# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
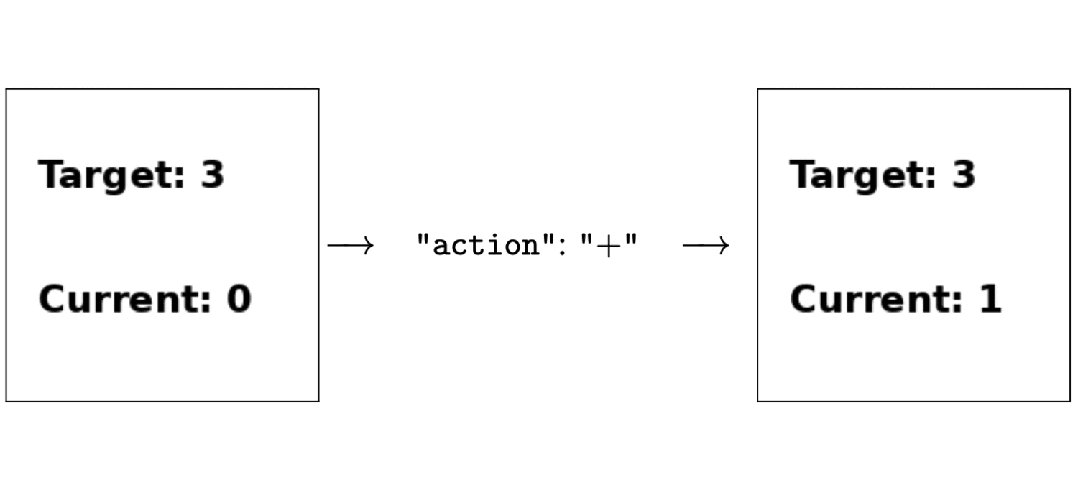
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!
这种方法得到的模型,已经学会了看图玩扑克、算“12点”等任务,表现甚至超越了GPT-4v。
这是来自UC伯克利等高校最新提出的微调方法,研究阵容也是相当豪华:

该方法名为RL4VLM,论文预印本已经上线,相关代码也已在GitHub中开源。
RL4VLM提出了一种新的算法框架,直接使用强化学习方法对多模态大模型进行微调。
其中奖励信息直接来源于环境当中,摆脱了RLHF中对于人类反馈的需要,从而直接赋予了多模态模型决策能力。

对于RL4VLM的意义,参与了这项工作的马毅教授这样说:
一方面希望大家对模型真实性能有更客观清醒的认识;
另一方面,也希望能建立一个平台,支持探索如何进一步提升模型性能。

