# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
GPT-4在为人类选股时,表现竟然超越了大部分人类分析师,和针对金融训练的专业模型?在没有任何上下文的情况下,它们直接就成功分析了财务报表,这一发现让许多业内大咖震惊了。然而好景不长,有AI大牛指出研究中的bug:之所以会这样,很可能是训练数据被污染了。
最近,各位业内大咖都被芝大的一篇论文震惊了。
研究者发现,由GPT-4帮忙选择的股票,直接击败了人类!同时也pk掉了许多其他针对金融训练的机器学习模型。
最让他们震惊的是,LLM可以在没有任何叙述上下文的情况下,就成功分析财务报表中的数字!

论文地址:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4835311
具体来说,在预测收益的变化上,LLM比经验丰富的金融分析师都更出色。尤其是在选股时,人类分析师会面临一些难以应对的场景,导致预测结果存在偏见、效率低下,这时LLM就表现出了巨大的优势。
并且,LLM做出的预测,不仅仅是回忆训练数据,比如GPT-4提供的有洞察力的分析,甚至能揭示一家公司未来潜在的表现。
GPT-4的表现一骑绝尘,直接比其他模型实现了更高的的夏普比率(Sharpe ratio)和阿尔法(alpha)。
沃顿商学院教授Ethan Mollick盛赞:这是一篇众人翘首以盼的论文。
也有网友感慨道:以后在股市中操盘的,是人还是AI都不好说了……
然而,就在大家激动之时,有细心的研究人员给这项研究泼了冷水:之所以能取得这个结果,很可能是由于训练数据的污染造成的。
AI大牛田渊栋也表示,GPT-4的优异表现,不排除是训练数据集中包括了未来的股票价格,因此GPT-4直接开了挂,据此对2021年起的股票样本进行了选择。
至于测试GPT-4是否开了挂,理论上并不复杂:只要获取股票的历史纪录,将其重命名为某个新代码,将其输入来测试就可以了。
怎样衡量LLM在未来决策中的作用?在这项研究中,研究者衡量的标准,就是让LLM进行财务报表分析(FSA)。
之所以进行FSA,主要是为了了解公司的财务健康状况,并确定其业绩是否可持续。
FSA并不简单,它是一个定量任务,需要大量分析趋势和比率,还涉及批判性思维、推理能力和复杂判断。通常,这个任务是由金融分析师和投资专业人士来完成的。
在研究中,研究者会将两份标准的财务报表——资产负债表和损益表扔给GPT-4 Turbo,它的任务是:分析公司接下来的收益是会增长还是下降。
注意,这项研究中有一个关键的设计,就是绝不向LLM提供任何文本信息,LLM能参考的,只有纯粹的报表。

研究者预测,LLM的表现,大概率会比专业的人类分析师差。
原因在于,分析财务报表这项任务,非常复杂,涉及许多模糊性的东西,需要很大常识、直觉和人类思维的灵活性。
而且,LLM目前的推理和判断能力还很不足,并且也缺乏对于行业和宏观经济的理解。
另外,研究者还预测LLM的表现也会弱于专用的机器学习应用,比如为收益预测的人工神经网络(ANN)。
因为,ANN允许模型学习深层次的交互,这些交互中包含了重要线索,通用模型是很难获取这些线索的。除非,通用模型能基于不完整的信息,或从未见过的情景,进行直觉推理、形成假设。
实验结果却令他们大吃一惊:LLM竟然pk掉了许多人类分析师和专用的神经网络,表现出了更优异的成绩!
