# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,一个4年前的开源项目穿越了时空,突然爆火!
毕业于哈佛,前Quora数据科学主管,现工作于Waymo的Lili Jiang,在20年初编写了一个软件,
通过可视化的「小球下山」,帮助非专业和专业人士,更好地理解AI训练中梯度下降的过程。

软件名为Gradient Descent Viz,囊括了当下最常见的5种梯度下降算法:Vanilla Gradient Descent、Momentum、AdaGrad、RMSProp和Adam。
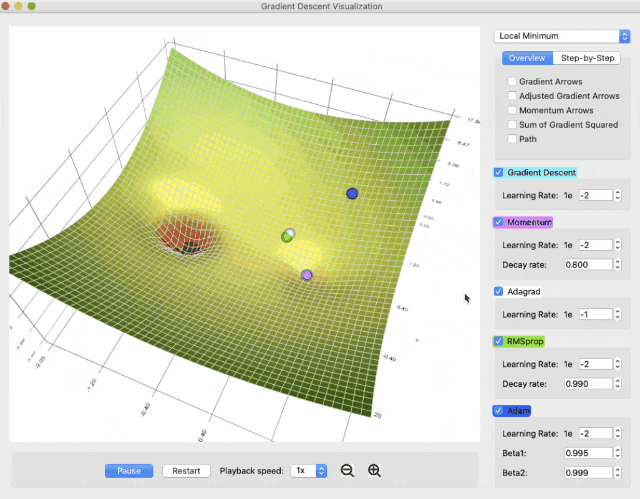
你可以选择不同的曲面,并发现Adam和RMSProp可以更好地处理鞍点:
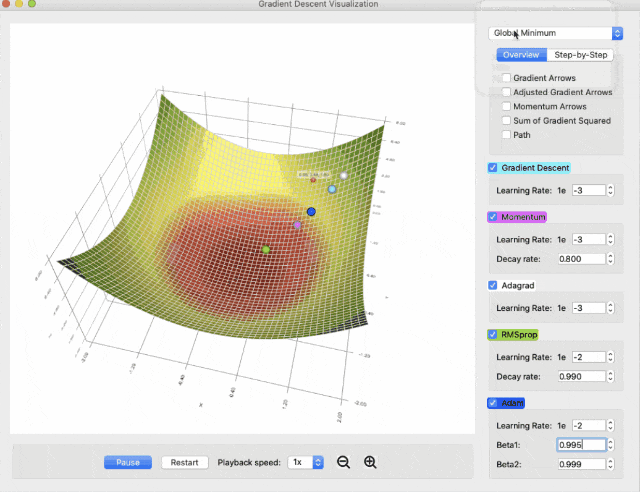
可以调整参数,并发现学习率低时,动量法不足以推动小球通过平坦区域,而提高学习率可以解决问题。
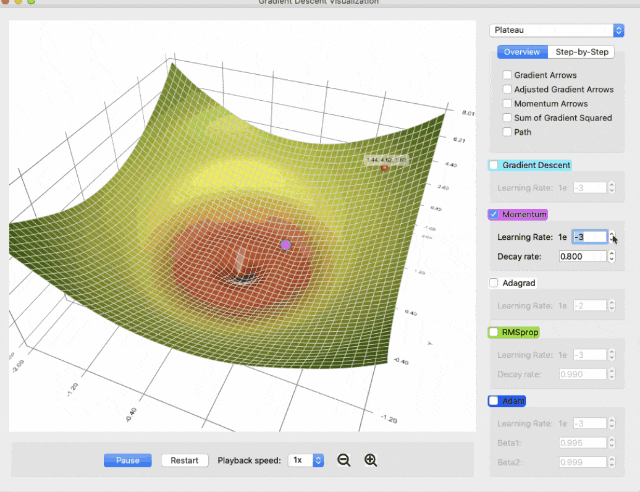
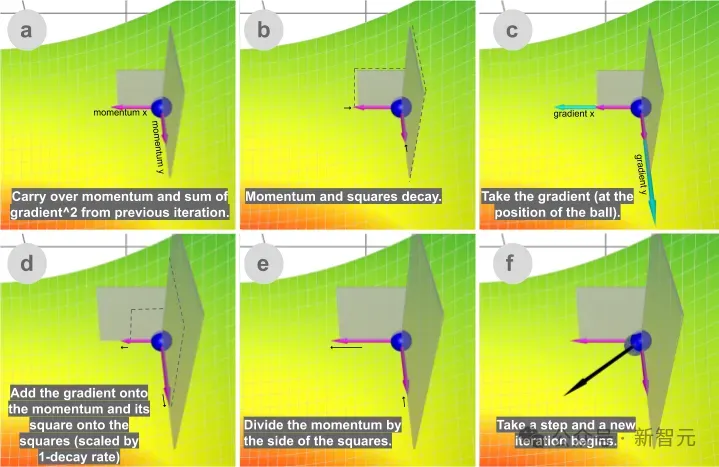
可以观看分步动画,直观地了解每种方法的计算过程,比如动量下降的内部工作原理:
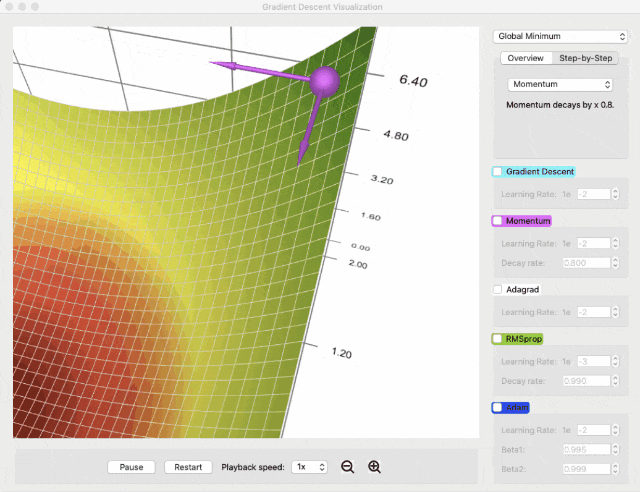
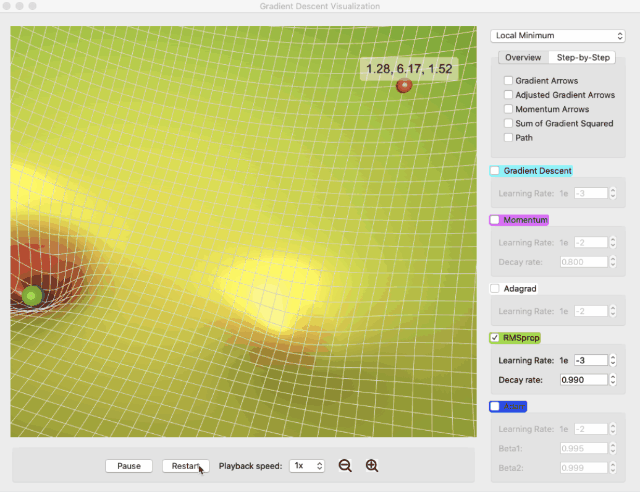
可以使用可视元素来跟踪梯度、动量、梯度平方和等数据,比如下图中的两片灰色代表两个方向上的梯度平方和:
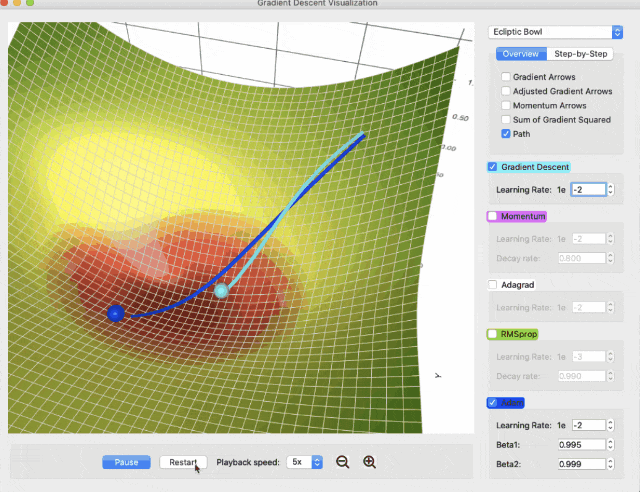
可以绘制下降路径,以了解不同的算法如何以不同的方式到达目的地:

项目地址:https://github.com/lilipads/gradient_descent_viz
OK,介绍完毕,下面上点硬菜,结合大佬给出的可视化展示,解释一下梯度下降的几种优化算法的原理。
(小编水平有限,如有失误,烦请诸位指正)
AI训练的本质:从小球下山开始
众所周知,AI训练的目标是让预测值尽可能接近真实值。
可以按照某种方式,定义预测值和真实值之间的误差,也就是损失函数,比如最常用的交叉熵损失函数。
要让误差最小,也就是求损失函数的最小值。
为此,我们需要一个好的算法来快速可靠地找到全局最小值(不会卡在局部最小值或者鞍点)。
真实的神经网络中,参数千千万,不过我们人类(包括小编)一般情况下只能感知3维的事物,
所以,下面先用两个参数x,y对应的损失函数Z来理解这个问题。
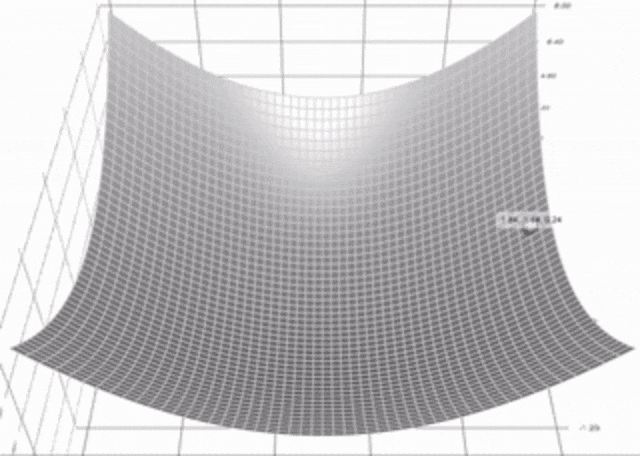
下面的曲面表示损失函数Z(x,y):

在这种情况下,我们可以使用「一眼看出」大法,马上发现曲面最低点的位置(也就是损失函数的最小值),——但计算机程序不能。
人眼可以看到整个曲面,而算法只能一步步进行探索,就像拿着手电筒在黑暗中行走。
如上图中的演示,算法需要每次找到一个最佳的前进(下降)方向,然后移动一段距离,——这个最佳的方向就是梯度(函数对每个参数的偏导)。
根据我们小学二年级学过的知识,当二元函数Z在(x,y)点可微时,函数值变化量可以写成:
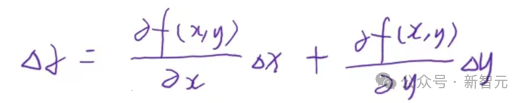
改写成向量内积的形式就是:
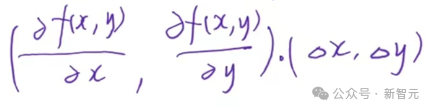
我们需要让函数值下降得越快越好,那么x和y的改变方向,就应该和梯度(两个偏导)的方向相反,——即向量方向相反,内积最小:
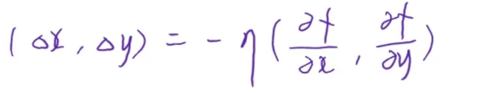
这就是「梯度下降」的意义,梯度前面的系数是我们熟悉的学习率,用来控制每次移动的步长,步子太小训练慢、步子大了容易扯着蛋。
如果我们「深入浅出」,把问题退化到一元函数,就是下面这个样子:
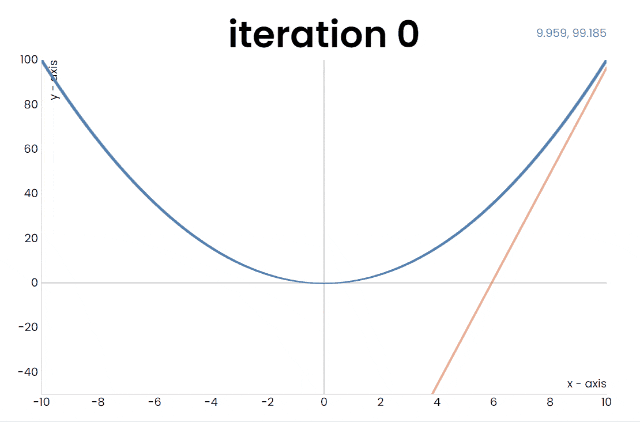
当然了,最原始的梯度下降算法,需要对网络中所有参数求偏导再求和,计算量相当大。
我们现在用的梯度下降算法,一般指的是随机梯度下降(Stochastic Gradient Descent,SGD),表示每次迭代只随机使用一个样本或一个小批量(mini-batch)来计算梯度。
当我们使用梯度下降的时候,可能会遇到下图中这种问题:
代表梯度下降的红线在寻找极值的过程中振荡比较严重,相应的也需要更多的步数才能收敛。
这是因为每个点的梯度可能和最终的方向差别比较大,——为了解决这个问题,科学家们提出了动量法,也就是下图中蓝线的路径。
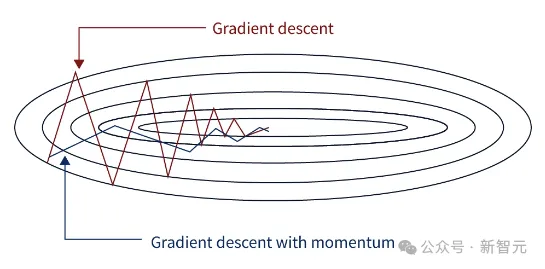
动量法的思想就是把历史的梯度也考虑进来,用整体的趋势让路径变得更加平滑。
