# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
5 月 22 日,百川智能发布新一代的基座大模型 Baichuan 4,并推出成立之后的首款 AI 应用——百小应。
作为百川的首个多模态基座大模型,Baichuan 4 相较 Baichuan 3 在各项能力上均有极大提升,其中通用能力提升超过 10%。百小应则是百川智能基于 Baichuan 4 的能力,将搜索技术和大模型深度融合,推出的懂搜索、会提问的 AI 助手,具备多轮搜索、定向搜索的能力,更精准理解用户需求,目前网页端(ying.ai)和 App 均已上线。
发布会上,百川智能创始人&CEO 王小川在进行了产品演示之外,还回答了诸多关于当下大模型技术发展和商业模式的问题,Founder Park 对其中的一些问答进行了整理,产品介绍部分来源于官方稿件。
01
百小应:让 AI 从工具变为伙伴
百川智能认为,不同于信息时代工具属性的产品,大模型创造的是新物种,让AI从工具变为伙伴。虽然受限于模型能力,当下的 AI 应用还无法完全做到如同人一样,能够使用工具、会思考、有情感等,但随着模型能力的持续提升,相关应用一定会逐步具备完整能力。
主打的多轮搜索,指的是针对用户提出的问题,百小应逐步解析,深入探究,解锁问题的核心答案。相比单轮搜索,在市场调研、产业分析等复杂场景下,多轮搜索能够有效地获取更专业、更有深度的信息。
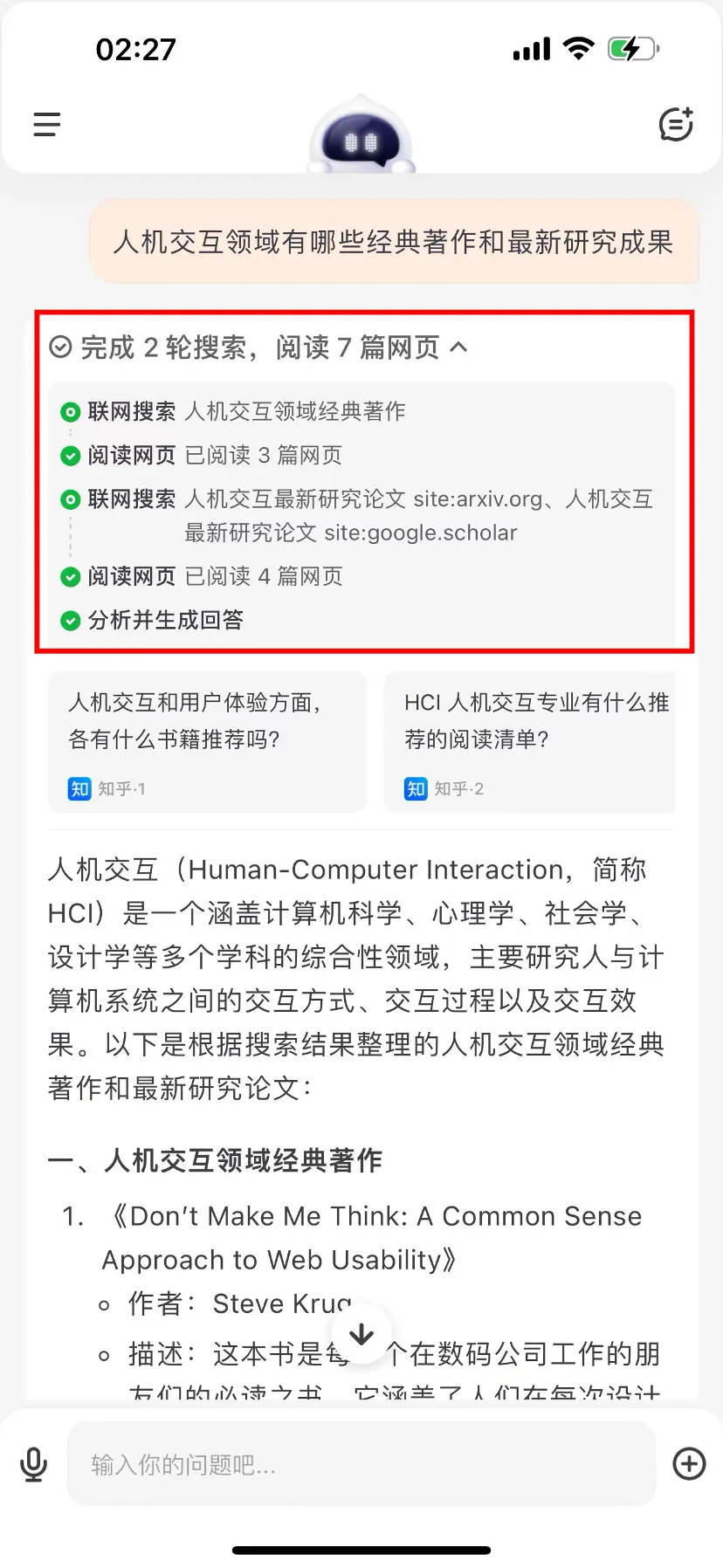
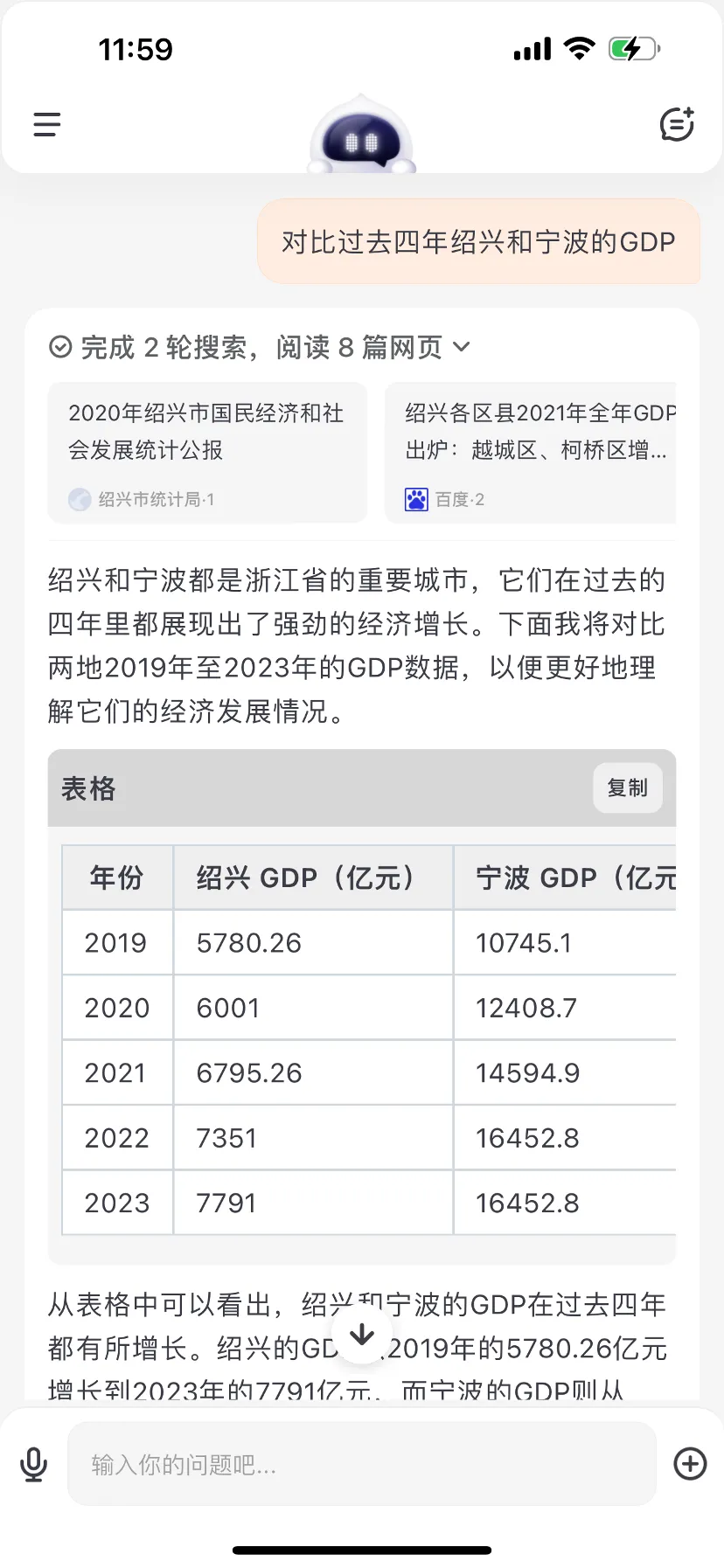
