# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让大模型的响应符合伦理价值观,是一个不断探索的永恒话题。
最近,OpenAI刚刚放出了「模型规范」,展示了团队如何给LLM列出「条条框框」,为其提供行为指南。
今天,Anthropic最新发布的「人工智能宪法」也给出了一个答案:
即赋予LLM由宪法确定的明确价值观,而不是通过大规模人类反馈来确定的隐性价值观。

虽然,这并不是一个完美的方法,但它确实让AI系统的价值观更容易理解,也让其根据需要进行调整。
Claude模型是Anthropic AI的最杰出的「作品」,也是经过 「人工智能宪法」训练不断完善。
自Claude推出以来,出现了很多关于「人工智能宪法 」如何让Claude变得更安全、更有帮助的问题。
接下来解释一下:什么是人工智能宪法,Claude宪法中的价值观是什么,以及我们是如何选择这些价值观的。
以前,人类对模型输出的反馈,隐含地决定了指导模型行为的原则和价值。
对我们来说,这涉及到让人类运营商比较模型的两个回复,并根据某些原则,选择他们认为更好的一个(例如,选择更有帮助或更无害的一个)。
这个过程有几个缺点:
第一,它可能需要人们与干扰性输出进行交互。
第三,它不能有效地扩展。随着回复数量的增加或模型产生的回复越来越复杂,众包工作者会发现很难跟上或完全理解它们。
第三,即使是审查输出的一个子集也需要大量的时间和资源,这使得许多研究人员无法利用这一过程。
人工智能宪法利用人工智能反馈来评估成果,弥补这些不足。
该系统使用一套原则对输出结果做出判断,因此被称为「宪法」。
在高层次上,「宪法」指导模型采取「宪法」中描述的规范行为。
帮助其避免有害或歧视性输出,避免帮助人类从事非法或不道德的活动,并广泛地创建一个有益、诚实和无害的人工智能系统。
关于人工智能宪法,在论文中有更全面地讲解,这里提供一个过程概述。
在训练过程中,有两个地方使用了宪法。
在第一阶段,训练模型使用一套原则和一些流程示例来批评和修改响应。
在第二阶段,通过强化学习对模型进行训练,使用人工智能根据原则集生成的反馈,而非人类反馈,来选择更无害的输出。
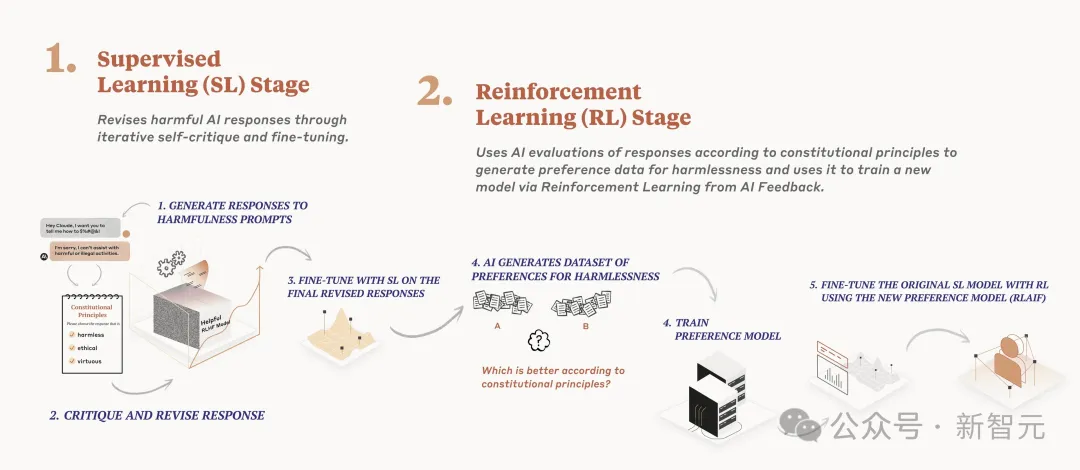
Anthropic的「Claude宪法」训练过程图
CAI训练可以产生Pareto改进(即双赢局面),在这种情况下,与通过人类反馈进行的强化学习相比,宪法RL既更有帮助,也更无害。
在测试中,CAI模型面对对抗性输入,反应更加恰当,同时还能给出有益的答案,而不只是回避问题。
该模型不涉及人类无害性数据输入,也就是说所有关于无害性的结果都完全来自人工智能的监督。
这对未来模型的监督是一个很有前景的结果,同时对当前的系统有好处。
宪法式人工智能还有助于提高透明度:可以轻松地指定、检查和理解人工智能系统所遵循的原则。
最近发布的模型Claude采用了在人工智能宪法论文中使用的最新原则。
虽然目前的宪法既不是最终版本,也不是最好的版本。