评测LLM的具体表现如何,需要从以下两个步骤展开。
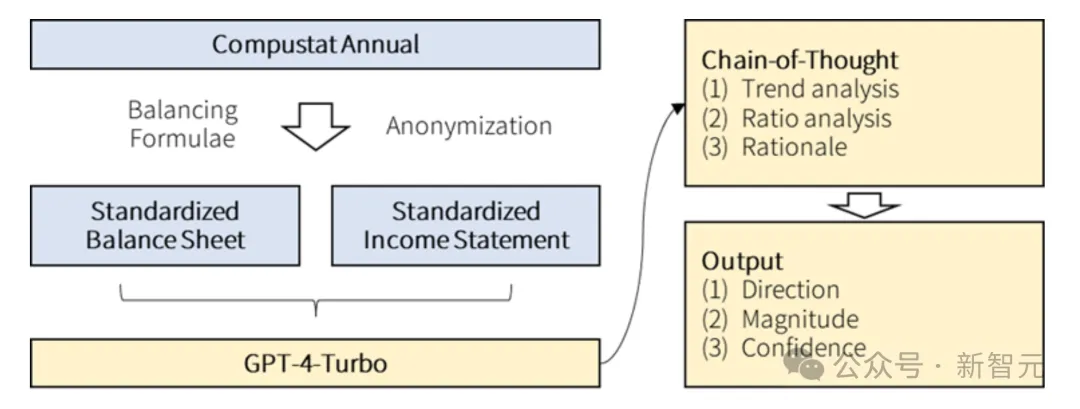
首先,研究人员对公司的财务报表进行匿名化和标准化处理,防止LLM记住公司的潜在可能。
特别是,他们从资产负债表和损益表中,省去了公司的名称,并用标签(如t和t-1)替换年份。
此外,研究者还按照Compustat的平衡模型,标准化资产负债表和损益表的格式。
这种方法,可以确保财务报表的格式,在所有公司年度统计中都是相同的,因此LLM也不知道其分析对应的是哪家公司或哪个时间段。
在第二阶段中,研究人员设计了一个指令,指导LLM进行财务报表分析,并确定未来收益方向。
除了简单的指令外,他们还开发了一个CoT指令,实际上是「教」LLM以人类金融分析师的思维过程进行分析。
具体来说,金融分析师在分析中会识别财务报表中显著的趋势,计算关键财务比率(如经营效率、流动性和杠杆比率),综合这些信息,并形成对未来收益的预期。
研究人员创建的CoT指令,便是通过一系列步骤,来实现这个思维过程。
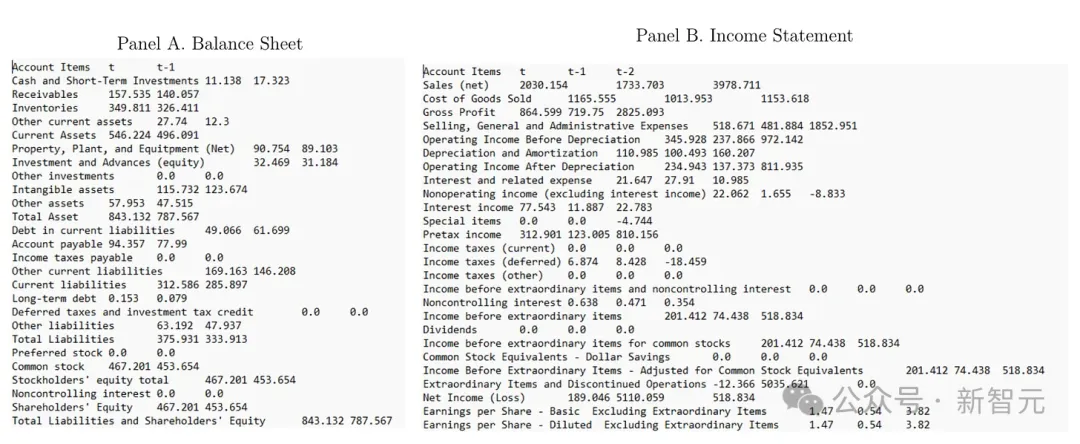
在数据集选用上,研究人员使用Compustat数据库来测试模型的表现,并在必要时与IBES数据库交叉使用。
样本涵盖了从1968-2021年之间,15401家公司的150678个公司的年度数据。