在搜索结果呈现方面,与其他在单次搜索后「简单总结网页信息」的应用不同,百小应将搜索结果作为观点、论据直接应用到问答结果中,能够将搜索结果以表格等结构化形式呈现,优化信息布局,便于用户快速定位、解读所需信息。
除了强大的搜索和提问功能以外,用户还能在百小应中上传 PDF、word 文档,或者直接输入网页链接,阅读并分析书籍、报告、学术论文等长篇内容。在 Baichuan 4 多模态能力的支持下,用户在提问的同时还可以同步上传图片,对图片内容进行解读,或者将图片作为补充材料,获取更精准的回答;并且,它还支持用户通过语音的方式进行交互。
02
大模型公司应该是
超级模型+超级应用
Q:很多模型公司都发布了自己的AI 应用,有些甚至去年就发布了,现在发布百小应,会不会有些晚了?
王小川:其实我反倒觉得早了,今天的大模型应用还需要更多时间的打磨。目前市场上的百万级 DAU 的 AI 应用远远算不上超级应用,现阶段更多都是模型能力的展现。
对我们来说,我们之前有输入法、搜索引擎和浏览器的经验,知道一个应用到达什么样的状态的时候才会变成一个广泛被使用的产品,现在各家的产品状态都还没到。今天发布的百小应,离我的想象还是有距离的,只是在行业内,我们认为需要有机会把它发出去,让行业对它有基础的了解,能够让团队转起来。
Q:你对超级应用的预期是什么样的?上亿用户还是?
王小川:超级应用应该是现在的应用的使用人数在刚需满足的基础上有几个数量级的提升,这个不光是我们自己,行业内的各家也都没有达到。100 万 DAU 不叫超级应用,这两个数量级从 100 万变成 1 亿,三千万到三亿之间我觉得才叫做超级应用。
但经过去年 4 月份到今年 5 月份这一年的时间,团队积累了足够的手感,做了大模型 AI、也做过超级应用,对于未来应用长什么样有期待。在 Baichuan 4 和百小应发布后,节奏上可以真正走向「双轮驱动」的模式,朝前迈进的时候会有里程碑,总得有这个「1」迈出去,使大家有经验和有试水,能把两种信息都融汇在一起,能使这个团队走得更健康一些。