另一种简单理解就是,振荡来自于前后两点梯度的垂直分量方向相反。作为矫正,当我们遇到这种反向的情况时,可以将当前的垂直分量减小一点。
而前后两点梯度的水平分量是同向的,所以可以将当前的水平分量增大一点。
——把过去的梯度按照一定比例加到当前梯度,正好可以满足这两点。
动量法可以用公式表示为:
delta = - learning_rate * gradient + previous_delta * decay_rate
或者突出累积梯度的概念,表示为:
sum_of_gradient = gradient + previous_sum_of_gradient * decay_rate
delta = -learning_rate * sum_of_gradient
两个公式是一样的,其中衰减率decay_rate,控制历史梯度信息进入的比例,一般情况下设置为0.8-0.9。
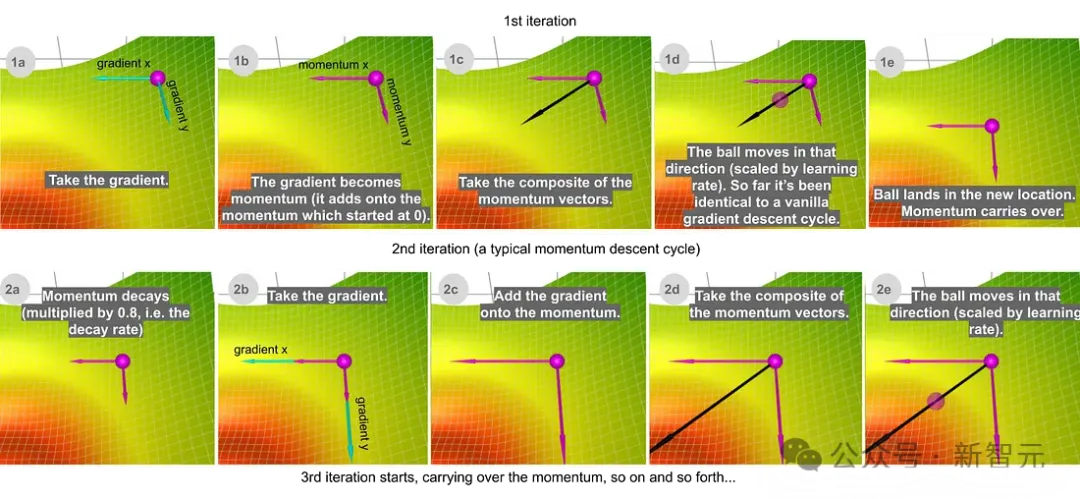
另外,这个公式是一个递归的表示,所以距离当前时刻越远的梯度会被decay_rate衰减得越多(指数级),
这样既保证了整体的趋势,又不会过多的被遥远的梯度所干扰。
我们可以利用本文的开源软件形象地了解动量法,以及其中参数的意义,比如当decay_rate为0时,就与普通的梯度下降完全相同;
而当decay_rate = 1时,小球就像在没有摩擦的碗中那样,孤独摇摆,永无休止。
下图中,普通梯度下降和动量法在软件中PK了一把:
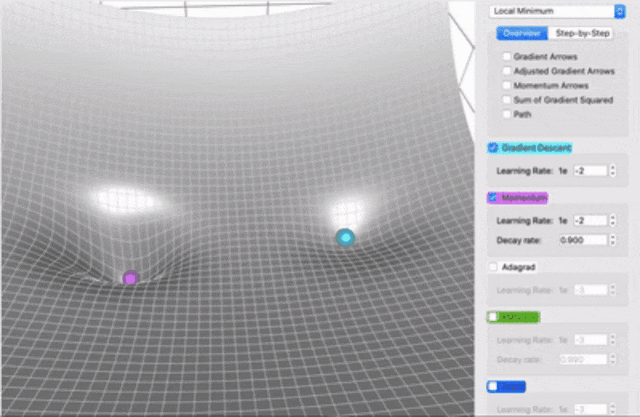
