# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
北京时间 5 月 15 日凌晨,在 OpenAI 春季发布会的第二天,2024 年谷歌 I/O 召开,这是一场充满了 AI 的发布会,谷歌对其旗下的多款 AI 产品发布了大更新,从基座模型 Gemini 到新的 AI 助手 Astra、新的文生视频模型 Veo,以及更强大的文生图模型 Imagen 3。
还有就是,谷歌终于决定对搜索进行 AI 改造了!重新设计了搜索的展示形态,并且很快将对美国用户推出 AI Overviews(AI 概览)功能。

在发布会结尾的总结演讲中,谷歌 CEO 皮查伊特别提到,今天谷歌提到了 121 次 AI。
首先是 Gemini 1.5 Pro,100 万 tokens 的长文本能力,目前已登陆 AI Studio,向所有开发者开放使用。
Google Workspace 中也将可以使用 Gemini 1.5 Pro,用户可以使用 AI 进行邮件总结或者 PDF 文本分析,比如搜索用户的所有邮件并且显示摘要,加快用户的邮件处理速度。

最大的更新尚未到来——谷歌宣布今年晚些时候将模型的现有上下文窗口增加一倍,达到 200 万 tokens。这将使其能够处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词,是目前 Claude 3 上下文长度的两倍。
除了更长的上下文窗口,Google 表示,在过去的几个月里,通过算法改进,Gemini 1.5 Pro 已经得到了「增强」。在代码生成、逻辑推理和规划、多轮对话以及音频和图像理解方面更加出色。在 Gemini API 和 AI Studio 中,1.5 Pro 现在可以跨音频进行推理,除了图像和视频之外,还可以通过称为系统指令的功能进行「引导」。
对于 Gemini 的订阅用户,可以使用谷歌新推出的「Gems」功能,创建不同种类的 Chatbot,类似于在 Character.AI 中制作机器人,该服务允许用户与流行角色和名人的 AI 版本或甚至 AI 医生交谈。谷歌表示,用户可以将 Gemini 变成健身伙伴、厨师、编程伙伴、创意写作指南或能想到的任何东西。
Gems 有些类似于 OpenAI 的 GPT 商店。
可能是出于成本的考虑,在已有的 Nano、Pro 和 Ultra 之外,谷歌发布了新的轻量级模型:Gemini 1.5 Flash,为开发人员提供更多选择。

这是 Pro 版本的精简版,更便宜更轻量级,但功能同样强大,谷歌表示这是通过「蒸馏」的方式来实现的,将 Gemini 1.5 Pro 中最重要的知识和技能转移到较小的模型上。这意味着 Gemini 1.5 Flash 将获得与 Pro 相同的多模态功能(分析音频、视频和图像等),以及同样长度的上下文窗口。
官方声称,Flash 版本适合处理摘要、聊天、图片分析和视频字幕、以及从长文本和表格中提取数据等。目前开发者可以通过 API 的方式使用,Flash 模型并未向普通消费者提供。
工作人员详细介绍了 Gemini 1.5 Pro 和 Flash 的定价。Gemini 1.5 Flash 的价格定为每 100 万 tokens 35 美分,这比 GPT-4o 的每 100 万 tokens 5 美元的价格要便宜得多。

此外还有一些其他应用中加上了 AI 的能力:
Gemma 是谷歌的开放模型系列,采用与 Gemini 模型相同的技术构建。此次谷歌在原来模型基础上宣布推出 Gemma 2,Gemma 2 采用全新架构,旨在实现突破性的性能和效率,并将提供 27B 大小的尺寸。

