# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

你或许在影视剧中常见到这样的场景:几派势力在争夺地盘时枪支举起,彼此对峙,人人都不敢扣下扳机,人人又都想扣下扳机,一场火拼,一触即发。
这叫做“墨西哥僵局”,指对峙的多方因互相牵制而形成的微妙平衡。
如今这种僵局,在AI领域被打破了。扣动扳机的人,是OpenAI。
5月14日,OpenAI发布GPT-4的升级版——GPT-4o,并宣布向所有人免费开放。
一天后,大洋彼岸的枪声终于传来,火花划过此处沃土。
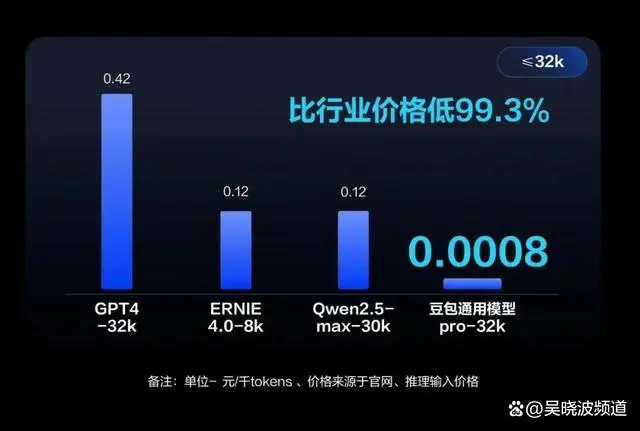
5月15日,字节跳动宣布旗下豆包主力模型,输入价格为0.0008元/千Tokens(Token是大模型使用的输入数据的最小单元,比如单词或字符等)。
子弹开始呼啸而过。
6天后,也就是5月21日,阿里巴巴宣布通义千问主力模型大幅降价,主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%,立即生效。
四小时后,百度跳过降价,直接宣布,旗下大模型文心一言的两款入门级产品ERNIE Speed和ERNIE Lite免费。
一天后,后知后觉的科大讯飞与腾讯,也纷纷宣布:讯飞星火API能力免费开放,讯飞星火Lite API永久免费开放,讯飞星火pro/Max API价格降至0.21/万Tokens;
腾讯的混元大模型全面降价,其主力模型之一的混元-lite模型价格从0.008元/千tokens调整为全面免费。
……
枪响,人灭,在这种场景下似乎并没有发生。但没有人会怀疑,在接下来的时间里,这种事情不会发生。
毕竟当一个行业的竞争,以价格战的形式出现在大多人眼前时,往往意味着行业内的企业,已经到了势同水火的地步。
不过企业们对价格战也有自己的解读,例如火山引擎总裁谭待说:“亏损换收入不可持续,我们不会这么做。”
又例如阿里云智能集团副总裁刘伟光说:“AI推理成本只有每年有十倍甚至百倍的降低,才能真正推动行业各行各业的AI应用的爆发。”
若要再往前追溯,私募基金幻方量化大模型DeepSeek与智谱AI的入门级大模型降价得更早:
5月7日DeepSeek宣布将旗下大模型DeepSeek-V2的价格降到了每百万token输入1元、输出2元(32K上下文);
5月11日智谱AI调将旗下入门级大模型GLM-3-Turbo(上下文长度128k)的价格,从0.005元/千tokens降低到0.001元/千tokens,而GLM-3 Turbo Batch批处理API便宜50%,达到1元200万tokens。
不过,这是否意味着,普通人更有机会低成本乃至零成本的使用大模型了呢?
答案恐怕是否定的。
如今大模型主要存在两种商业收费模式:
第一种是让C端用户付费,即ChatGPT Plus 20美元/月这种会员订阅模式。
第二种是让B端用户付费,即开发者API调用服务,让开发者接上大模型的“水龙头”,用上里面的“水”。
这次降价的正是第二种。
相较而言,B端市场比C端规模小得多,因此看起来声势浩大的价格战,于企业方而言,成本压力不算太大。
于普通人而言,人人都能低成本用AI的好时候,也尚未来临。
与此同时,进一步的争议也随之而来:当国外公司却想办法努力奔跑保持技术领先,来奔向星辰大海时,国内公司却都在商业化、卷市场份额?
比如黄仁勋说,我们公司从不谈论市场份额,这意味着大家在做同样的事;马斯克说,我不关注技术壁垒,我只关注创新的速度;奥特曼说,AI发展就像龙卷风,OpenAI要突破极限。
以上的话越看越鼓舞人心,但放到现实的环境中,当行业的领导者居于技术领先的位置,只能不停地保持领先,才能持续获得行业最多的资源。
这时的跟随者本就有多种方式追赶,充分的商业化可以为持续的跟随,提供资金耐力。
马拉松跑到终点前,追随者超越领跑者的案例并不少见。
当然这当中还有种种问题,我们也请到了专业的大头来解答。

