# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在机器人学习方面,一种常用方法是收集针对特定机器人和任务的数据集,然后用其来训练策略。但是,如果使用这种方法来从头开始学习,每一个任务都需要收集足够数据,并且所得策略的泛化能力通常也不佳。
原理上讲,从其它机器人和任务收集的经验能提供可能的解决方案,能让模型看到多种多样的机器人控制问题,而这些问题也许能提升机器人在下游任务上的泛化能力和性能。但是,即便现在已经出现了能处理多种自然语言和计算机视觉任务的通用模型,构建「通用机器人模型」依然困难重重。
要为机器人训练一个统一的控制策略非常困难,其中涉及诸多难点,包括操作不同的机器人机体、传感器配置、动作空间、任务规范、环境和计算预算。
为了实现这一目标,已经出现了一些「机器人基础模型」相关研究成果;它们的做法是直接将机器人观察映射成动作,然后通过零样本或少样本方式泛化至新领域或新机器人。这些模型通常被称为「通才机器人策略(generalist robot policy)」,简称 GRP,这强调了机器人跨多种任务、环境和机器人系统执行低阶视觉运动控制的能力。
举些例子:GNM(General Navigation Model,通用导航模型) 适用于多种不同的机器人导航场景,RoboCat 可针对任务目标操作不同的机器人机体,RT-X 能通过语言操控五种不同的机器人机体。尽管这些模型确实是重要进展,但它们也存在多方面的局限:它们的输入观察通常是预定义的且通常很有限(比如单相机输入视频流);它们难以有效地微调至新领域;这些模型中最大型的版本都没有提供人们使用(这一点很重要)。
近日,加州大学伯克利分校、斯坦福大学、卡内基梅隆大学和谷歌 DeepMind 的 18 位研究者组成的 Octo Model Team 发布了他们的开创性研究成果:Octo 模型。该项目有效地克服了上述局限。

他们设计了一个系统,能让 GRP 更轻松地应对下游机器人应用的接口多样化问题。
该模型的核心是 Transformer 架构,其可将任意输入 token(根据观察和任务创建)映射成输出 token(然后编码成动作),而且该架构可使用多样化的机器人和任务数据集进行训练。该策略无需额外训练就能接受不同的相机配置,也能控制不同的机器人,还能通过语言命令或目标图像进行引导 —— 所有这些只需通过改变输入模型的 token 即可实现。