Q:如果百小应想要成为一个超级应用,它应该具备什么样的特点,如果想让用户用起来,它应该切中用户什么样的诉求?
王小川:首先可靠性得高,今天模型在用的时候可能是 60%、80% 的可靠性,有时候灵,有时候不灵,还有些基本的必要条件,在可见的未来里模型一定要跟搜索做结合,因为模型是一个推理引擎,它对知识了解度不够,有了搜索之后,使得它的知识的广泛程度和真实度能得到提升,这是一个基本条件。
第二是能跟用户对话,有充分理解用户意图的能力。如果想成为用户的助理,一定要知道用户想要什么。继续往超级应用走的话,AI 会更多像行业里的职业人士一样,而不是现在还是很泛的状态,什么都懂一点。
以当下大家关注的机器人为例,今天做机器人都有两个特点,一个是做人形,为什么做人形而不是滚轮的,这是很重要的一件事情,当做人形的时候才能帮它更好融入今天的环境,让它懂得怎么开冰箱门,怎么坐电梯。做其他形状的时候,它没法和今天的物理环境进行很好的互动。
第二,它的学习样本要来自现在的人类社会,像人一样的工作,也要像人一样做学习。如果你想做 AI 的炒菜锅和 AI 炒菜机器人,以前的逻辑一定是做 AI 炒菜锅,今天做一个会炒菜的机器人比做一个炒菜锅更容易。因为炒菜机器人有大量的数据可以学习,看人是怎么炒的,要做炒菜锅还要有额外的设计。
因此,像人一样工作,像人一样学习,这件事情是 AI 发展的路径。最后就会变成一个职业人士,往下会变成 AI 律师,AI 医生,AI HR,这种情况下我觉得就可能变成超级应用。
Q:ChatGPT 算超级应用吗?
