# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
把大模型塞进手机里需要几步?
如果说 2023 年是生成式 AI 爆发的元年,那么各路厂商今年难得一见地达成了共识——全力押注端侧大模型。
作为一家专攻「高效大模型」的 AI 新秀,今天面壁智能再秀肌肉,推出了最强端侧多模态开源模型 MiniCPM-Llama3-V 2.5。
最强端侧多模态综合性能:
超越多模态巨无霸 Gemini Pro、GPT-4V
OCR 能力 SOTA!9 倍像素更清晰,难图长图长文本精准识别
图像编码快 150 倍!首次端侧系统级多模态加速

正如人类依赖五感探索世界,多模态能力是 AI 进化路上的必修课。
仅凭 8B 量级的端侧模型,「以小博大」的 MiniCPM-Llama3-V 2.5 在评测平台 OpenCompass 得分 65.1,不仅比肩闭源模型 Qwen-VL-Max,综合性能还力压重量级选手 GPT-4V 和 Gemini Pro。
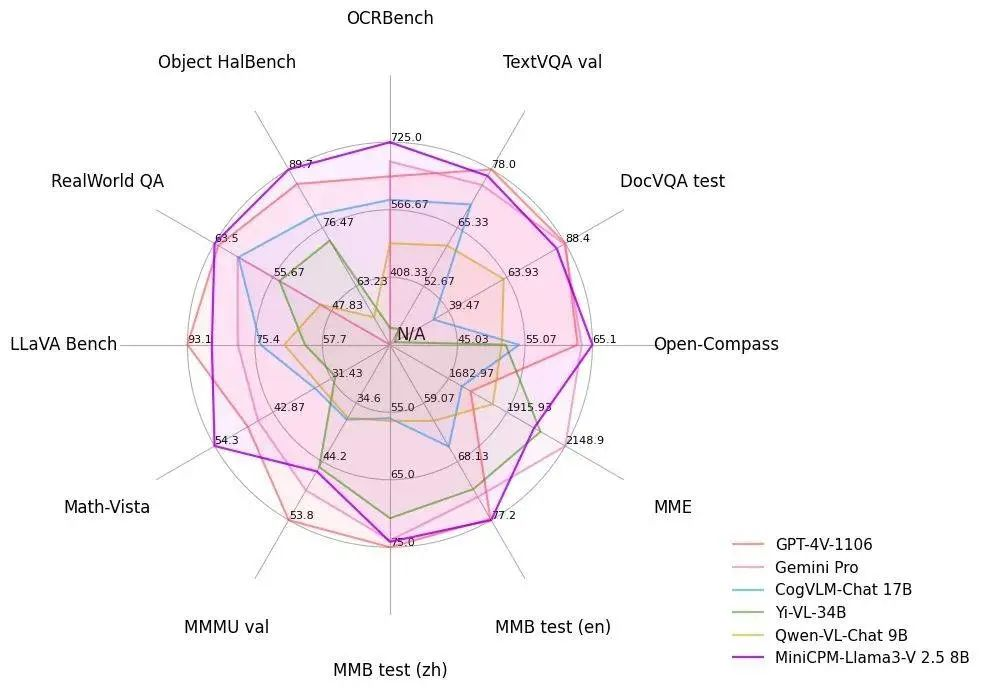
在 OCR (光学字符识别)这一综合基准测试中,MiniCPM-Llama3-V 2.5 取得了 725 分的成绩,大幅度远超 GPT-4V,成为超越了Claude 3V Opus 等越级模型。
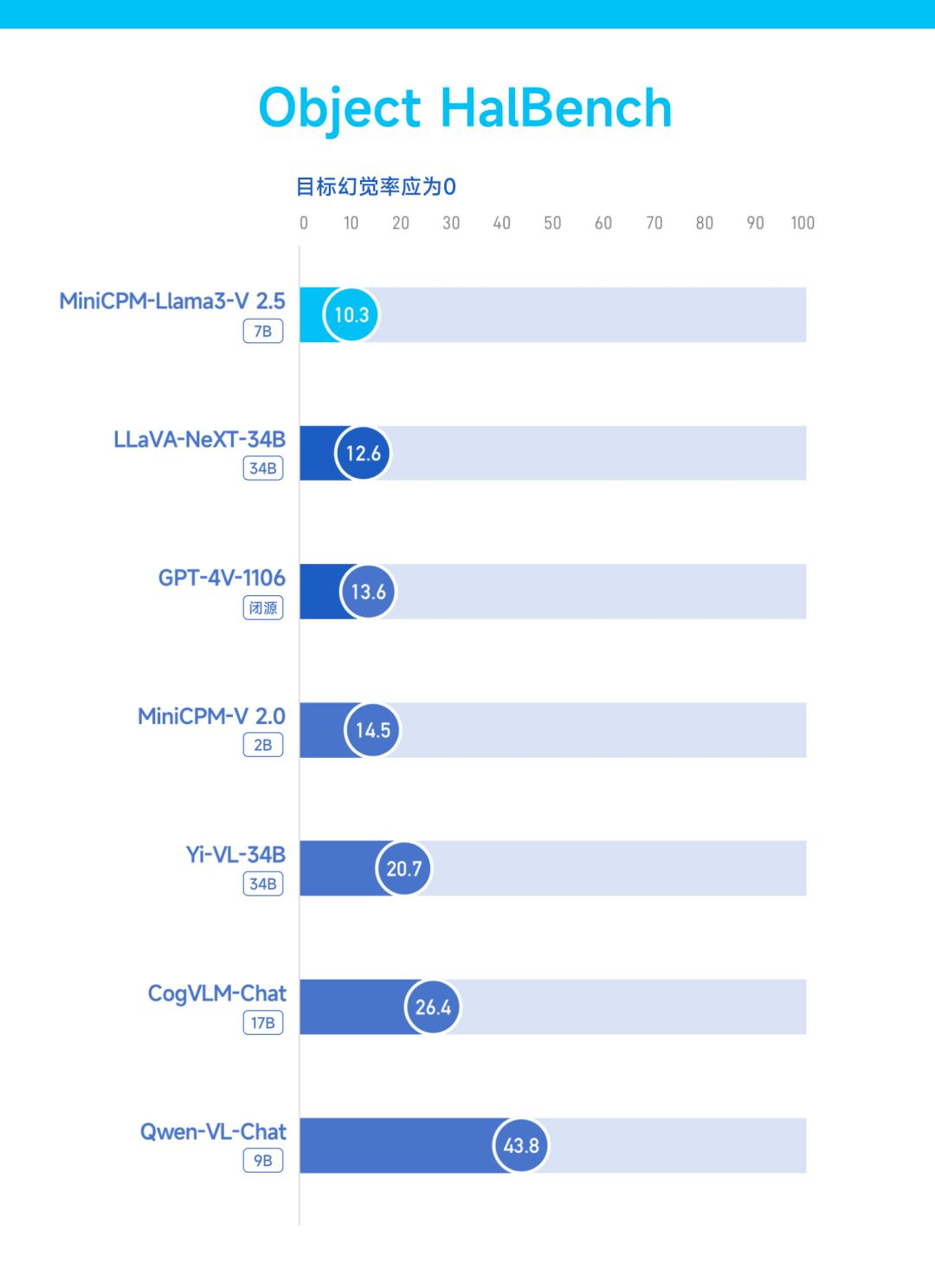
幻觉能力是短时间内萦绕在大模型心头上最大的顽疾,MiniCPM-Llama3-V 2.5 在这一问题上也有所改进。
反映到 Object HalBench 的基准测试中,其幻觉率从 MiniCPM-V 2.0(2B) 的 14.5 锐减至 10.3,再次超越 GPT-4 V和 LLaVA-NeXT-34B。
RealWorldQA 基准测试是一场检验模型现实理解力的大考。
MiniCPM-Llama3-V 2.5 交出了 63.5 的答卷,仅次于 InternVL-Chat-V1.5 (26B),却依旧让 GPT-4V 和 Gemini Pro 甘拜下风。
依托于面壁自研高清图像高效编码技术,MiniCPM-Llama3-V 2.5 支持高效编码及无损识别 180 万高清像素图片,并且支持任意长宽比,即便是 1:9 的极限比例图像,对它来说,也只是小菜一碟。