这几天,大模型降价的降价,免费的免费。照这个样子发展下去,过两天会不会有倒贴的呢,到时候你会怎么选。
我的选择是,谁家送鸡蛋,我就选谁家。在发展到还没送鸡蛋之前,我从理性逻辑出发,讲三个观点:
◎ 首先,价格战带来了AI的全民普及。有人说,AI就像空气,未来我们无法离开它。而大模型价格战,恰如其分地扮演了“空气净化器”的角色。
百度、阿里等巨头纷纷降价,甚至免费,让普通人也能轻松接触到更好的新鲜空气、更好的AI工具。
其实降价的根本原因在于大模型推理的成本也在逐步降低,OpenAI在过去一年多的时间里降价幅度达到了惊人的90%。
只不过,OpenAI是一年时间内降了这么多,我们是一夜之间降了这么多,所以感觉冲击波更大。
国产大模型的内心OS:技术上我暂时还超不过你,降价速度我还超不过你了?

其次,价格战也带来了行业内耗与同质化隐忧。
大厂们打得火热,小厂们则可能面临“灭顶之灾”。
想象一下,小型AI公司在价格战中的境遇,就像是一只在大象脚下跳踢踏舞的老鼠,既要保持优雅,又要避免被踩城“鼠泥”。
价格战还可能会导致市场的资源错配和浪费,过度的价格竞争,会迫使厂商削减成本,从而在研发和创新方面投入不足。
这不仅不利于整个行业的长期发展,还可能导致市场集中度过高,形成寡头垄断,进一步抑制市场的活力和创新动力。
◎ 最后,要打赢价格战,就必须坚持创新、提供差异化的服务。
价格战只是百模大战的第一回合,真正的“终极对决”,在于技术和服务的创新。
就像美食界的竞争一样,打折的面条,可能暂时俘获消费者的胃,但真正让人念念不忘的,还是那碗独具风味的"秘制牛肉面“。
在大模型领域也是如此,价格战之后,谁能做出那碗”秘制牛肉面“,谁就能在未来的竞争中脱颖而出。

大模型的价格战,并不可怕。价格战的出现,有两大原因。
第一个原因就是科技大厂的算力都有富余。
中美摩擦升级的时候,中国科技大厂都怕断供,就疯狂地囤积英伟达的芯片,把算力资源迅速堆了上去。
后来华为的昇腾系列芯片做起来了,大厂们又进行了大量的采购。从百度和阿里的财报可以看出,这方面的开支非常庞大,高达几十亿元。
不过,AI应用的推广速度并没有他们想象的那么快,导致算力处于空转状态,前期砸的资源被浪费。
现在大厂都在想办法摊薄成本,让算力滚起来。
值得注意的是,二手市场的英伟达芯片,现在不好卖了。
想卖给政府,政府不会要,他们只会用国产芯片。想卖给云平台,可云平台算力富余,没必要再买新芯片。
我接到好几拨美国来的电话,说能不能帮忙联系一下,他们手里边有英伟达的A100或者H100。
第二个原因是技术和服务进步。
实际上,ChatGPT跟阿里云、百度云完全不是一个概念。
ChatGPT做的不是公有云,没有考虑公有云的动态分布,也没有考虑企业应用场景,而是疯狂在大模型上堆加资源。
反观中国的云服务商,就要为企业用户考虑,让他们在自家平台上把人工智能和大模型用起来,所以中国大厂的服务会更好。
不论是阿里云,还是百度云,已经可以对原本的算力资源进行更大价值和更有效率的动态分配。
打个比方,原来100块卡可以服务150个用户,现在经过技术升级,100块卡能服务250—300个用户,无形之中就提升了算卡的利用效率。
算力资源的富余,应用技术的提升,两者叠加就有了打价格战的基础。
纵观历史,现在的大模型之战,跟互联网时代的千团大战、打车APP大战一样,都给补贴,都给低价,杀到最后,只剩两三家巨头。
预计明年上半年国产大模型就会决出胜负,公有云市场也会发生变化。
谁在这上面占优势,谁就可能把公有云业务也拿下来。这也是阿里云率先降价的重要原因,它想守住优势地位。