最重要的是,该模型还能适应传感器输入、动作空间或机器人形态不同的新机器人配置,所需的只是采用适当的适配器(adapter)并使用一个小的目标领域数据集和少量计算预算进行微调。
不仅如此,Octo 还已经在迄今为止最大的机器人操控数据集上完成了预训练 —— 该数据集包含来自 Open X-Embodiment 数据集的 80 万个机器人演示。Octo 不仅是首个可有效微调至新观察和动作空间的 GRP,也是首个完全开源(训练工作流程、模型检查点和数据)的通才机器人操控策略。该团队也在论文中强调了其组合 Octo 各组件的独特创新性。
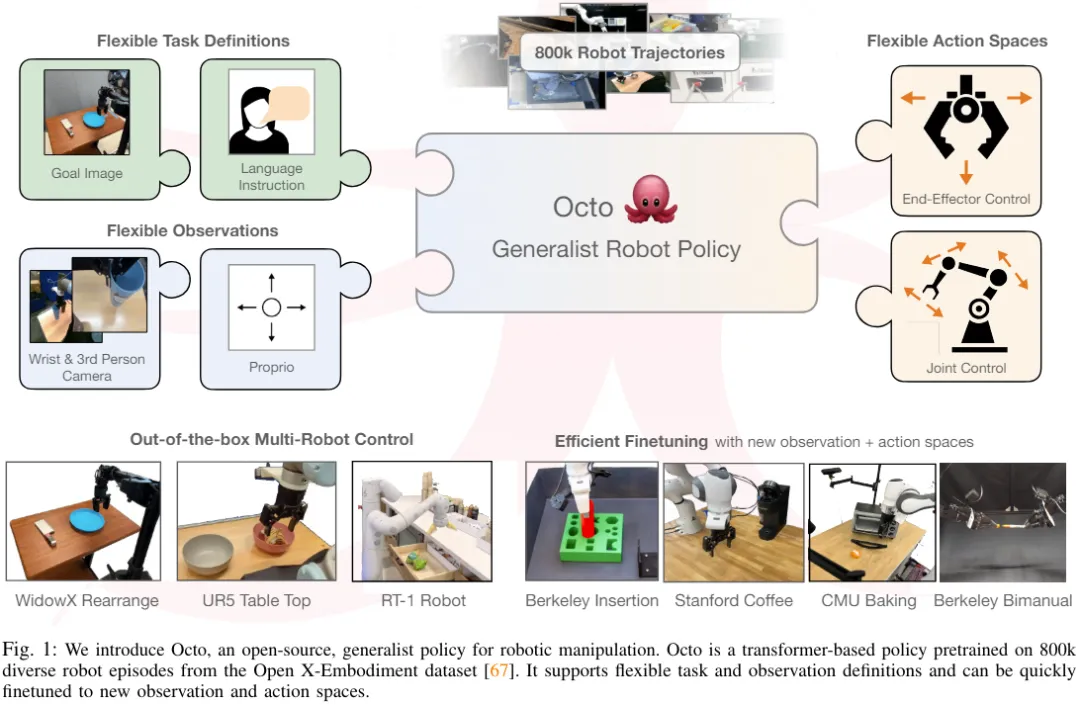
Octo 模型
下面我们来看看 Octo 这个开源的通才机器人策略是如何构建的。总体而言,Octo 的设计目标是让其成为一个灵活且广泛适用的通才机器人策略,可被大量不同的下游机器人应用和研究项目使用。
架构
Octo 的核心是基于 Transformer 的策略 π。其包含三个关键部分:输入 token 化器、Transformer 骨干网络和读出头。
如图 2 所示,其中输入 token 化器的作用是将语言指令、目标和观察序列转换成 token,Transformer 骨干会把这些 token 处理成嵌入,读出头则是得出所需的输出,即动作。
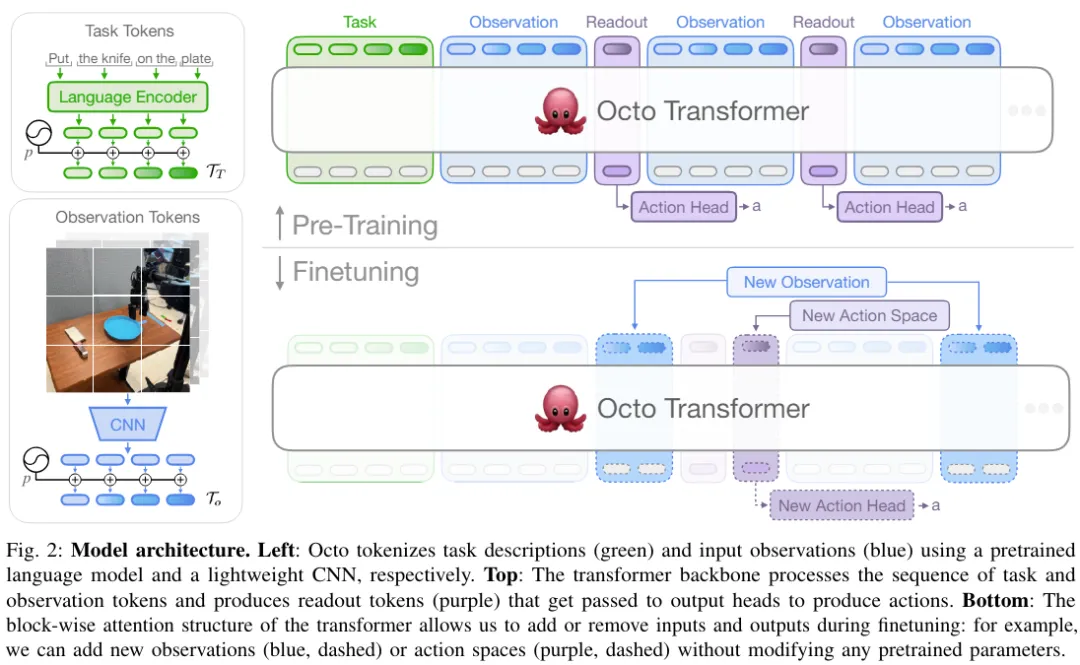
任务和观察 token 化器
为了将任务定义(比如语言指令和目标图像)与观察(比如相机视频流)转换成常用的已 token 化的格式,该团队针对不同模态使用了不同的 token 化器:
对于语言输入,先 token 化,然后通过一个预训练的 Transformer 将其处理成一个语言嵌入 token 序列。具体而言,他们使用的模型是 t5-base (111M)。
对于图像观察和目标,则是通过一个较浅的卷积堆栈来处理,然后再拆分成平展后图块构成的序列。
最后,通过向任务和观察 token 添加可学习的位置嵌入并按一定顺序排列它们来构建 Transformer 的输入序列。
Transformer 骨干和读出头