分析师的样本涵盖了1983-2021年期间,包含3152家公司的39533个观察数据。
对于这个结果,研究者提出了两种假设。
第一种假设是,GPT的表现完全是由近乎完美的记忆驱动的。
GPT很可能是从数据中推断出了公司的身份和年份,然后将这些信息与新闻中学到的关于该公司的情感相匹配。
为此,研究者试图排除这种可能。并且,也使用了GPT-4训练期以外的全新数据,复制了结果。
第二种假设是,GPT之所以能推断出未来收益的方向,是因为生成了有用的见解模型。
比如,模型经常会计算金融分析师计算的标注比率,然后根据CoT提示生成分析这些比率的叙述。

为此,研究者将模型为给定公司年度生成的所有叙述汇总,并使用BERT将它们编码成768维向量(嵌入),然后将这些向量输入到ANN中,并训练它预测未来收益的方向。
结果,基于GPT叙述见解训练的ANN达到了59%的准确率,这几乎与GPT的预测准确率(60%)一样高。
这一结果直接证明,模型生成的叙述见解对未来表现具有信息性。
另外可以观察到,GPT的预测与基于GPT叙述的ANN预测之间,有94%的相关性,这就表明,这些叙述编码的信息是GPT预测的基础。而在解释未来收益方向上,与比率分析相关的叙述最为重要。
总之,模型之所以表现优越,原因就是来自于基于CoT推理生成的叙述。
最新研究中的实验评估结果,可以总结为以下三大亮点。
