# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源多模态SOTA模型再易主!
Hugging Face开发者大使刚刚把王冠交给了CogVLM2,来自大模型创业公司智谱AI。
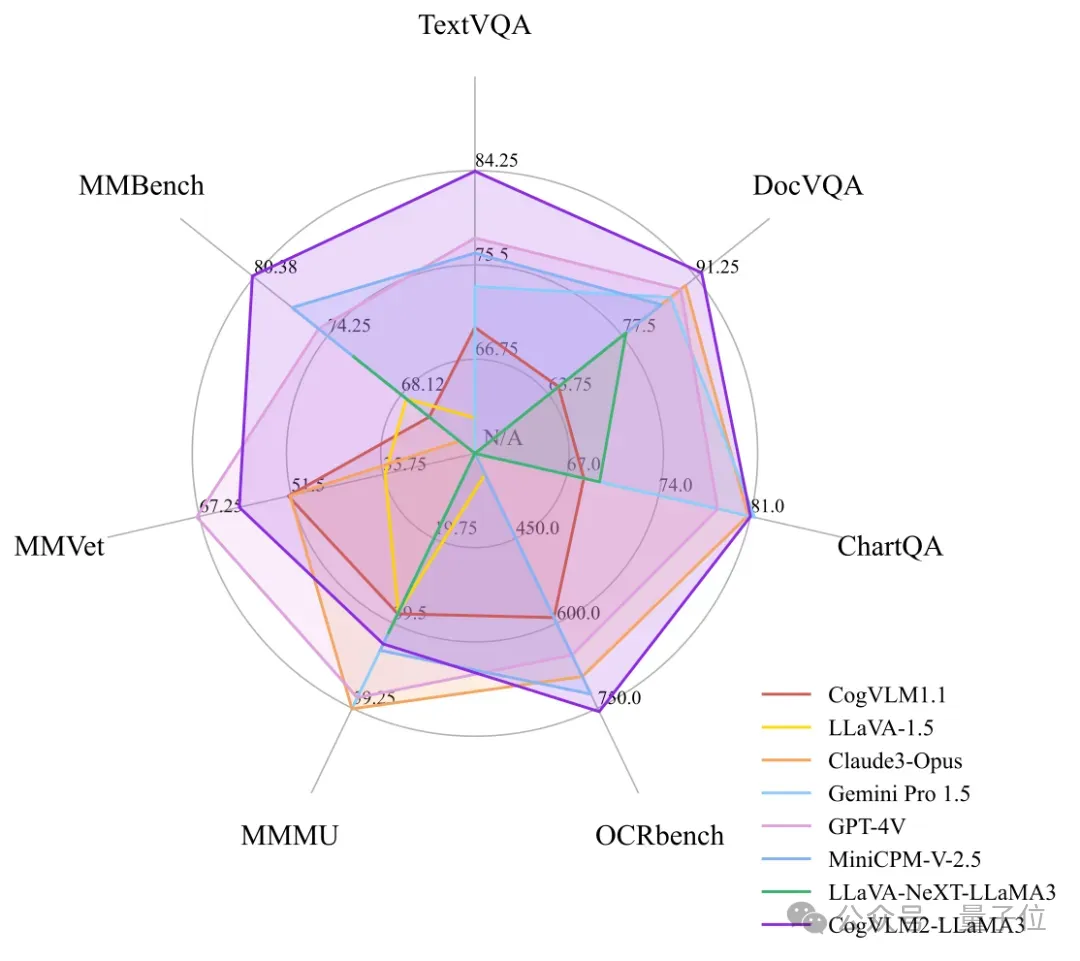
CogVLM2甚至在3项基准测试上超过GPT-4v和Gemini Pro,还不是超过一点,是大幅领先。
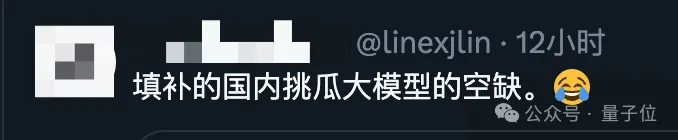