王小川:还不到,我觉得如果 OpenAI 足够用心,超级应用它能做,以它现在的技术是有机会的,但是由于这个公司自己的基因,没有往产品方向投入太多精力。
Q:如何看待 Kimi 最近推出的打赏模式?
王小川:我觉得挺好的,就应该把 AI 像人一样去做,我觉得这是正确的商业理念。
刚才提到大模型是一个新的物种,以前做超级应用大家路径老想做工具,去年我们提一个概念「从工具变成伙伴」,这个概念大家应该接收的比较多。有两个例子,年初的时候一个大公司的高管跑来跟我们聊,说大模型不靠谱,七位数的乘法都不会做,你要是(把它)当成计算机,七位数的乘法不会做那是很闹心的,但是人也不会,在座的各位,我相信没有一个人能把七位数的乘法做出来,我们要把大模型当成人一样思考,而不是把它当机器一样思考,你要是当机器,调用计算器就行了,要当伙伴来想。
Kimi 搞了打赏,很惊艳、很惊喜,同样的理念,不是当成工具在想,不是为工具买单,而是当成一个伙伴,当成一个人,Kimi 和它的朋友,累了休息一下,整个路径里面强调未来新的超级应用不要把它当成工具用,而是伙伴来看。这是我们去年提到的能产生陪伴,有知识,有经验,并能提供服务的概念。
Q:在超级应用这个产品定义上,C 端是不是可以后来者居上?
王小川:每家选择的路径和方向是不太一样的,有的做模型,也有的做应用。但把模型跟应用做成两个公司,我觉得也可能会出问题。模型是模型,应用是应用,模型做大了不代表应用做好,就像两个车,放在一块,到底以后的资源精力投在模型还是应用上,不是一回事。
模型和应用的平衡,这是每个公司最顶层的战略要考虑的问题。
Q:现在各家除了打价格战,营销战也蛮猛的,你们的应用也出来了,会不会有类似的打法和策略?
王小川:可能不太一样,因为我知道现在各家有的为了获客 1 个用户 200 块钱,还不说获客之后提供服务的费用,我觉得这只是竞争过程中大家为了能赶快出去,能尽快拿下下一轮融资的举动,我认为并不是健康的行为。因为百川也会公布我们融资的情况,我们手上有足够的资金,我不是通过立马发一个东西出去,这种不健康的状态,去拉下一轮的融资。因此我们会走得更健康一些,会把我们的精力在产品价值的体现,我们认为我们团队是有足够多的历史经验的。什么是好的产品,好的产品出去之后一定会得到用户认可的,跟今天的同行是不一样的,这个产品发布之后,肉眼可见会进入后一个时期。
03
降价是云厂商的传统打法
百川不会参与
Q:刚才提到未来百川新的模型发布节奏延长到每个季度,在百川看来无论是国内还是国外的公司,大模型技术方面是否遇到更大的挑战或瓶颈,前沿的探索是不是变得更难了?
王小川:我们去年提了一个概念,理想慢一步,落地快三步,这是针对美国的提法。其实在模型探索当中,从 0 到 1 的突破,美国从资金的储备也好,还有他们科学家的文化也好,都比国内强很多。所以在探索的道路里确实成本会很高,可以简单讲,每一次重大的技术突破都是美国引领的,他们做到了,我们再去跟,在模型上有 GPT-4、GPT-4o 的发明之后我们再去跟,使得我们能大大降低国内成本的投入,这样能把精力更多放到怎么能把用户端做好。
模型的瓶颈,至少在我心里 Sora 和 GPT-4o 不代表最大的突破,传说中的 GPT-5 有一些 delay,到年底才能看得出来。
Q:如何看待最近由 DeepSeek 带起的,各家大模型厂商参与的大模型降价的行为?