为了评估分析师的预测准确性,研究者计算了「共识预测」(即财务报表发布后一个月内各个分析师预测的中位数),并将其作为下一年收益的预期。
这确保了分析师预测和模型预测结果的可比性。
此外,作者还使用了使用未来三个月和六个月的「共识预测」作为可替代的预期基准。
这些基准对LLM不利,因为它们整合了一年中所获得的信息。不过,考虑到分析师可能在将新信息纳入预测时较为迟缓,研究者选择报告这些基准以供比较。
研究人员首先对GPT在预测未来「收益方向」方面的表现进行了分析,并将其与证券分析师的表现进行了比较。
他们注意到预测每股收益(EPS)变化是一项高度复杂的任务,因为EPS时间序列近似于「Random Walk」(随机游走)并且包含大量不可预测的成分。
随机游走反映了,仅根据当前收益与之前收益相比的变化的预测。
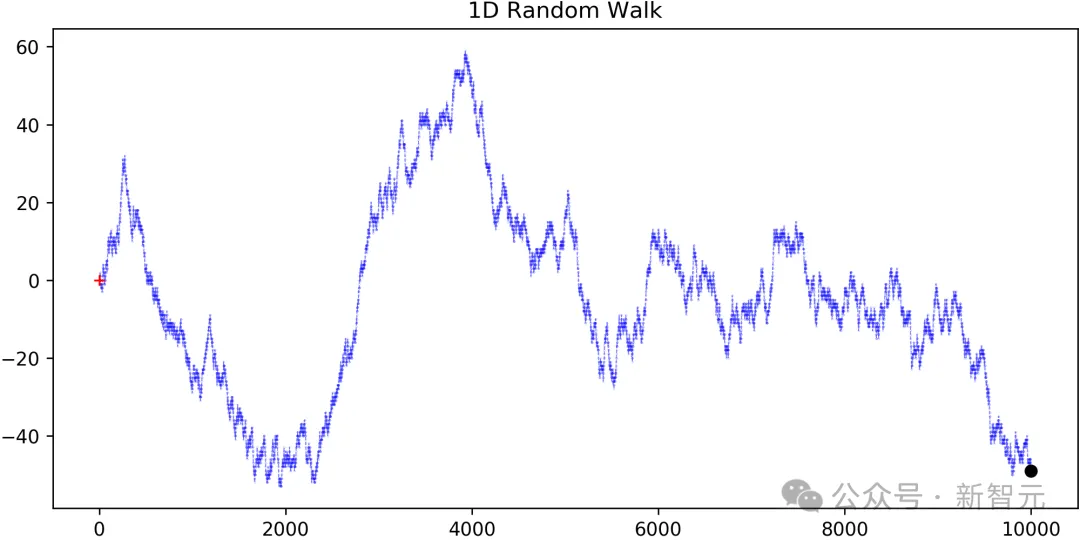
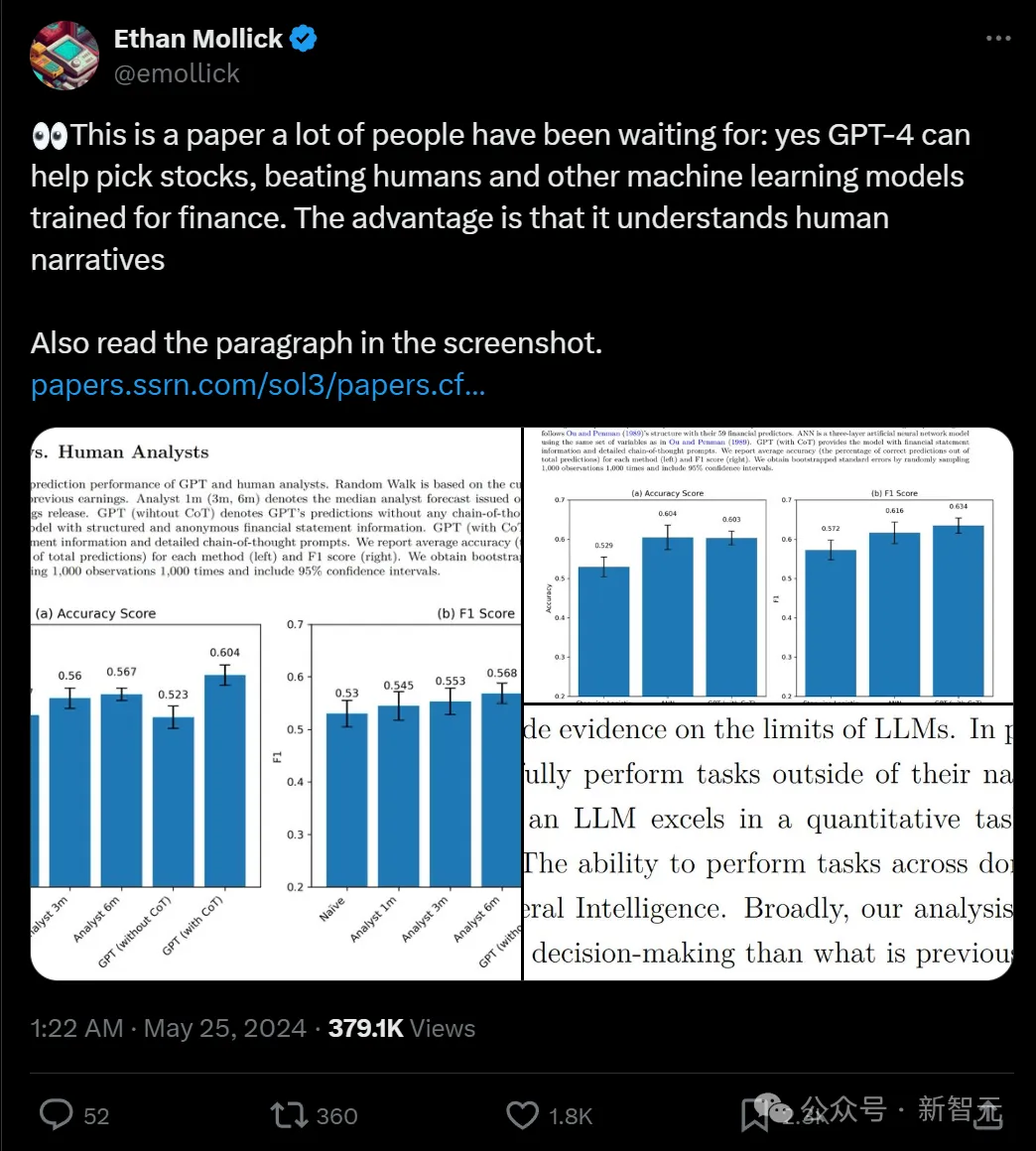
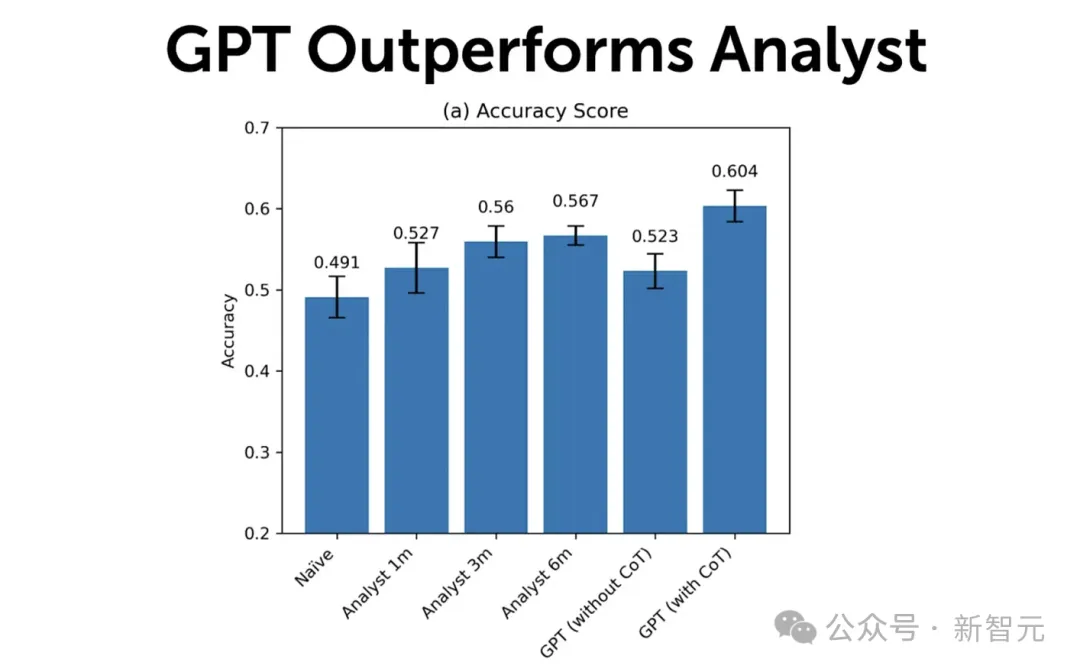
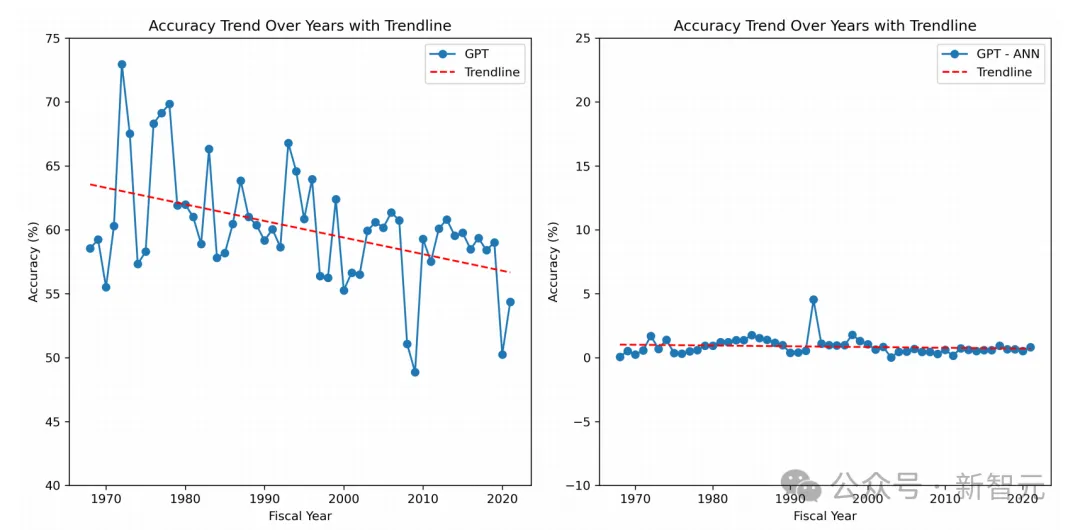
下图展示的是GPT和人类金融分析师的预测性能对比结果。
结果显示,第一个月分析师的预测,在预测未来收益方向方面的准确率为53%,这超过了简单模型(将前一年的变化外推)的49%准确率。