网友闻讯而来,发现ChatGPT新绝技之“AI挑瓜”,我们开源届也不缺了。
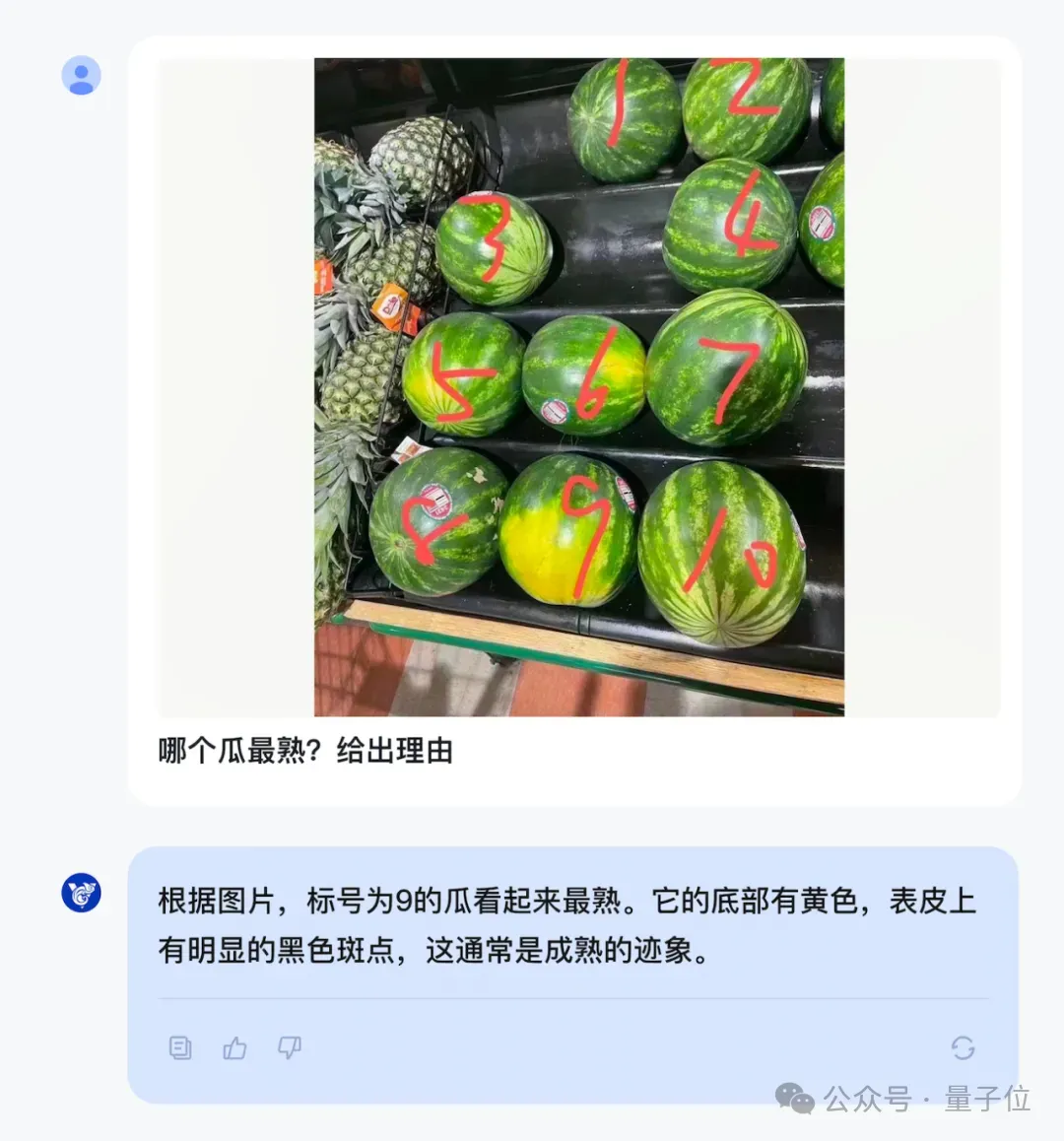
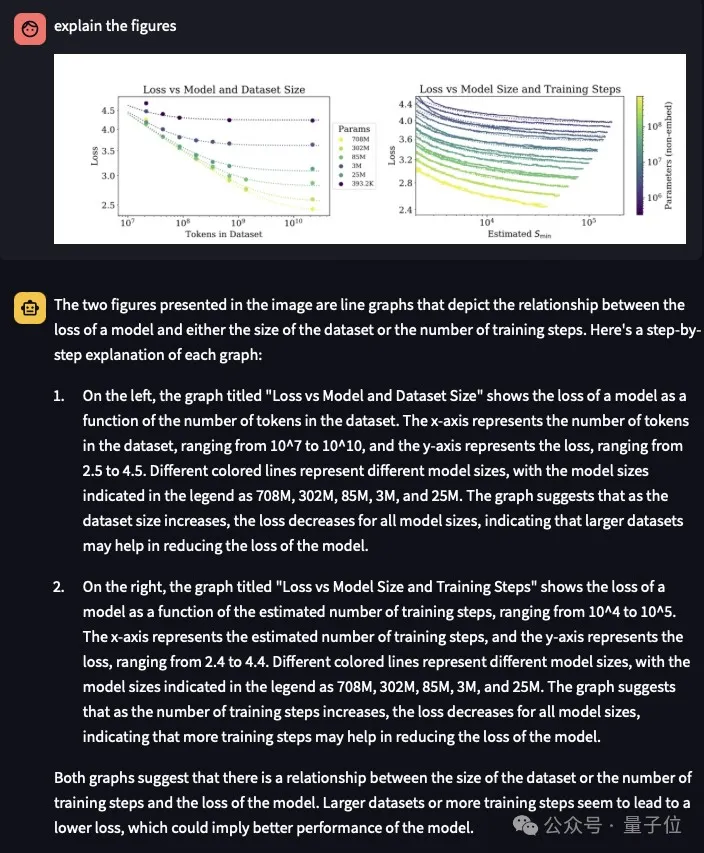
更复杂的学术图表,它也能理解并给出详细解释。
CogVLM2整体模型参数量仅19B,却能在多项指标取得接近或超过GPT-4V的水平,此外还有几大亮点:
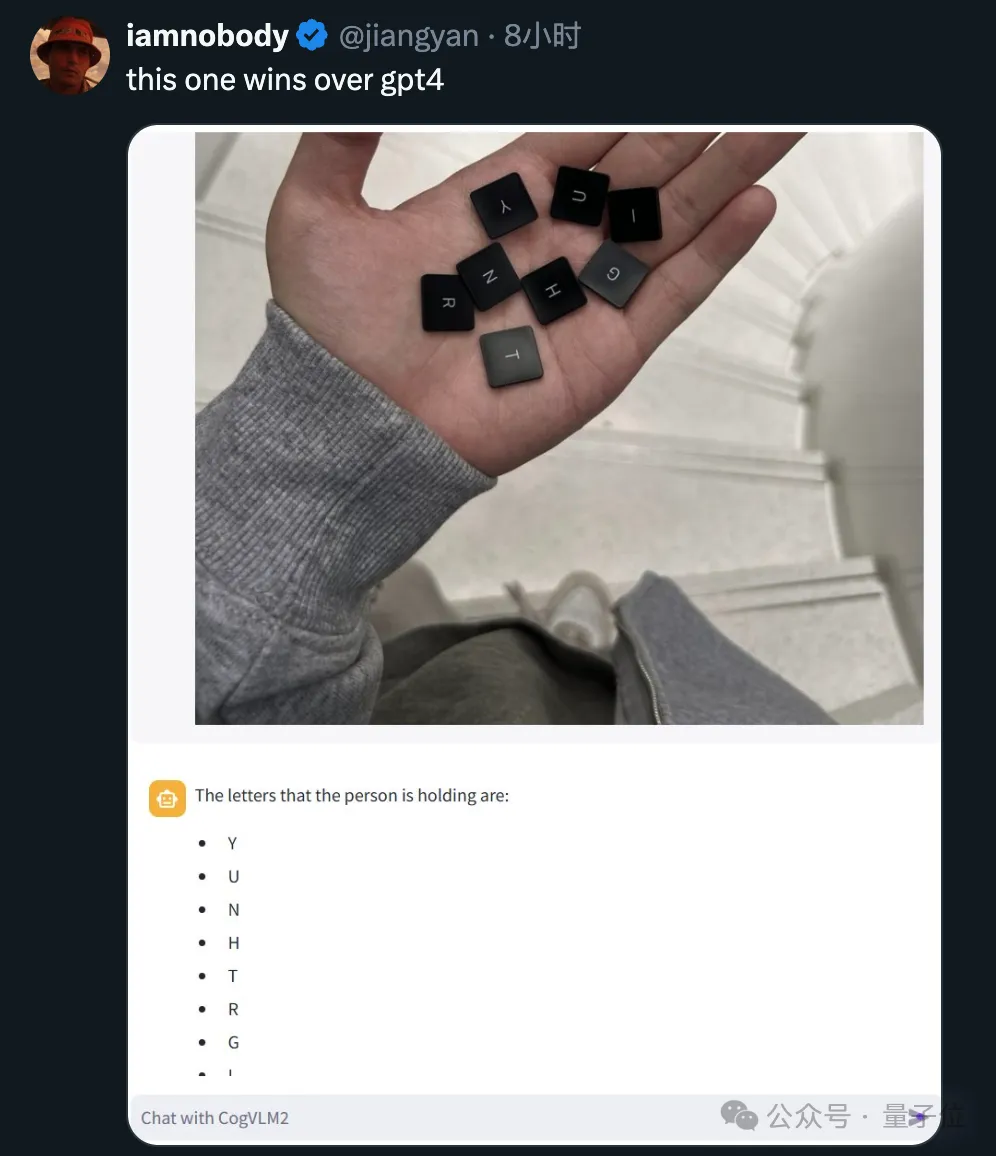