王小川:之前提到过,我认为大模型厂商一定要有自己的超级应用。如果只是学习 OpenAI,有个模型,然后做 API 的服务,对于创业公司来说,在中国是走不通的。一方面是因为在国内的商业环境里,ToB 的市场比 ToC 小十倍,ToB 传统公司确实做得更大。另外,可以预见到 api 这块大厂肯定来卷,这都是他们的射程范围内的。对于创业公司来说,只靠价格低,竞争力其实是不够的。
所以第一天就要双轮驱动——超级模型+超级应用,这是充分必要条件,不能只有应用没模型或者只有模型没应用。
对于降价行为本身,我觉得是大家都太看好这个时代的前景,不愿意失去任何机会,宁愿 0 价格也要入场。
第二,降价我认为核心要看你的商业模式是什么,如果你是做 ToB 服务的,降价最后卖的不是模型本身,卖的是整套云服务,所以云厂商是比较偏传统的服务模式,进到一个新的战场,这次降价仅限于云服务厂商的动作。
这波降价跟之前的滴滴美团降价还不一样,因为那时候的价格战或补贴背后带有网络效应,是双边的网络,商业模式在改变生产关系,司机和乘客的关系,外卖员和用户之间的关系。所以那个是建立双边网络效应,而这次降价是 B 端的降价方法,而不是像滴滴美团这样的价格竞争,我觉得这并不像 C 端,这次不是生产关系改变,而是直接做生产力供给,将 AI 直接供给生产力。
我觉得这件事情对我们而言,就是别掺和进去。
Q:如何看待今天的推理成本下降?
王小川:首先,推理成本下不下降跟用户规模没有什么关系,不是用户多了下降,更多还是技术本身的进步,不管是底层 GPU,从算力层到上面 infra 的建设到模型联动,所推理成本指数级的下降确实是技术进步带来的一件事情。
今天大厂降低 token 价格,我相信大厂也预期未来模型的成本会降低特别多,也许今天亏钱,再过一年就不亏钱,这种情况下大厂商也不是考虑短期亏损的问题,而是考虑未来预期有没有机会模型降到足够的便宜。我觉得大家对模型降价本身也有推理成本的降低的预期,就是因为技术进步。
Q:如果长文本卷到无限长以后,还有什么方向可以发展?
王小川:还有推理能力,做数学题,或者能有更多的思考,今天的模型自洽性都不够,模型思考的严谨性,有足够好的逻辑,都是更加重要的事。我倒不觉得长文本是它唯一的事情,现在国内也知道模型长文本很重要,但是它只是做大的必要条件,也不是充分条件。
在充分条件里面我认为模型本身往下更要强调内在的自洽性和它的推理能力,这两件事情并不是靠长窗口去解决的。
Q:如何看待百小应和秘塔在搜索结果呈现上的差异?这种差异是技术上的设计造成的,还是说有其他的原因?
王小川:我们的应用分粗读和精读,粗读的东西背后搜的网页更多。它之前一直在看东西,但是显示出来是少的,是它认真读的。没把粗读的东西放进来。第二块可以对比搜索效果,当你提出问题看看结果怎么样,读更多文章本身不是技术瓶颈问题,还是技术理念和产品实现的选择问题。
Q:如何看待生成式 AI 给搜索带来的机会?AI 跟搜索结合是百川的方向吗?
王小川:搜索在国外国内的现状不一样,国外 Google 绝对是老大哥的状态,国内百度是不断被抢份额的状态,最早购物被淘宝做了,旅游是携程,生活经验是小红书,再往下,AI 发展之后,在大的趋势里我觉得依然可能是百度搜索被抢份额的状态。
如果仅仅使用模型来对搜索做总结,我认为这种做法在价值创造和竞争力方面,是走不出大厂射程的。
文章来源于“Founder Park”,作者“Founder Park”




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