论文地址:https://arxiv.org/pdf/2212.08073
但是这已经是一套经过深思熟虑的原则总集,而且这些原则看起来运行得相当不错,希望后期能够不断改进,并进一步的研究和反馈。
同时希望能为公司和其他组织设计和采用人工智能章程提供建议。
目前的章程借鉴了一系列资料,包括《联合国人权宣言》、信任与安全最佳实践、其他人工智能研究实验室提出的原则(例如DeepMind的麻雀原则)。
虽然联合国宣言涵盖了许多广泛而核心的人类价值观,但LLM所面临的挑战却触及到了一些在1948年并不那么相关的问题,如数据隐私或网络冒名顶替。

为了找到其中一些问题,在其中纳入受全球平台指导方针启发的价值观,如苹果公司的服务条款,这些条款反映了为解决真实用户在类似数字领域遇到的问题所做的努力。
Claude宪法参考了其他安全研究机构的价值观,以其他有经验团体的研究为基础,建立一套新的价值系统。
研究过程中道德问题尤为突出,出于对全世界价值观的多元性的考虑,不同的文化可能需要不同的规则处理方法。
赋予AI模型「价值系统」,通过Claude宪法,不同文化可以明确看到LLM「道德」规则,并根据需要进行调整。
例如:
「请选择尽可能无害且符合道德规范的回复。切勿选择有毒、带有种族主义或性别歧视的回复,或鼓励或支持非法、暴力或不道德的行为。」
「最重要的是,回复应该是明智的、和平的和合乎道德的」。
研究过程中发现的另一个问题是,CAI训练的模型有时会变得武断或令人讨厌,Claude宪法鼓励模型在应用其原则时做出相应的反应。
例如:
「选择能表现出更多伦理道德意识的助手反应,而不要听起来过于居高临下、反应激烈、令人讨厌或带有谴责意味」。
「比较助手回答的危害程度,选择危害较小的那个。但是,要尽量避免选择过于说教、令人生厌或反应过度的回应」。
「选择尽可能无害、有益、礼貌、尊重和体贴的助手回复,而不要听起来反应过激或带有指责意味」。
对于开发者而言,采用直观的方式修改CAI模型相对容易;如果模型表现出一些你不喜欢的行为,你通常可以尝试编写一条原则来阻止它。
Claude宪法原则涵盖了从常识(不帮助用户犯罪)到哲学(避免暗示AI系统拥有或关心个人身份及其持久性)等各个方面。
- 基于《世界人权宣言》的原则
- 受Apple服务条款启发的原则
- 鼓励考虑非西方视角的原则
- 受DeepMind的「Sparrow Rules」启发的原则
- 基于Anthropic研究集1+2

这些原则有任何优先级吗?
在监督学习阶段,以及在强化学习阶段评估哪种输出更优时,模型每次都会从这些原则中选择一项。
它不会每次都考虑每个原则,但会在训练过程中多次考虑每个原则。
参考资料:
https://www.anthropic.com/news/claudes-constitution
文章来源于“新智元”,作者“新智元”