英文版经网友测试也有不错的表现。
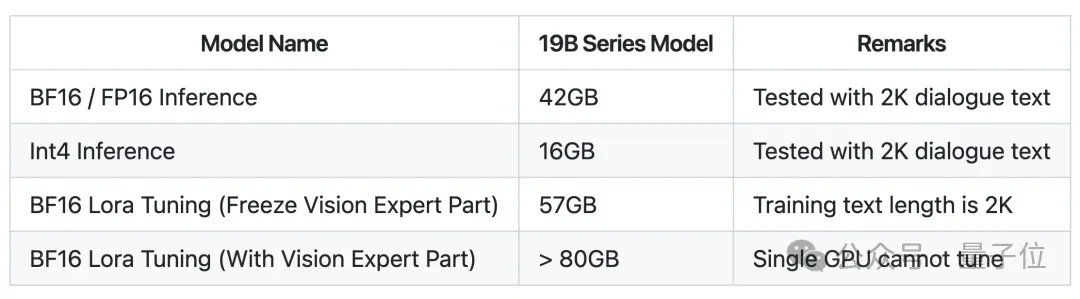
特别值得注意的是,尽管CogVLM2的总参数量为19B,但得益于精心设计的多专家模块结构,每次进行推理时实际激活的参数量仅约12B,这样一来,全量推理(BF16/PF16)需要42GB 显存。
接下来划重点了:
Int4量化版本,仅需要16GB显存。
也就是一张英伟达RTX4080,或者刚出不久的RTX4070 Ti SUPER就能搞定了。