「能看」只是开始,更重要的是要懂得「思考」,MiniCPM-Llama3-V 2.5 在复杂推理能力更上一层楼。

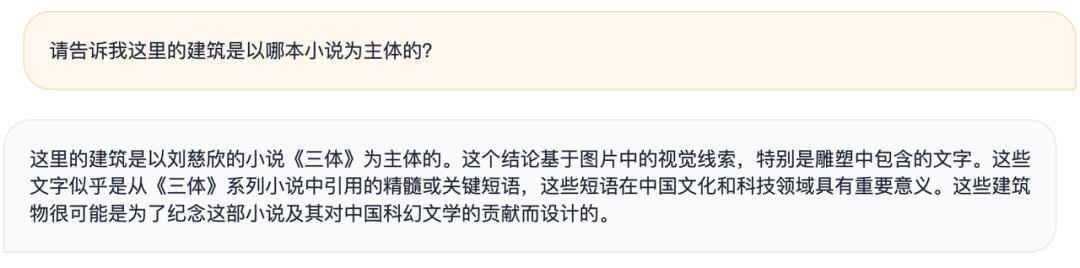
官方举例称,给出一张刻满《三体》名言的艺术建筑,一般大模型大致只能描述出图像的模型,而 MiniCPM-Llama3-V 2.5 却可以根据识别到的信息联想到《三体》书籍。
MiniCPM-Llama3-V 2.5