而分析师三个月和六个月后的预测准确率,分别为56%和57%,这是合理的,因其包含了更及时的信息。
基于「简单」非CoT提示的GPT预测表现为52%,低于人类分析师基准,这与研究者预期一致。
然而,当使用CoT模拟人类推理时,他们发现GPT的准确率达到了60%,显著高于分析师的表现。
如果再去核查F1-score(F1评分),这是一种评估模型预测能力的替代指标(基于其精确度和召回率的组合),也会得出类似的结论。
这表明,在分析财务报表以确定公司发展 方向方面, GPT明显击败了中位数金融分析师的表现。
坦白讲,人类分析师可能依赖于模型无法获得的软信息或更广泛的背景,从而增加了价值。
确实,研究人员还发现分析师的预测包含了GPT未捕捉到的,关于未来表现的有用见解。
此外,研究显示,当人类难以做出未来预测时,GPT的见解更有价值。
同样,在人类预测容易出现偏见或效率低(即未合理纳入信息)的情况下,GPT的预测在预测未来收益方向方面更有用。
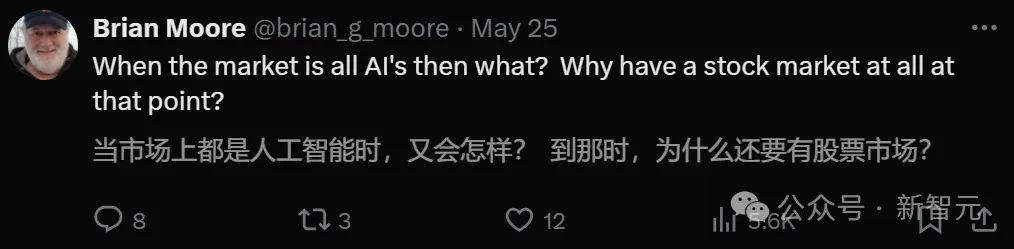
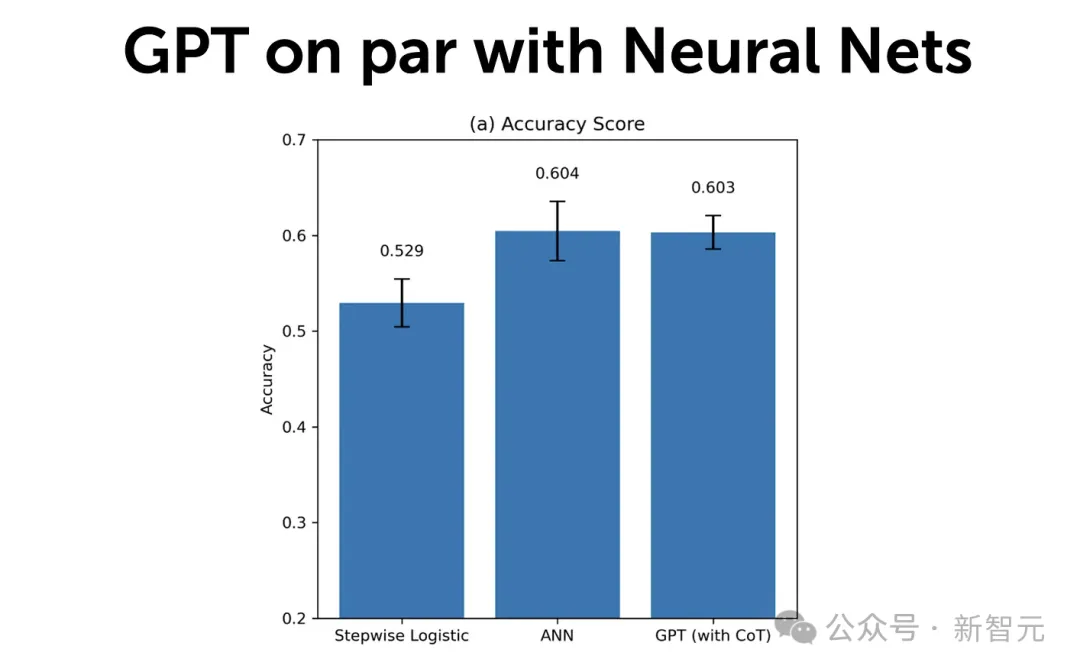
研究人员还比较了GPT和各种ML模型的预测精度。
他们选用了三种预测模型。
第一个模型「Stepwise Logistic」(逐步回归),遵循Ou and Penman框架,使用了59个财务指标预测变量。