可以看出,Momentum相比于Vanilla Gradient Descent有两个明显优势:
1.积累了过去的动量,所以跑得快;
2.动量法有机会逃脱局部最小值(也是因为来自过去的力量把它推了出去)
前面我们提到了学习率的问题,学习率设置过大或过小都会出问题。
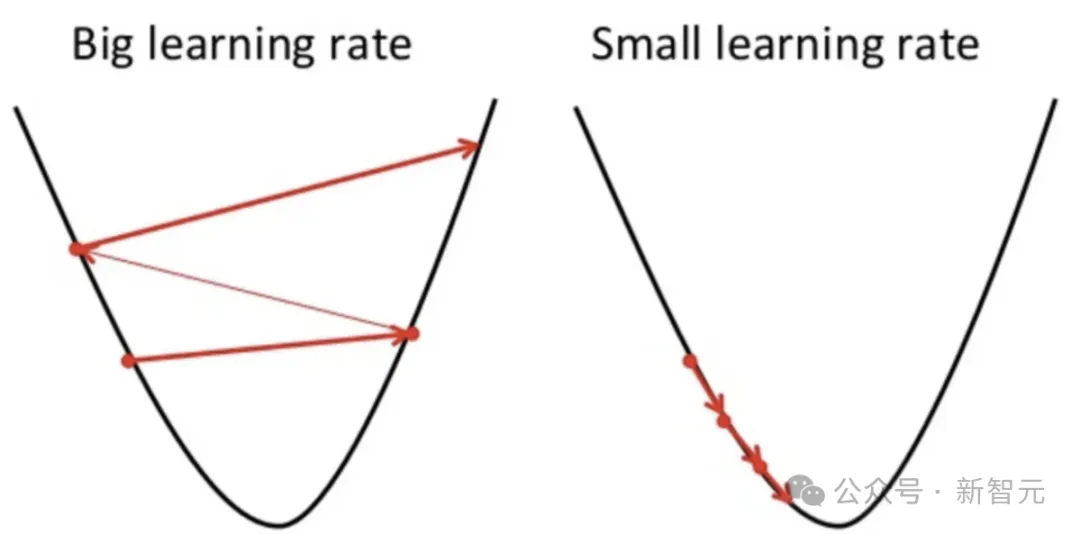
在实际训练中,学习率一般会人为设定在迭代中不断衰减,使得开始时可以快速深入,然后逐渐减慢速度,仔细探索。心有猛虎,细嗅蔷薇。
不过同样的,学习率衰减太快或太慢,也都会出问题,所以科学家们提出了AdaGrad算法来自适应调整学习率。
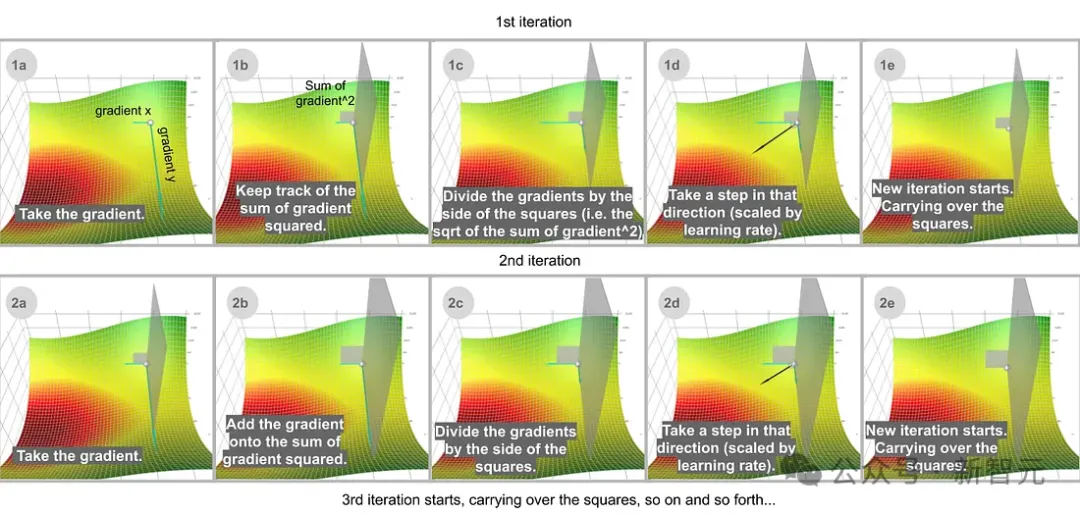
AdaGrad可用公式表示为:
sum_of_gradient_squared = previous_sum_of_gradient_squared + gradient²
delta = -learning_rate * gradient / sqrt(sum_of_gradient_squared)
其实就是跟动量法类似的思想,使用历史梯度数据来校正当前数据。
这里给学习率除上一个历史梯度的平方和开根号,直观的理解就是:对于一个参数,在过去修改得越多,那么在未来需要修改得就越少。
这样就达成了学习率的自适应调节,而且每个参数有自己的学习率。
另外,在深度学习中,稀疏特征是非常常见的,而AdaGrad算法在面对稀疏数据时尤其有效,