GPT-4V
同时还能给出自己的见解——这些建筑很可能是为了纪念这部小说及其对中国科幻文学的贡献而设计的。
又或者甩给它一张英文版的亚洲饮食金字塔, 它能秒变私人营养师,定制一周菜谱。

懒得阅读长文,交给 MiniCPM-Llama3-V 2.5 吧,然后询问问题,它能以最快的速度给出答案。
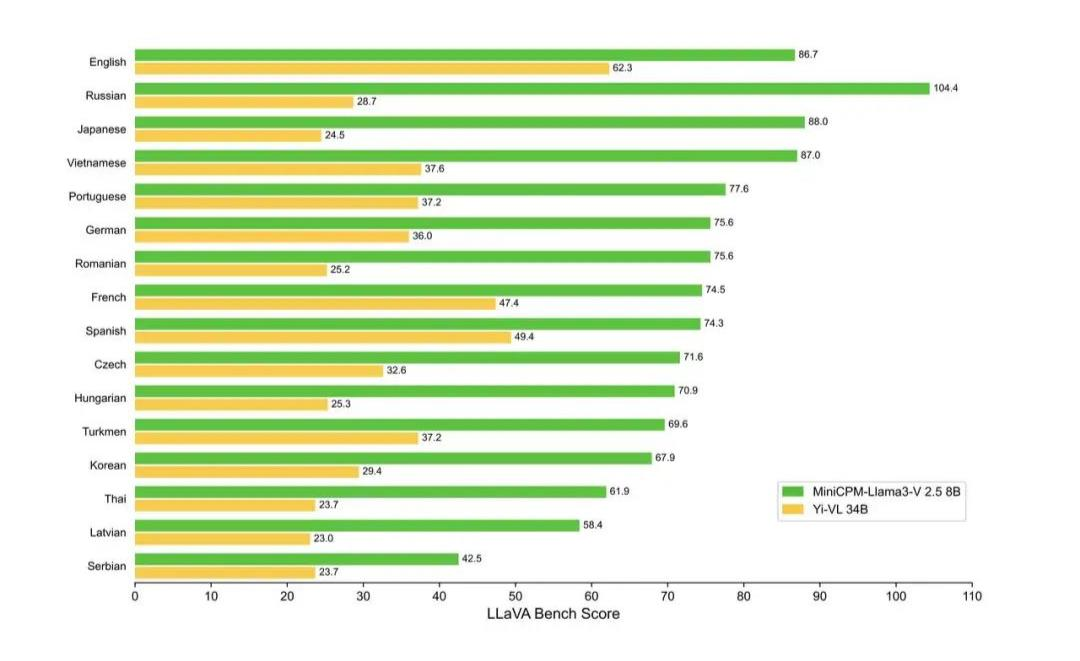
现在,MiniCPM-Llama3-V 2.5 支持 30+ 种语言,涵盖德语、法语、西班牙语、意大利语、俄语等主流语言,一带一路沿线国家的语言基本做到信手拈来。
需要说明的是,MiniCPM-Llama3-V 2.5 实则是基于开源模型 Llama3-8B-Instruct 之上的精调模型。
以往想要让 AI 同时处理图像和文字这类不同的信息,而且速度还得快,是个大难题,但是面壁智能采用了 NPU 加速框架,专用于加速处理图像,让 AI 在手机上工作的效率大大提升。
据官方介绍,面壁只能首次进行端侧系统加速,目前 MiniCPM-Llama3-V 2.5 已高效部署手机,并且在图像编码上实现了 150 倍的加速提升。
举例来说,Llama 3 语言模型在手机端侧的解码速度在 0.5 token/s 上下,而多模态模型 MiniCPM-Llama3-V 2.5 经过 CPU 等多重优化方式,使得在手机端的语言解码速度提升到 3-4 token/s。
附上 MiniCPM-Llama3-V 2.5 开源地址:
???? https://github.com/OpenBMB/MiniCPM-V
近两年来,端侧模型在各大终端厂商的演讲 PPT 上频频露脸。
所谓端侧模型是那些在终端设备上运行的人工智能模型。这些模型通常被设计得足够轻量,以适应终端设备的计算能力和资源限制。
「AI 教父」Geoffrey Hinton 就曾指出:「我认为将会有一个阶段,我们在大算力计算机上进行训练,一旦模型训练好了,可以在低功耗设备上进行运行。」
端侧模型的特点正是能够在设备端(如智能手机、嵌入式系统等)上运行,处理数据并做出决策,而不需要将数据发送到远程服务器。
将上面这些话掰开来看,我们就能从中发现端侧模型的优点:
本地运行:模型在设备端本地运行,不需要依赖远程服务器。
实时处理:能够在设备上实时处理数据,提供快速响应。
低延迟:由于数据不需要在设备和服务器之间传输,因此具有较低的延迟。
隐私保护:数据在本地处理,减少了数据泄露的风险,增强了隐私保护。
网络独立性:即使在没有网络连接的情况下,端侧模型也能正常工作。
资源优化:端侧模型通常需要优化以适应终端设备的有限计算资源和存储空间。
适用于多种设备:端侧模型可以部署在各种类型的终端设备上,包括但不限于智能手机、智能家居设备、可穿戴设备等。
小型化和优化:模型可能需要经过压缩、剪枝、量化等技术处理,以减小模型大小和提高运行效率。
当然,端侧大模型和云端大模型是协同,而非站在对立面的产物。
所以我们看到,在诸如 Llama 3、Claude 等大模型发展得如火如荼的同时,端侧模型的研究也没有落下。
英伟达科学家 JImFan 指出,最新的 GPT-4o 极有可能就是一个经过蒸馏的小模型,好处也显而易见——更加精炼,更加高效。
而无论是上个月微软发布的 Phi-3,亦或者面壁智能发布的性能小钢炮系列,又或者苹果最近宣布开源的 OpenELM 系列模型,也都在不断推出新的小尺寸模型。