目前可用的是 PaliGemma,号称 Gemma 家族的第一个视觉 LLM,据悉,PaliGemma 是谷歌受 PaLI-3 启发,将用户图像字幕、图像标注和物体识别等。
谷歌将在搜索中加入 AI 结果的呈现:AI Overviews(AI 概览),在用户进行提问时在页面顶部提供 AI 生成的答案。
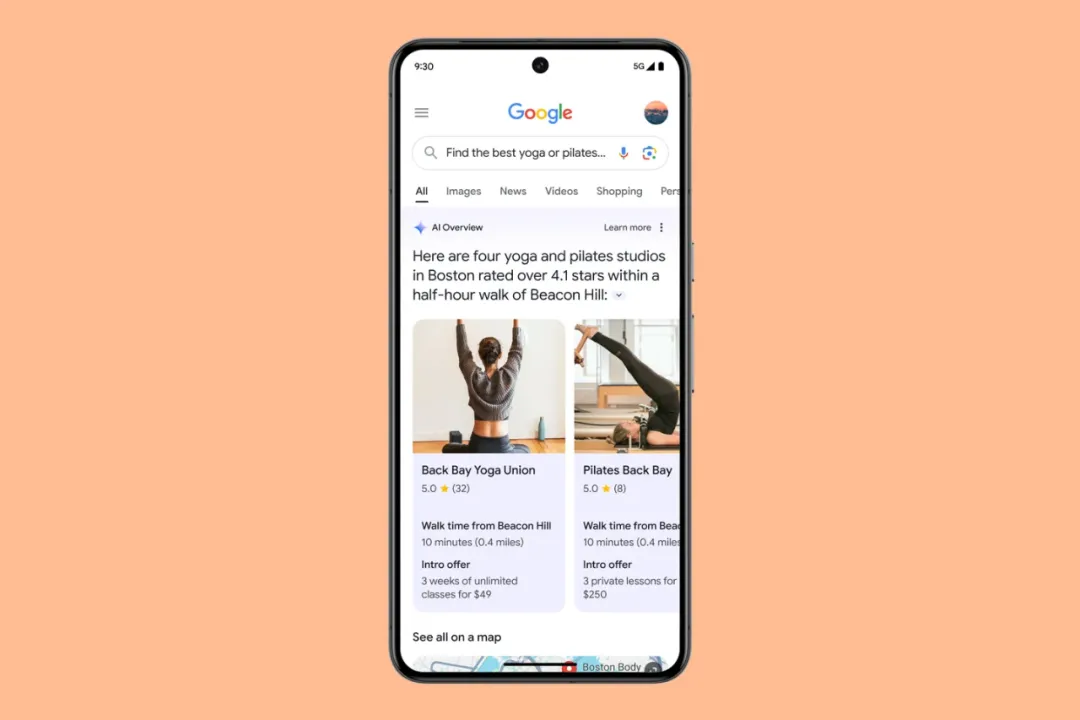
官方人员表示,AI 概览不会出现在每个搜索结果中,目前主要针对于更复杂的问题。每次用户进行搜索时,谷歌会在后台进行算法价值判断,以决定是否提供由 AI 生成的答案还是直接提供传统的网页链接。
本周谷歌将向美国用户提供 AI 概览功能,该功能将在年底推广到更多国家。该功能面向全平台推出,从 Web 网页、App 到 Android 设备。
此外,即将发布的功能还有行程规划功能,你可以要求谷歌为你制定膳食计划,或者找到一个附近提供折扣的普拉提健身房。在谷歌的规划中,AI Agent 可以汇总附近的工作室和用户评论,并规划出步行时间,依赖于谷歌拥有的大量数据,这是其他 AI 搜索暂时无法做到的。
谷歌 Lens 也发布了新的更新:可以直接拍摄视频进行搜索,以前 Lens 只能捕捉图片,现在则可以使用视频和语音进行提问。

谷歌的最新 AI 语音助手——Astra,能够通过摄像头识别物体、代码和各种东西。这个概念其实是 DeepMind 负责人 Dmis 在去年 12 月首次推出 Gemini 模型所承诺的功能。
Astra 能够通过设备的摄像头识别物体和场景,并用自然语言进行交互。官方介绍,Astra 使用了 Gemini Ultra 的高级版本。
在演示中,用户可以佩戴谷歌的智能眼镜可以与 Astra 进行交互,这也被视为一个重启谷歌智能眼镜的机会。
Demis 在此前的采访中表示,文本聊天只是通过更复杂的 AI 助手的过渡阶段,语音和视觉可能才是未来,这也是为什么 Gemini 是原生多模态的大模型。
谷歌希望用 Veo 来挑战 OpenAI 的 Sora,Veo 能够根据提示词生成 60 秒时长的 1080P 的视频片段,可以捕捉不同的视觉和电影风格,包括风景镜头、延时摄影灯。
Veo 接受了大量的镜头训练。这也是当下大模型的训练方式:提供一个又一个的数据示例,模型就会在数据中找到模式,使它们能够生成新数据——对 Veo 来说数据就是视频。官方人员承认有些数据来自 YouTube。
像 Sora 一样,Veo 对物理有一定的理解——比如流体动力学和重力等,这些有助于它生成更具真实感的视频。
Veo 还支持对视频的特定区域进行遮罩编辑,并可以从静态图像生成视频,类似于 Stability AI 的 Stable Video 等生成模型。最引人注目的是,给定一系列共同讲述一个故事的提示,Veo 可以生成更长的视频——超过一分钟长度的视频。
DeepMind 负责人 Demis 声称,与 Imagen 2 相比,Imagen 3 能够更准确理解图像的文本提示词,并且生成的图片更具创造性和细节。