性能不俗,算力需求也不离谱,以至于刚开源不久就在GitHub上小火了一把,各类开发者带着自己的场景来找团队咨询。
团队也贴心的表示,考虑到很多实际场景需要微调,专门给大家提供了Lora微调代码。
CogVLM2也提供在线Demo,感兴趣的话可以先试玩一下。
(试玩地址在文末领取)
好嘛,一般的小诡计还真骗不过它~
其实去年10月,团队就发布了CogVLM一代,量子位当时也介绍过。
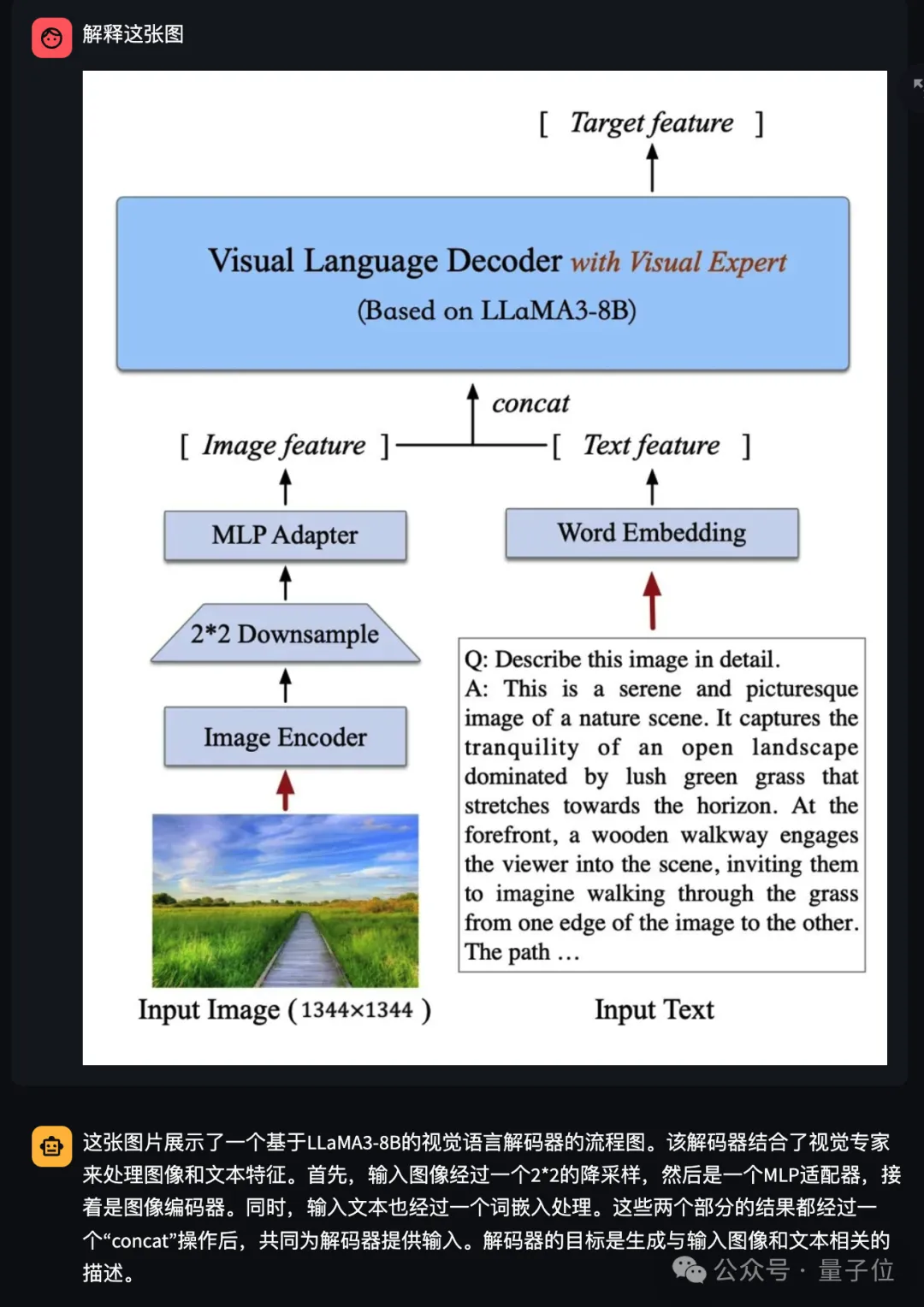
系列的核心思路,是给大语言模型的每一层都添加可训练的视觉专家模块,以实现图像特征和文本特征的深度对齐,而不会牺牲NLP任务的性能。
可以说是把视觉语言模型的训练方式,从图像文本的浅层对齐,转向了深度融合。

CogVLM2在继承这一经典架构的基础上,做了不少优化和改进。
语言模型基座升级成最新的Llama3-8B-Instruct,视觉编码器升级到5B、视觉专家模块也升级到7B,支持更高的图像分辨率等等。
特别是视觉专家模块,通过独特的参数设置精细地建模了视觉与语言序列的交互,确保了在增强视觉理解能力的同时,不会削弱模型在语言处理上的原有优势。
升级后能力有多强?