2024 年是 AI 落地应用的关键元年,端侧模型也正蓄势待发,准备在这一年里大放异彩。
一个不争的事实是,当下大部分的终端创新已然陷入瓶颈期。以「长在」我们身体上的手机为例,当年乔布斯掏出的 iPhone 时的惊艳与革新感早已消逝在时间的长河里。
AI 驱动终端创新的命题,别管是噱头大于实际,还是拿着未来的技术给当下「贴金」,实际上都能为诸如手机这类的设备进一步释放想象力,成为破局的关键点。

正是在此趋势下,端侧模型不再是仅仅停留在理论探讨或厂商宣传册上的概念,它开始逐步渗透到我们的日常生活中。
在去年 8 月份的 HamonyOS 4 发布会上,余承东宣布智慧助手小艺接入 AI 大模型的能力。紧接着,雷军透露小米已经在手机上跑通了 1.3B 参数的大模型,部分场景效果可媲美云端。
国内手机的「御五家」一个也没落下。基于 AndersGPT 的 OPPO 小布助手,搭载 7B 端侧 AI 大模型的荣耀 Magic 6、搭载蓝心大模型矩阵的 vivo 也陆续官宣。
包括今天凌晨,彭博社记者 Mark Gurman 爆料称,苹果将改进 Siri 的语音功能,使其更具对话感,并增加帮助用户处理日常生活的功能,包括:
自动总结 iPhone 的通知
总结新闻文章
转录语音备忘录
改进自动填充日历、推荐应用程序的现有功能
AI 编辑照片
至于最核心的语音助手 Siri,未来则很可能与 OpenAI 或 Gemini 的端侧模型紧密相连。
虽然当下大火的 AI 硬件 Rabbit R1 被质疑是套壳 Android ,但它在发布会上所展示的,也是 AI 手机的理想状态的侧写——一个应用间壁垒全无、流畅交互的系统。

只不过,这样的情况并非一蹴而就,若 AI 语音助手真能如愿以偿地理解用户、调度应用,它不仅将彻底颠覆用户体验,同时也有望改变手机厂商与第三方应用开发者之间的关系网。
例如,此前就有消息传出,一向封闭的苹果面对这场技术变革的洪流,也开始选择主动拥抱开放。
据 Melius Research 的 Ben Reitzes 透露,苹果有望在即将召开的 WWDC上 推出一个专门针对 AI 应用的商店。这不仅是苹果开放策略的一个重要转折点,更是其在 AI 时代战略转型的明确信号。
这也表明苹果正试图通过构建一个开放的 AI 生态系统,为开发者和用户创造更多价值,同时也为自己赢得更广阔的市场空间。
言归正传,MiniCPM-Llama3-V 2.5 之类的端侧模型用实力证明了——模型不是只有「参数越大才能性能越好」,而是可以用最小参数撬动最强性能!
与此同时,步入生活只是第一步,当数据的旅程缩短至零,端侧模型让 AI 的反应比人类的思维更快一步,或许才能说明终端设备的下一个春天真的来临了。
到那时,用户与终端产品的每一次交互,都将引发一阵不由自主的「哇」声赞叹。
文章来源于“APPSO”,作者“莫崇宇”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