第二个模型是,使用相同59个预测变量的ANN但也利用了它们之间的非线性和交互。
第三,为了确保GPT和ANN之间的一致性,研究人员还使用了,基于提供给GPT的相同信息集(损益表和资产负债表)训练的ANN模型。
重要的是,研究者基于每五年的历史数据使用 Compustat 的观察数据来训练这些模型。所有预测都是样本外的(out of sample)。
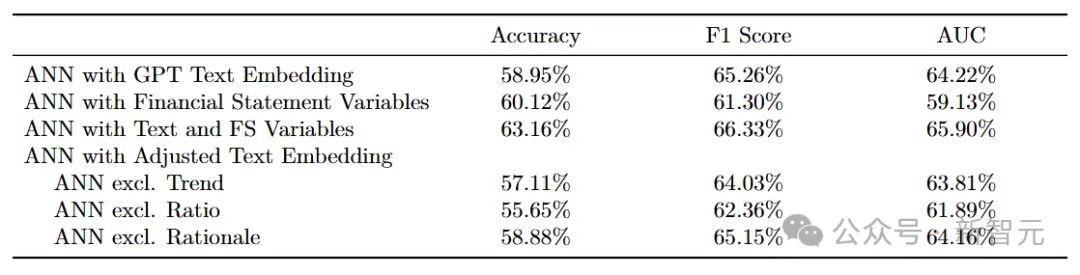
使用整个Compustat样本,研究发现「逐步回归」的准确率(F1评分)为52.94%(57.23%),这与人类分析师的表现相当,并且与之前的研究一致。
相比之下,使用相同数据训练的ANN达到了更高的准确率60.45%(F1评分61.62%),这处于最先进的收益预测模型的范围。
当使用GPT(with CoT)预测时,发现模型在整个样本上的准确率为60.31%,这与ANN的准确率非常接近。
事实上,GPT的F1评分显著高于ANN(63.45% vs. 61.6%)。
此外,当研究人员仅使用两份财务报表的数据(输入到GPT中)训练ANN时,发现ANN的预测能力略低,准确率(F1评分)为 59.02%(60.66%)。
总体而言,这些结果表明GPT的准确率与最先进的专用机器学习模型的准确率相当(甚至略高)。