将输入处理成一种统一化的 token 序列之后,就能交给 Transformer 处理了。这与之前的研究工作类似:基于观察和动作系列来训练基于 Transformer 的策略。
Octo 的注意力模式是逐块掩码式:观察 token 只能按照因果关系关注来自同一或之前时间步骤的 token 以及任务 token。对应于不存在观察的 token 会被完全掩蔽掉(比如没有语言指令的数据集)。这种模块化设计很方便,可在微调阶段添加或移除观察或任务。
除了这些输入 token 模块,该团队还插入了已学习完成的读出 token。读出 token 会关注其之前的观察和任务 token,但不会被任何观察或任务 token 关注。因此,读出 token 只能读取和处理内部嵌入,而无法影响内部嵌入。读出 token 的作用类似于 BERT 中的 [CLS] token,充当截至目前的观察序列的紧凑向量嵌入。针对读出 token 的嵌入,会使用一个轻量的实现扩散过程的「动作头」。这个动作头会预测多个连续动作构成的一个「块(chunk)」。
这样的设计可让用户在下游微调时向模型灵活地添加新的任务和观察输入或动作输出头。当在下游添加新的任务、观察或损失函数时,可以在整体上保留 Transformer 的预训练权重,仅添加新的位置嵌入、一个新的轻量编码器、或由于规范变化而必需的新头的参数。这不同于之前的架构 —— 对于之前的架构,如果添加或移除图像输入或改变任务规范,就需要重新初始化或重新训练预训练模型的大量组件。
要让 Octo 成为真正的「通才」模型,这种灵活性至关重要:由于我们不可能在预训练阶段覆盖所有可能的机器人传感器和动作配置,因此,如果能在微调阶段调整 Octo 的输入和输出,便能让其成为机器人社区的一种多功能工具。另外,之前使用标准 Transformer 骨干或融合使用视觉编码器与 MLP 输出头的模型设计固定了模型输入的类型和顺序。相较之下,切换 Octo 的观察或任务并不需要对大部分模型进行重新初始化。
训练数据
该团队从 Open X-Embodiment 中取用了包含 25 个数据集的混合数据集。图 3 给出了数据集的组成。
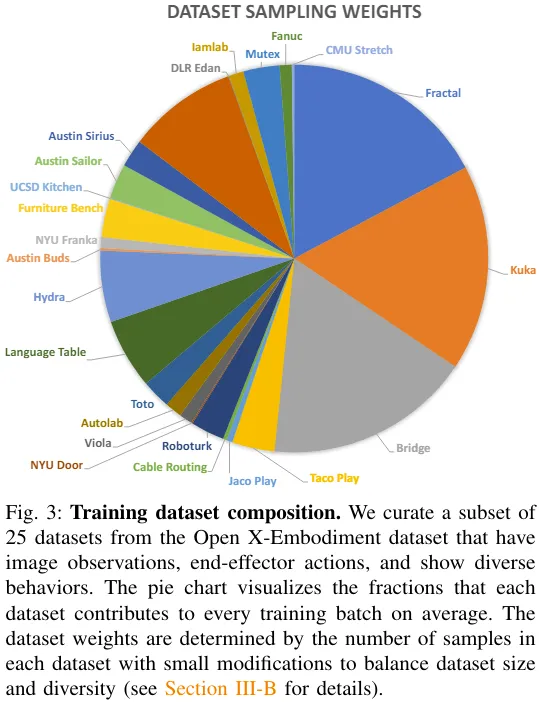
有关训练目标和训练硬件配置等更多细节请参阅原论文。