国产大模型突然发起价格战,主要有三个原因。
一是国内厂商之间以价格战来圈用户;
二是国外实力更强的中低阶竞品已经免费,国内厂商以前的资费标准就作废了;
三是长文本应用和多模态需要更多Token,如果资费还维持不变,用户的使用成本就会高得离谱,厂商就会成为平台孤岛。
价格战肯定不是好事,尽管价格往下走是必然。免费不是重点,模型的原理迭代、水准提升、多模态进化才是关键。
免费积累起来的海量用户,有可能因为模型智能水准被甩在身后而一夜流失。
现在,价格战成了国内厂商的传播亮点。这是不对的,大家应该关心的是,在模型原理迭代、水准提升和多模态等方面的创新突破。
不同体量的公司,突破方向不一样。资金浅的创业公司应该聚焦应用,模型的微调或RAG或场景化专业模型。
但是有实力的厂商一定要敢于做底层突破。不好好做作业,将来想抄作业都抄不明白,抄错更是大概率。
照抄作业不行,照搬经验也不行。想把互联网思维带到超级智能这一波,恐怕是对AI的价值源泉和发展范式有误解,结果无异于自嗨。
中国互联网没能及时走向下一个时代,背后就是这种应用、流量、快钱思维在起作用。
人工智能时代,科技成为价值原力,面向AGI、EI、II的竞赛,流量只是依附于科技之上。
网红意义上的流量,不会给AI产品带来用户忠诚度,尤其是通用生成式大模型,水准略差用户就会瞬间流失。
没有底层技术驱动的核心能力的持续进化,以应用场景去打造所谓强智能无异于空中楼阁。
最后我想说,AI必须普惠每个人,AI必须以人为本。
科技要有价值观,科技越来越强大的今天和未来,科技及其业者应该始终想着帮助人、服务人,造福人类,而不是支配人,更不是控制人、驱逐人、挤压人。

随着国外大模型降价和开源数量越来越多,中国大模型厂商宣布降价或免费,其原因主要是想要扩大用户量。
大模型付费用户规模有限,难以训练出有用的AI,降价可以吸引更多用户参与,提高数据规模,促进模型完善,同时也有助于扩大市场份额。
价格战可以看作是市场竞争的一种策略。
一方面,它有助于消费者获得更低成本的产品或服务,推动技术普及和创新。
但另一方面,过度的价格战可能会导致利润压缩,影响行业的健康发展,甚至可能引发恶性竞争。
大模型的付费用户本来就不多,降价也不会给自己带来不利影响。
面对大厂的价格战,创业公司也要做好烧钱的准备,尽快形成自己的竞争优势。
创业公司要专注细分市场、提供差异化服务、加强技术创新或提高运营效率,还可以寻求合作伙伴或投资者的支持,以增强自身的竞争力。
除了免费策略之外,提升技术水平是最核心的策略。
此外,还可以采取以下措施来扩大用户基础:提供高质量的客户服务和技术支持;与行业领导者合作,开发行业解决方案;通过教育和培训提高公众对AI技术的接受度。
“让更多人用上AI”是一个应用层面的单向度的愿景目标。从理论上说,AI技术的普及将带来巨大的社会和经济效益。
但实际上,大模型的投入产出比,并不符合这种预期。我们适合从底层研发角度,提倡打败大模型的远景目标。
文章来源于“吴晓波频道”,作者“梅浩宇、饶祖分”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