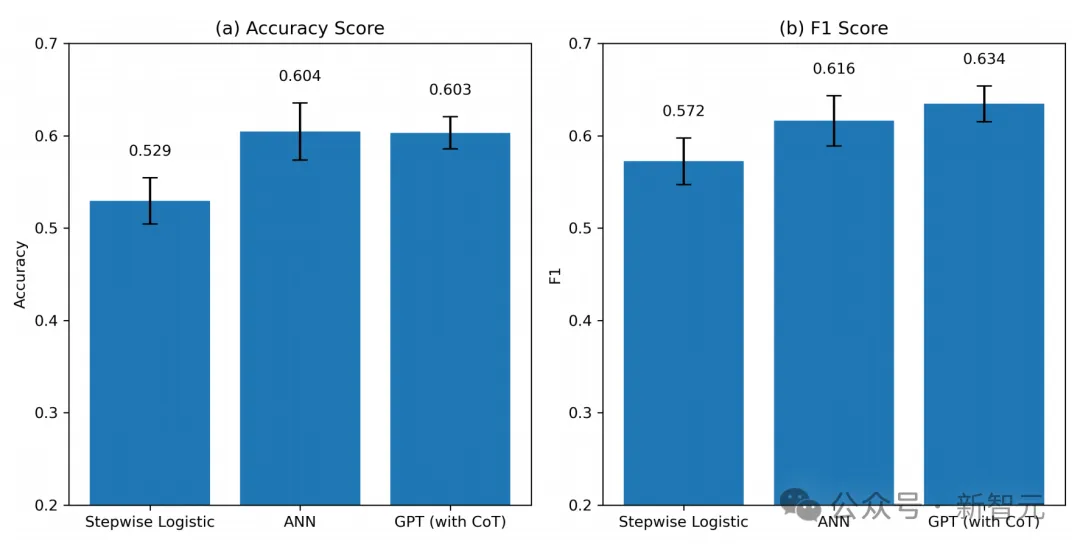
研究人员进一步观察到,ANN和GPT的预测具有互补性,因为它们都包含有用的增量信息。
并且有迹象表明,当ANN表现不佳时,GPT往往表现良好。
特别是,ANN基于其在过去数据中看到的训练示例来预测收益。并且,鉴于许多示例非常复杂且高度多维,其学习能力可能受到限制。
相比之下,GPT在预测小型或亏损公司的盈利时,犯的错误相对较少,可能得益于其类似人类的推理和广泛的知识。
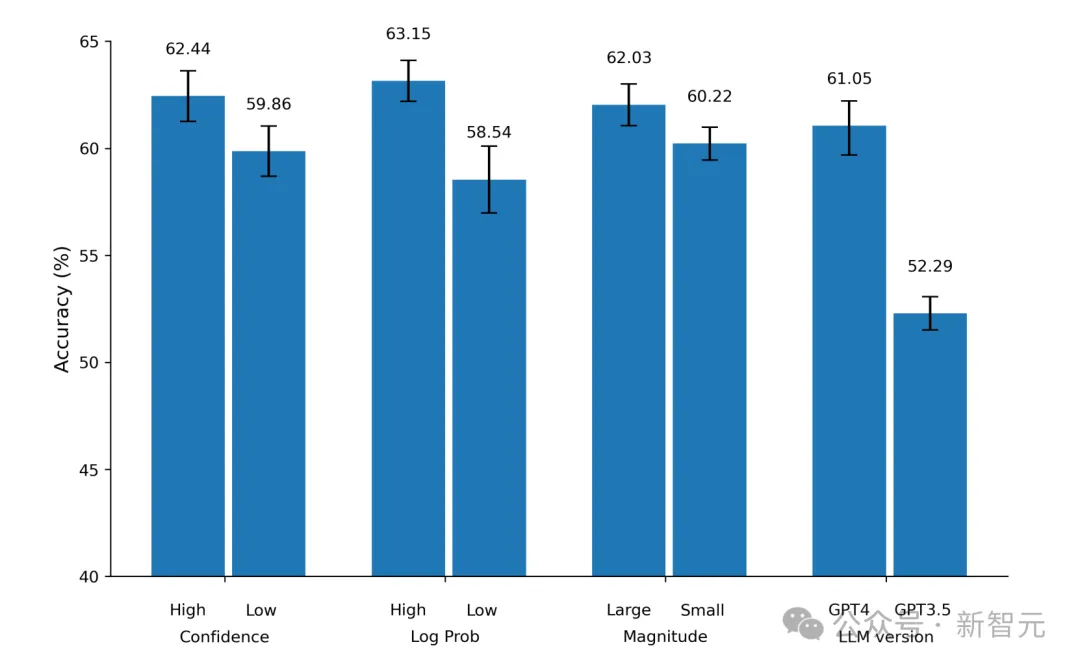
除此以外,研究者还进行了几项额外的实验,基于GPT对其答案的置信度对样本进行分区,并使用了不同的LLM家族。
当GPT以更高的置信度回答时,预测往往比置信度较低的预测更准确。
与此同时,研究证明了这一结果可以推广到其他大模型上。特别是,谷歌最近发布的Gemini Pro,其准确率与GPT-4 不相上下。
下图显示了,GPT响应中,双词(bigram)和单词(monogram)的频率统计。
这里,双词指的是由两个连续的单词组成,在文本中一起使用;单词指的是一个单词。
图左展现的是「双词」的结果,GPT关于财务比率分析的答案中发现的十个最常见的「双词」。
图右列出的是,GPT对二元盈利预测(binary earnings predictions)中,出现频率最高的十个单词。