稀疏的特征平均梯度很小,会导致训练缓慢,而为每个参数设置不同的学习率则解决了这个问题。
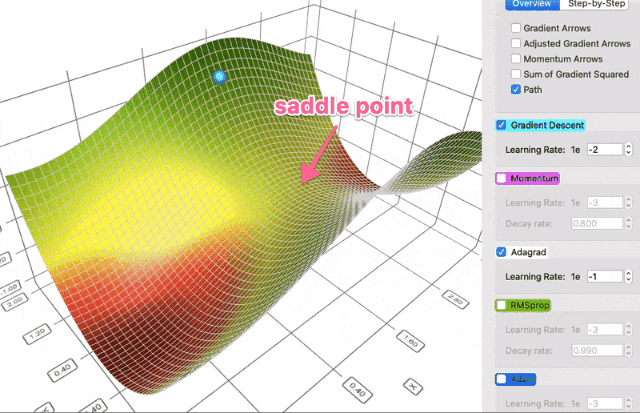
上图中,AdaGrad和Vanilla Gradient Descent进行PK,普通梯度下降会先选择最陡峭的方向,而AdaGrad选择的路径显然更优秀。
有时候,普通梯度下降会干脆停在两个方向的梯度为0的鞍点(saddle point),而AdaGrad等基于梯度平方的方法可以更好地逃离鞍点。
然而,AdaGrad的问题在于它的速度非常慢,——因为梯度平方的总和只会增长,永远不会缩小,就造成了学习率一定是越来越小的。
由于背上了沉重的历史包袱,AdaGrad在该快的地方也往往快不起来,为了解决这个问题,便诞生了RMSProp算法,公式如下:
sum_of_gradient_squared = previous_sum_of_gradient_squared decay_rategradient² (1- decay_rate)
delta = -learning_rate * gradient / sqrt(sum_of_gradient_squared)
跟动量法中使用衰减率decay_rate的思想一致,让最近的梯度占比比较高,而离得比较远的梯度就赶紧忘掉,说白了就是移动加权平均。
不过跟动量法那边不同的是,这个 (1- decay_rate)是在分母上,所以还起到了缩放的作用。
举个例子,如果decay_rate设置为0.99,那么分母就多乘了一个sqrt(1 - 0.99)= 0.1,因此在相同的学习率下,步长比AdaGrad大了10倍。