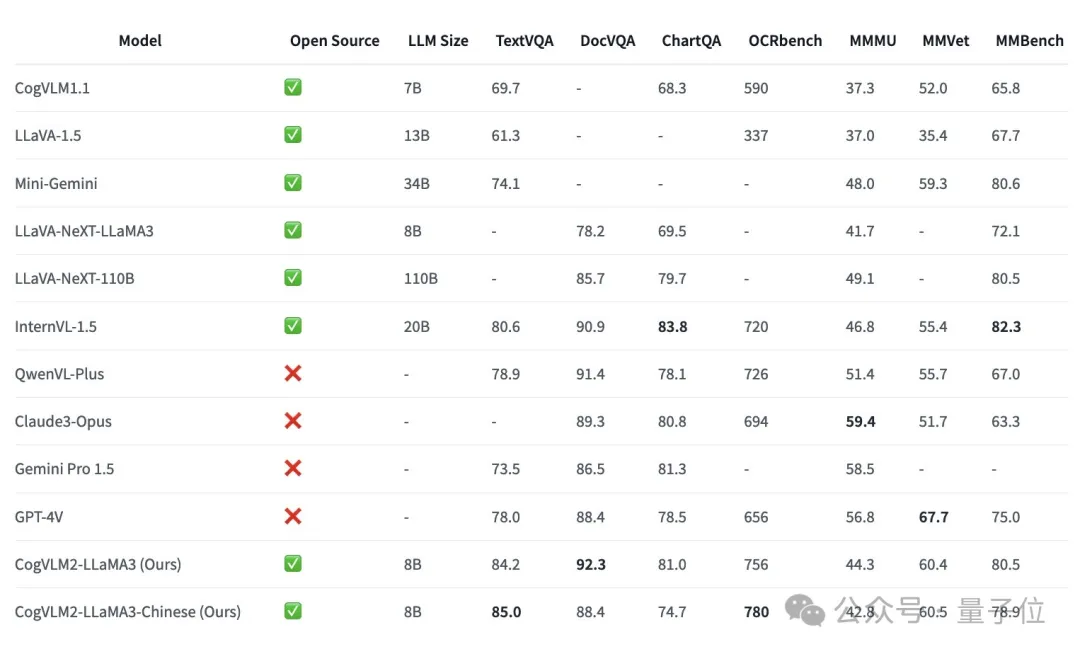
在不损失任何通用能力的前提下,在许多关键指标上有了显著提升,如在 OCRbench基准上性能提升32%,在TextVQA基准上性能提升21.9%,且模型具备了较强的文档图像理解能力(DocVQA)等。
也可以来个更直观的展示:
现在,复杂的模型架构图都可以让CogVLM2自己描述一遍,而一代的时候我们也测试过,当时还是有难度的。
为了更为严格地验证CogVLM的性能和泛化能力,一系列多模态基准上的定量评估更能说明问题。
CogVLM2的两个模型,尽管具有较小的模型尺寸,但在多个基准中取得 SOTA性能;而在其他性能上,也能达到与闭源模型(例如GPT-4V、Gemini Pro等)接近的水平。
可能有人会疑惑,Llama3系列是出了名的能看懂中文,但死活不愿意用中文完整回答,有一种各说各话、跨服交流的美。
怎么到CogVLM2这里,加入视觉专家模块之后,中文输出能力也这么6了?