那么,用这种方法微调出来的多模态大模型,都能让智能体学会哪些能力呢?
为了评估训练出的多模态大模型给智能体带来的能力,作者一共使用了两类物种评测任务:
具体来说,这五个任务分别是:
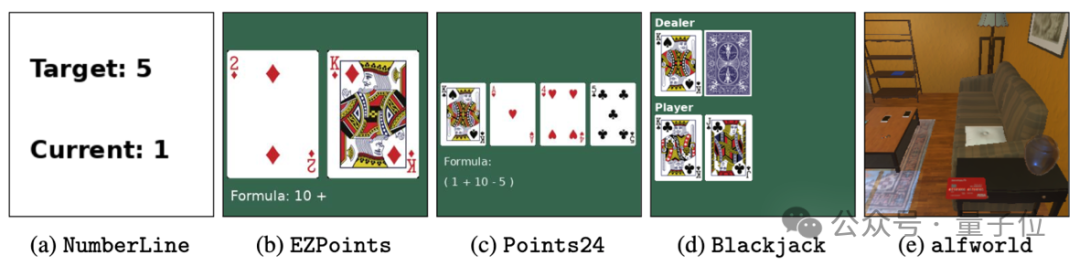
其中任务a-d为作者的原创任务,任务e的ALFWorld是微软等于2020年提出的开源具身智能任务集。
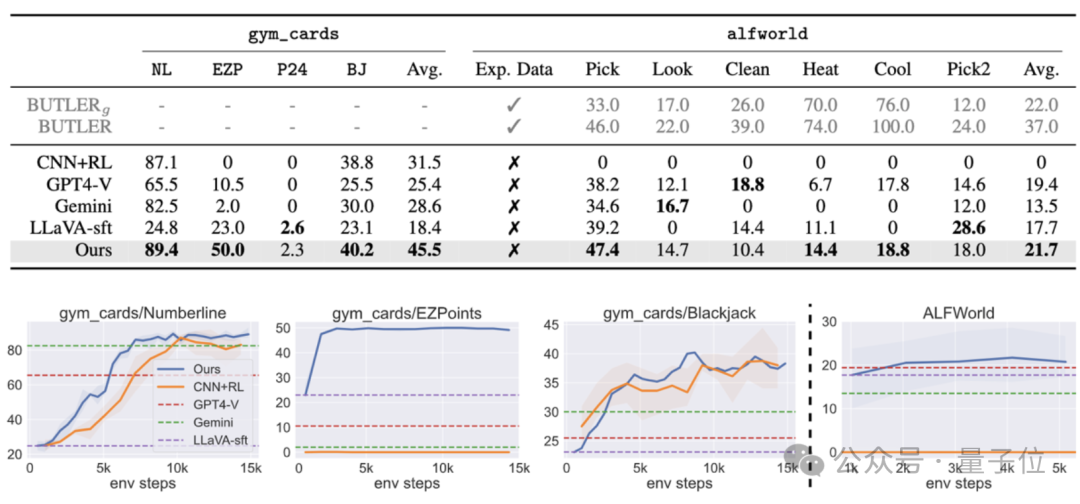
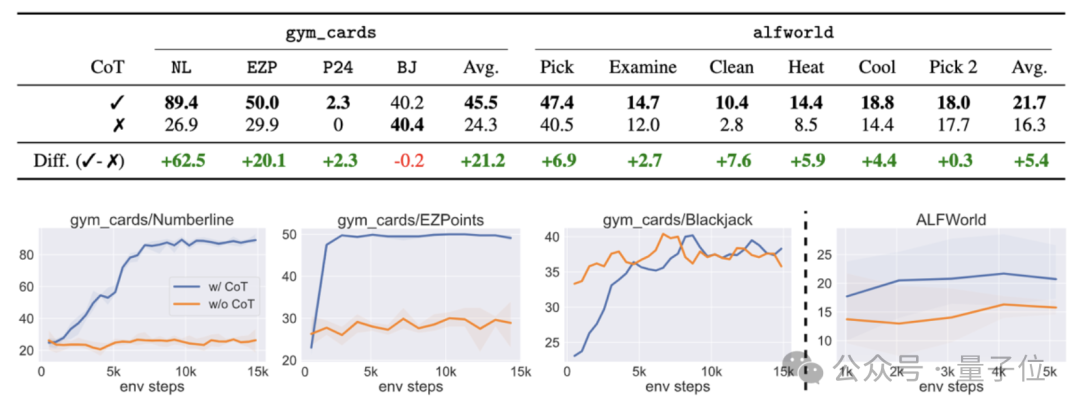
实验结果表明,直接使用强化学习微调7B的多模态模型之后,能使其在两类决策问题上的表现超过商用模型GPT-4v Gemini,同时也能超过传统的监督微调(SFT)方法。
而在ALFWorld的具身智能任务中,作者的模型也取得了最高的平均分,特别是在单物体拾取任务上表现尤为突出。
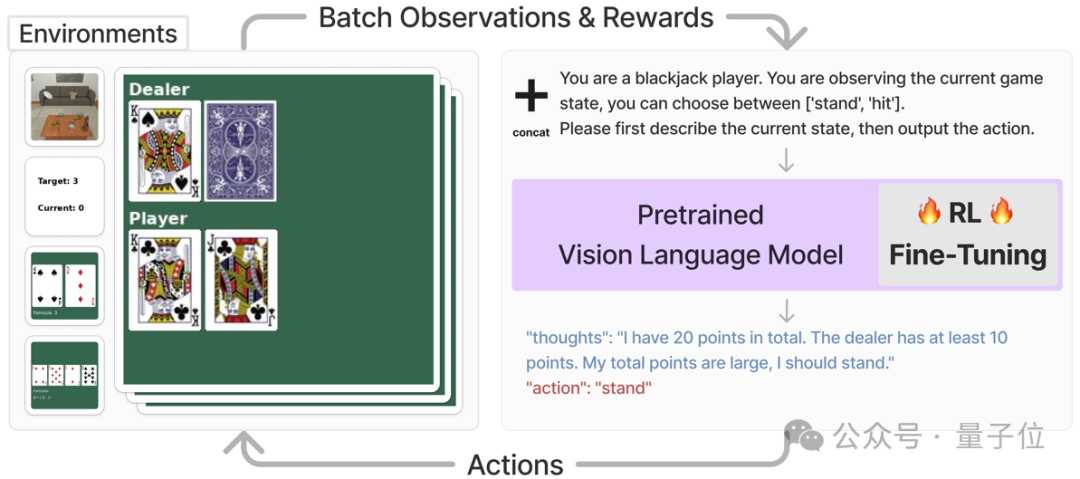
这套VLM智能体主要解决的是需要视觉识别和语言理解的任务,它的工作流程是这样的:
首先,对于每一个任务,系统会直接将该任务的当前状态,以图片和文字描述的形式输入多模态大模型,并要求模型输出一段思维链之后,再以文字形式输出要执行的动作。
最后将,动作信息会被输入进对应的环境并获得奖励值,该奖励值会被用来进行强化学习训练。
例如下图中,智能体在执行玩21点的任务时,系统直接要求多模态模型根据目前的状态,在输出思维链之后选择“停牌” (stand)或者“拿牌”(hit),然后直接将对应的动作输入到环境中,得到奖励函数值以及下一个状态。
为了能用直接将强化学习运用到多模态模型的训练中,需要对模型的输入和输出做一些调整,以适应RL训练框架中。
具体来说,作者将任务图像o和任务描述的文本v-in合并后,直接作为当前任务的状态s,即:
s = [o, v-in]
在获得了多模态模型的文字输出v-out以后,该框架直接将其中文字形式的动作(“action: {act}”) 转化为可与环境交互的动作指令a。
接下来把a输入到环境当中,就能获得奖励函数r,以及操作后的下一个状态。
在获得了来自环境的奖励函数r之后,文章利用PPO直接对整个多模态模型进行微调。
而从提示词上看,这项研究采取了如下的提示过程作为多模态模型的输入,并且给出了期望的输出形式:
(其中蓝色的部分是让模型生成思维链提示过程, 红色的部分是告诉模型以文字形式输出动作a)

消融实验结果表明,如果这一过程中不采用思维链,则任务成功率会出现大幅下降。
论文地址:
https://arxiv.org/abs/2405.10292
GitHub:
https://github.com/RL4VLM/RL4VLM
文章来源于“量子位”,作者“Simon Zhai”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