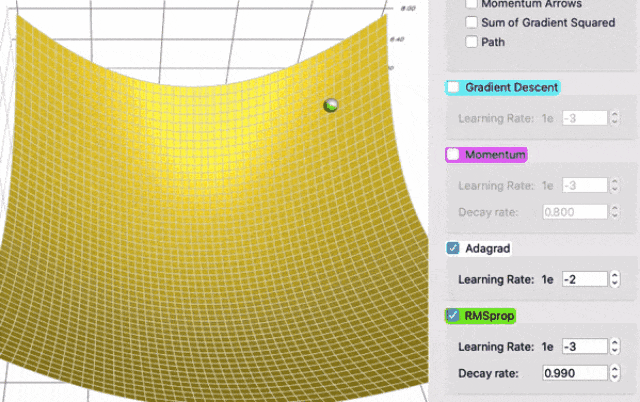
图中的阴影部分表示两个方向上的梯度平法和,明显绿色的RMSProp甩掉了很多历史包袱,跑得也更快。
最后出场的是当下AI训练最流行的Adam算法,但已经没啥可说的了,因为Adam = Momentum + RMSProp,公式如下:
sum_of_gradient = previous_sum_of_gradient * beta1 + gradient * (1 - beta1) [Momentum]
sum_of_gradient_squared = previous_sum_of_gradient_squared * beta2 + gradient² * (1- beta2) [RMSProp]
delta = -learning_rate * sum_of_gradient / sqrt(sum_of_gradient_squared)
Beta1是Momentum的衰减率,通常设置为0.9;Beta2是RMSProp的衰减率,通常设置为0.999。
Adam从Momentum中获得速度,从RMSProp获得适应不同方向梯度的能力,两者结合使其功能强大。
参考资料:
https://github.com/lilipads/gradient_descent_viz
文章来源于:微信公众号新智元




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
