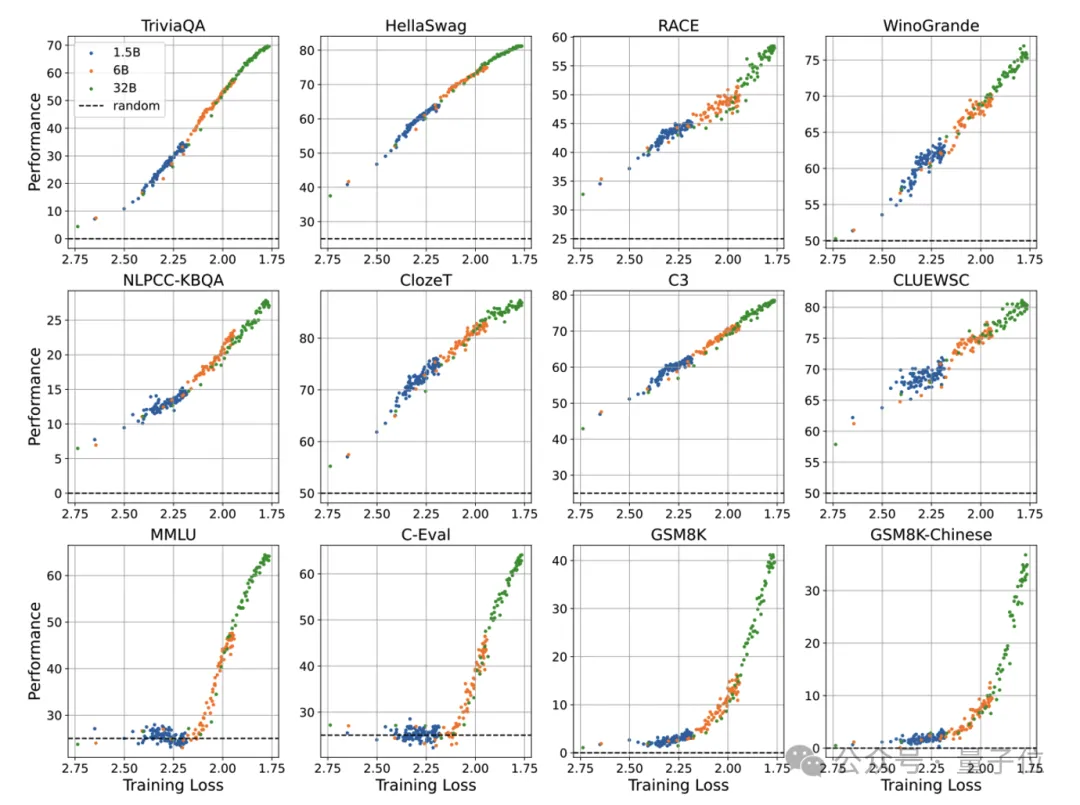
除此之外,智谱AI团队还提出:AI大模型的智能涌现,关键在于Loss,而并非模型参数。

为此,团队提出了Pre-training Loss作为语言模型“涌现能力”的指标,训练了30多个不同模型参数和数据规模的语言模型,并评估了他们在 12 个英文和中文数据集上的表现:
再如针对LLM解决数学问题,提出了Self-Critique的迭代训练方法,通过自我反馈机制,帮助LLM同时提升语言和数学的能力。

对于ChatGLM通向AGI的后续计划,智谱AI在本次特邀演讲中也亮出了自己的“三步走”。
首先是GLM-4的后续升级版本,即GLM-4.5。
据了解,新升级的模型将基于超级认知SuperIntelligence和超级对齐SuperAlignment技术,同时在原生多模态领域和AI安全领域有长足进步。
团队表示:
通向通用人工智能之路,文本是最关键的基础。
但下一步则应该把文本、图像、视频、音频等多种模态混合在一起训练,变成一个真正原生的多模态模型。
其次,为了解决更加复杂的问题,团队将引入GLM-OS的概念。
GLM-OS是指以大模型为中心的通用计算系统,具体实现方法如下:
基于已有的All-Tools能力,再加上内存记忆memory和自我反馈self-reflection能力,GLM-OS有望成功模仿人类的PDCA机制,即Plan-Do-Check-Act循环。
首先做出计划,然后试一试形成反馈,调整规划然后再行动以期达到更好的效果。大模型依靠PDCA循环机制形成自我反馈和自我提升——恰如人类自己所做的一样。
最后,是GLM-zero。
这项技术其实智谱AI从2019年以来便一直在钻研,主要是研究人类的“无意识”学习机制:
当人在睡觉的时候,大脑依然在无意识地学习。
“无意识”学习机制是人类认知能力的重要组成部分,包括自我学习self-instruct、自我反思self-reflection和自我批评self-critics。
团队认为,人脑中存在着反馈feedback和决策decision-making两个系统,分别对应着LLM大模型和Memory内存记忆两部分,GLM-zero的相关研究将进一步拓展人类对意识、知识、学习行为的理解。
而这也是GLM大模型团队第一次向外界公开这一技术趋势。
当然,除了这场特邀演讲之外,回顾本届ICLR其它亮点,可以说大模型着实是顶流中的顶流。
首先是斩获本届ICLR颁发的第一个时间检验奖(Test of Time Award)的论文,可以说是经典中的经典——变分自编码器(VAE)。
正是这篇11年前的论文,给后续包括扩散模型在内的生成模型带来重要思想启发,也才有了现如今大家所熟知的DALL·E 3、Stable Diffusion等等。
也正因如此,在奖项公布之际便得到了众多网友的认可,纷纷表示“Well deserved”。