我们就这个问题询问了智谱团队,他们表示为了解决这个问题可费了不少功夫。
团队判断Llama 3 8B Instruct模型的训练数据中可能包含了大量英文数据,而中文数据的比例相对较低。
找到问题,就能对症下药了:
首先,在预训练阶段,团队收集了大量的中文图文数据,涵盖了中文场景的各种情况。
特别是针对中文场景进行了OCR和文档等类型的数据收集。通过这些数据,我们使得模型在预训练阶段就能够充分接触和理解中文语境。
其次,在指令微调阶段也构造了一些高质量的中文数据。这些数据包含了各种中文指令和对应的回答,使得模型能够更好地理解和回答中文问题。在这个过程中确保中英数据的比例在一个合理的范围内,从而使得模型在处理中文问题时能够更加得心应手。
通过这些措施,CogVLM2在支持中文方面就有了显著的提升,无论是在理解中文问题还是在用中文回答问题方面,都成了亮点和优势。
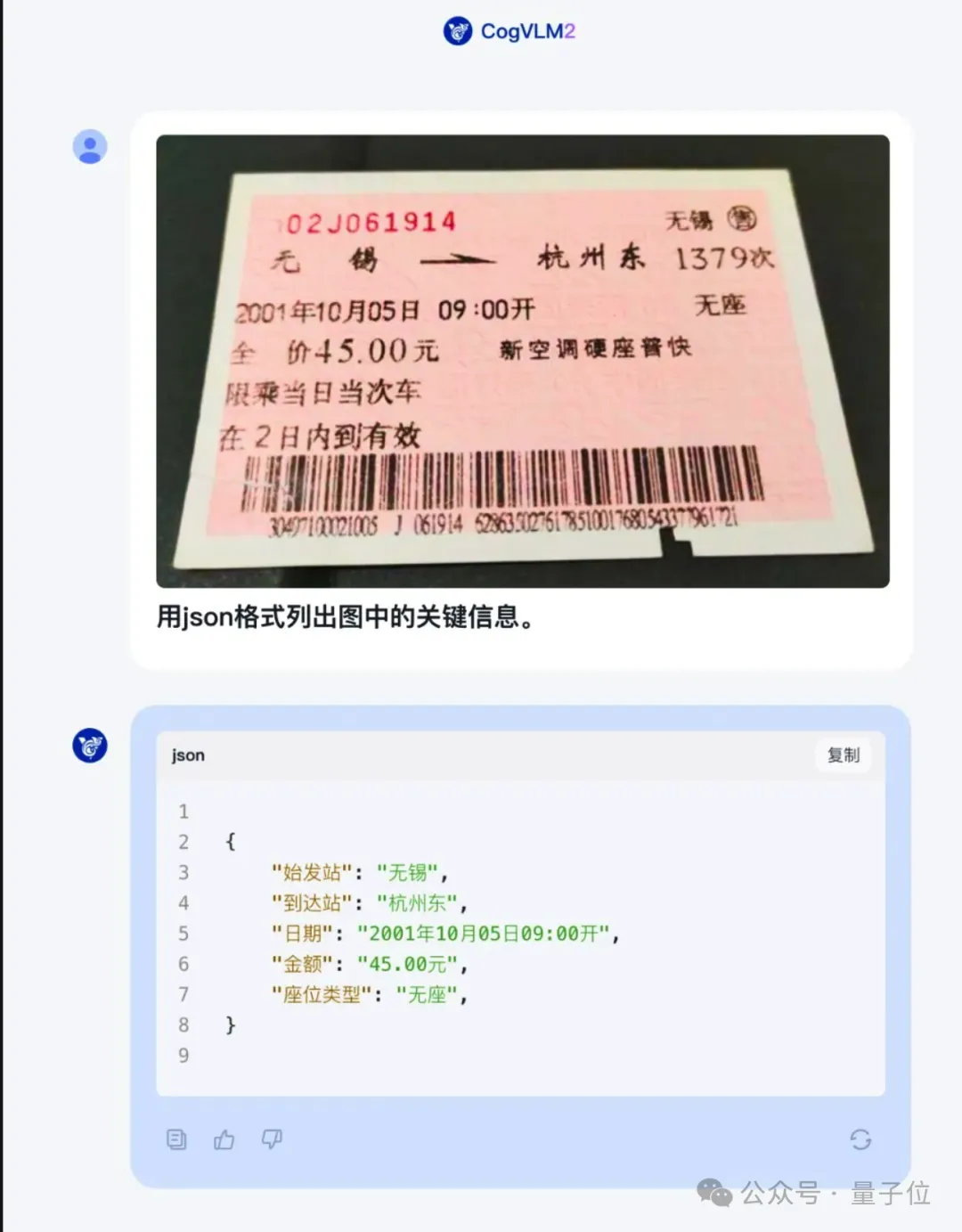
比如识别火车票信息,再整理成json格式,部分文字反光或者掉色也不受影响。