「这是我们文本渲染的最好模型,这对于图像生成来说一直是个挑战。」Demis 补充道。
此外,谷歌宣称,Imagen 3 将使用由 DeepMind 开发的 SynthID 水印方法,对生成的图片应用不可见的、加密的水印。SynthID 将全面应用于 AI 生成的图片、视频和音乐作品中。
在 I/O 大会上,谷歌提到了即将推出的安卓新版本,即以 AI 为核心的 Android,今年将实现三项突破:在 Android 上提供更好的搜索、Gemini 正在成为 AI 助手,以及设备上的 AI 将解锁新的体验。
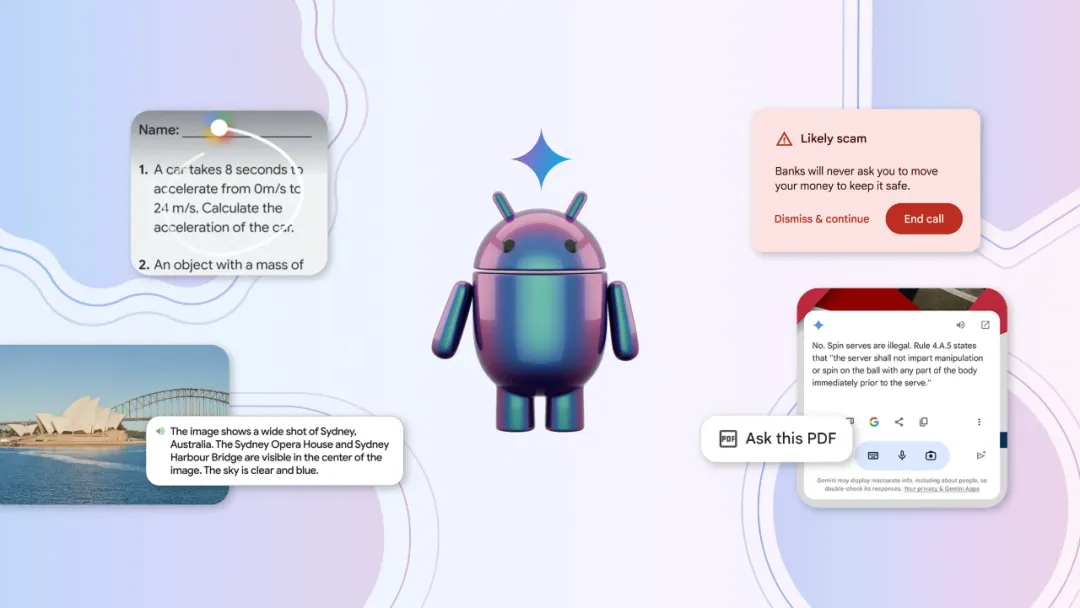
与底层操作系统的集成后,就能实现一些更酷的功能。Android 上的 Gemini 具有更强的上下文感知能力,可以覆盖在正在使用的任何 app 之上,因此你无需来回切换。还有一个巧妙的功能,用户能够使用 Gemini 生成图像,并将它们拖放到像 Gmail 或 Google 消息这样的应用程序中。
谷歌将在手机上尝试搜索的新方式:Circle to Search,就像 Now on Tap 一样,这种方式更有互动性,非常直观.
谷歌还展示了直接通过 Pixel 8a 上的 Google Messages 应用程序使用 Gemini 的不同方式。它包括能够分析 PDF 或视频并向 Gemini 提出问题,获得清晰(并引用)的答复。这些功能将在「未来几个月」出现在更多设备上。
如果用户将 Gemini 设置 Android 手机的默认助手,它可以对网页或屏幕截图进行总结或回答问题。不久,它还将能够检测到屏幕上是否有视频,并可以跟用户进行互动。
可能,集成了 Gemini 的手机助手,才是多年前发布的 Google Now 的完全版。
本文来自微信公众号“Founder Park”

00:13
00:14



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