模型检查点和代码
重点来了!该团队不仅发了 Octo 的论文,还完全开源了所有资源,其中包括:
实验
该团队也通过实验对 Octo 进行了实证分析,在多个维度上评估了其作为机器人基础模型的性能:
图 4 展示了评估 Octo 的 9 种任务。

直接使用 Octo 控制多台机器人
该团队比较了 Octo、RT-1-X、RT-2-X 的零样本操控能力,结果见图 5。
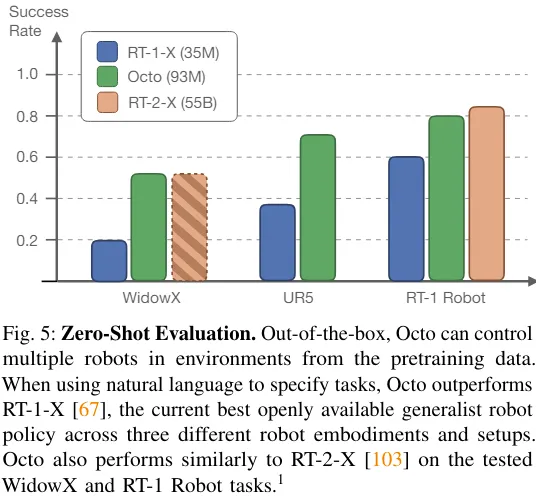
可以看到,Octo 的成功率比 RT-1-X(3500 万参数)高 29%。而在 WidowX 和 RT-1 Robot 评估上,Octo 与 550 亿参数的 RT-2-X 性能相当。
此外,RT-1-X 和 RT-2-X 仅支持语言指令,而 Octo 还支持以目标图像为条件。该团队还发现,在 WidowX 任务上,如果使用目标图像为条件,成功率比使用语言为条件高 25%。这可能是因为目标图像能提供更多有关任务完成的信息。
Octo 能高效地使用数据来适应新领域
表 1 给出了数据高效型微调的实验结果。

可以看到,相比于从头开始训练或使用预训练的 VC-1 权重进行预训练,微调 Octo 得到的结果更好。在 6 种评估设置上,Octo 相较于第二名基准的平均优势为 52%!
并且不得不提的是:针对所有这些评估任务,微调 Octo 时使用的配方和超参数全都一样,由此可见该团队找到了一个非常好的默认配置。
通才机器人策略训练的设计决策
上面的结果表明 Octo 确实能作为零样本多机器人控制器,也能作为策略微调的初始化基础。接下来,该团队分析了不同设计决策对 Octo 策略性能的影响。具体而言,他们关注的重点是以下方面:模型架构、训练数据、训练目标、模型规模。为此,他们进行了消融研究。
表 2 给出了在模型架构、训练数据和训练目标的消融研究结果。

图 6 则展现了模型规模对零样本成功率的影响,可以看出来更大的模型有更好的视觉场景感知能力。
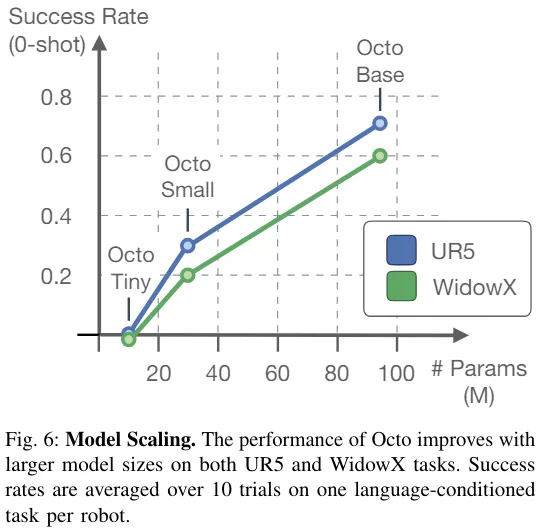
整体而言,Octo 各组件的有效性得到了证明。
文章来源于:微信公众号机器之心



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