又或者识别并描述复杂户型图,连注释和水印都不放过。

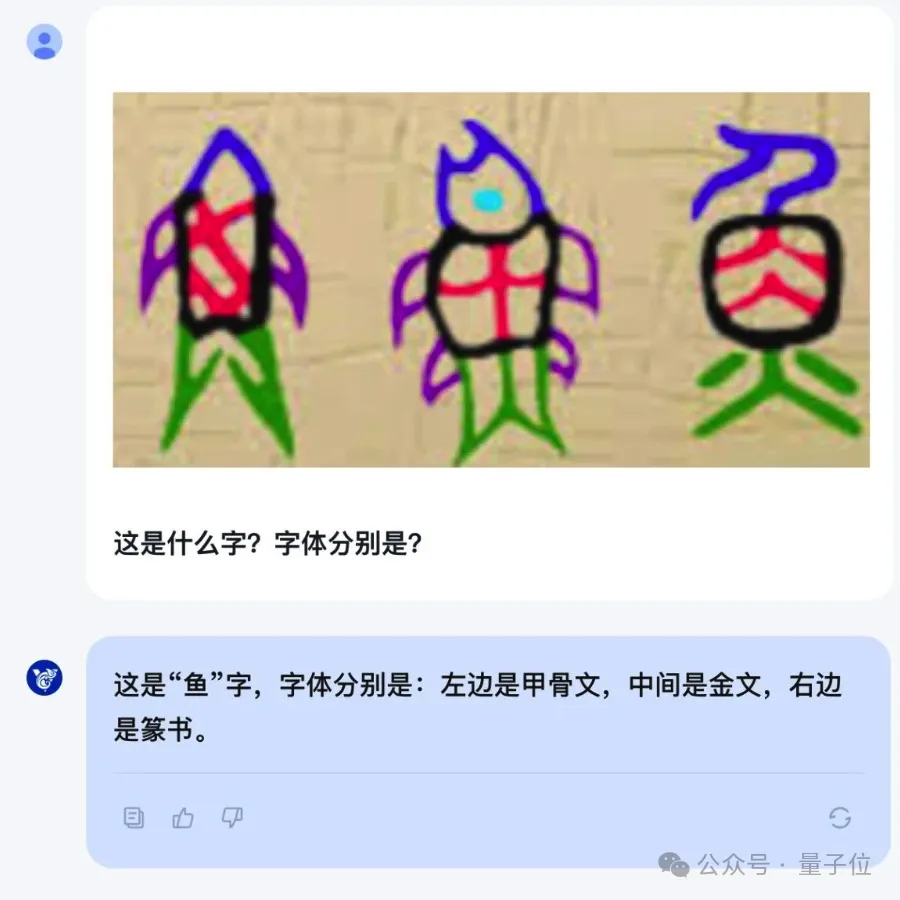
又或者识别中文手写字体。

甚至古代字体。
最后,奉上CogVLM2开源相关的一系列链接,感兴趣的朋友可以自取。
团队还透露,GLM新版本会内嵌CogVLM2能力,在智谱清言App和智谱AI大模型MaaS开放平台上线。
代码仓库:
github.com/THUDM/CogVLM2
模型下载:
Huggingface:huggingface.co/THUDM
魔搭社区:modelscope.cn/models/ZhipuAI
始智社区:wisemodel.cn/models/ZhipuAI
Demo体验:
http://36.103.203.44:7861
文章来源于:微信公众号量子位,作者:梦晨



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