论文一作Diederik Kingma现任DeepMind研究科学家,也曾是OpenAI创始成员、算法负责人,还是Adam优化器发明者。
VAE采用了一个关键策略:使用一个较简单的分布(如高斯分布)来近似复杂的真实后验分布。模型的训练通过最大化一个称为证据下界(ELBO)的量来实现。
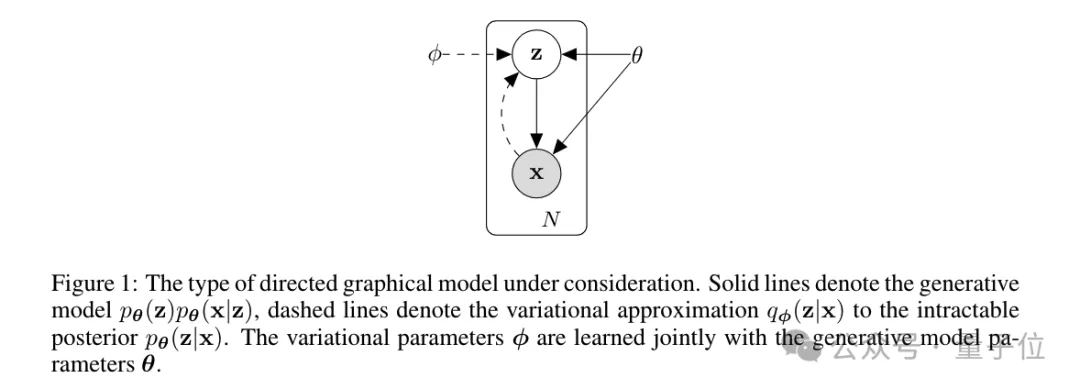
这种方法可以被看作是在图像重建的同时,对潜在变量的分布施加了一种“规范化”约束。
与传统自编码器相比,VAE所学习的潜在表示通常具有更强的解释性和更好的泛化能力。
在论文的实验部分,作者展示了VAE在MNIST数据集上生成手写数字图像的能力。

ICLR 2024的首个时间检验奖还设置了亚军(Runner Up)奖项。
同样也是非常经典的一项研究,作者包括OpenAI首席科学家的Ilya、GAN的发明者Ian Goodfellow。

这项研究名为Intriguing properties of neural networks,官方对其的评价是:
研究强调了神经网络容易受到输入的微小变化的影响。
这个想法催生了对抗性攻击(试图愚弄神经网络)和对抗性防御(训练神经网络不被愚弄)领域。
除了时间检验奖之外,每年的杰出论文奖(Outstanding Paper Awards)也是必看点之一。
本届ICLR共有五篇论文荣登杰出论文奖。

第一篇:
Generalization in diffusion models arises from geometry-adaptive harmonic representations
这篇来自纽约大学、法兰西学院的研究,从实验和理论研究了扩散模型中的记忆和泛化特性。作者根据经验研究了图像生成模型何时从记忆输入转换到泛化机制,并通过 “几何自适应谐波表征 ”与谐波分析的思想建立联系,进一步从建筑归纳偏差的角度解释了这一现象。

第二篇:
Learning Interactive Real-World Simulators
研究机构来自UC伯克利、Google DeepMind、MIT、阿尔伯塔大学。汇集多个来源的数据来训练机器人基础模型是一个长期的宏伟目标。这项名为 “UniSim ”的工作使用基于视觉感知和控制文字描述的统一界面来聚合数据,并利用视觉和语言领域的最新发展,从数据中训练机器人模拟器。

第三篇:
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
来自特拉维夫大学、IBM的研究深入探讨了最近提出的状态空间模型和Transformer架构对长期顺序依赖关系的建模能力。作者发现从头开始训练Transformer模型会导致对其性能的低估,并证明通过预训练和微调设置可以获得巨大的收益。

第四篇:
Protein Discovery with Discrete Walk-Jump Sampling
基因泰克、纽约大学的研究解决了基于序列的抗体设计问题,这是蛋白质序列生成模型的一个重要应用。作者引入了一种创新而有效的新建模方法,专门用于处理离散蛋白质序列数据的问题。

第五篇:
Vision Transformers Need Registers
来自Meta等机构的研究,识别了vision transformer网络特征图中的伪影,其特点是低信息量背景区域中的高规范Tokens。作者对出现这种情况的原因提出了关键假设,利用额外的register tokens来解决这些伪影问题,从而提高模型在各种任务中的性能。

而在五篇杰出论文奖中,与大模型相关的研究就占了四篇,可以说是赢麻了。
除此之外,还有11篇论文获得了获得荣誉提名(Honorable mentions),其中三篇论文是全华人阵容。
整体来看,本届会议共收到了7262 篇提交论文,接收2260篇,整体接收率约为 31%。此外Spotlights论文比例为 5%,Oral论文比例为 1.2%。
ICLR的创立者之一Yann LeCun(另一位是Yoshua Bengio),在会议期间的“出镜率”可以说是比较高了,频频出现在网友的照片中。
而他本人也开心地分享了自己的一张自拍合影:

不过也有网友指出:“拍得不错,就是可怜手机后边的兄弟了。”

以及会场的展厅也是有点意思:

嗯,是有种全球大模型玩家线下battle的既视感了。
本文来自微信公众号”量子位“




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