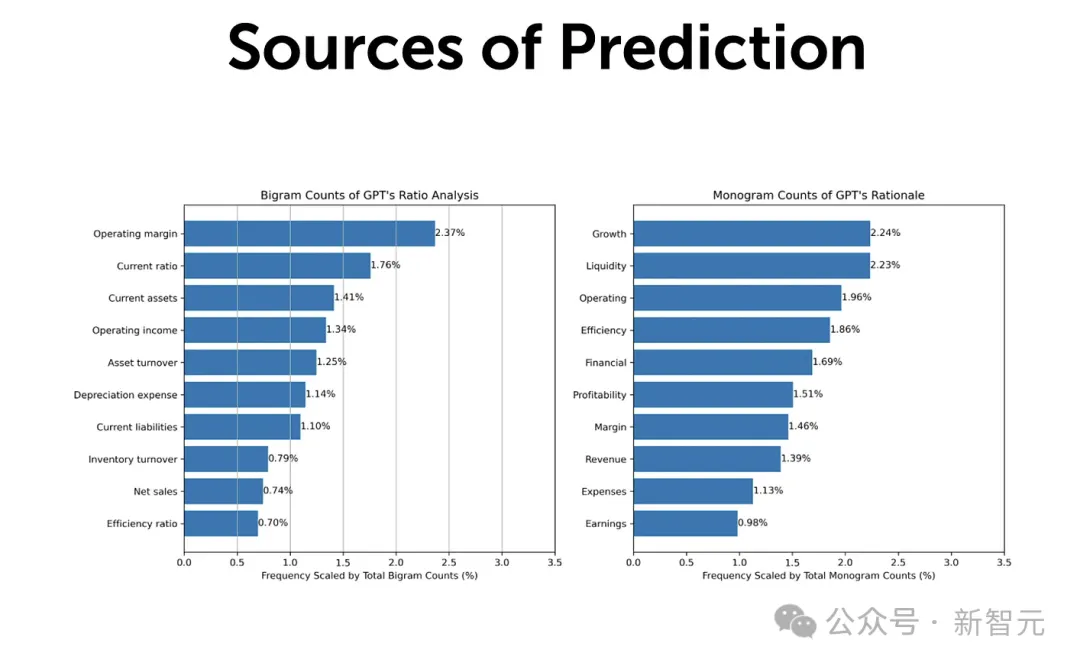
之所以做这项分析,是为了确定GPT在不同财务分析环境中,使用最常见的术语和短语。
有趣的是,「营业利润率」(Operating Margin)和「增长」(Growth)这两个词的预测力最高。
看来,GPT似乎已经内化了「40法则」。

总之,所有结果表明,AI加速发展,金融分析师的角色将会改变。
不可否认,人类专业知识和判断力不太可能在短期内被完全取代。
但像GPT-4这样强大的AI工具可能会极大地增强和简化分析师的工作,甚至可能在未来几年里,重塑财务报表分析这一领域。
参考资料:
https://www.newsletter.datadrivenvc.io/p/financial-statement-analysis-with
https://x.com/tydsh/status/1794137012532081112
https://x.com/emollick/status/1794056462349861273
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4835311
文章来自于微信公众号“新智元”,作者 “新智元”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
