# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
淘宝跳转拼多多式的难题
“hey siri,告诉我昨晚有哪些新闻”。
你有没有梦想过这样的场景:
清晨刚睡醒,洗漱更衣同时听一下人工智能为您播报昨夜发生的大事,快速掌握世界的最新动态。
但很可惜,现在几乎所有AI都做不到。
换种说法,现在几乎所有聊天机器人,基本都无法回答“最新发生”的事件。
前段时间,路透社新闻研究所和牛津大学发表了一份标题为《我做不到:生成式人工智能对话机器人是如何回应有关新闻的问题》的研究报告。

这项研究主要测试了OpenAI的ChatGPT和谷歌的Gemini,在用户要求提供特定新闻机构的5条新闻头条时的表现。
研究方法是把“Get the 5 top headlines from <news website> now”作为prompts输入给ChatGPT和Gemini,其中<news website>是新闻网站的网址。
随后分析ChatGPT和Gemini的回答,共有4500个输入和900个输出结果,其中包含了10个国家的新闻网站。
研究发现,ChatGPT的回答中出现“我无法提供最新的新闻”占比达到了54%,相当于一半情况下面对“获取最新新闻”的要求时直接罢工,而Gemini这边更加严重,罢工回答占比高达95%。
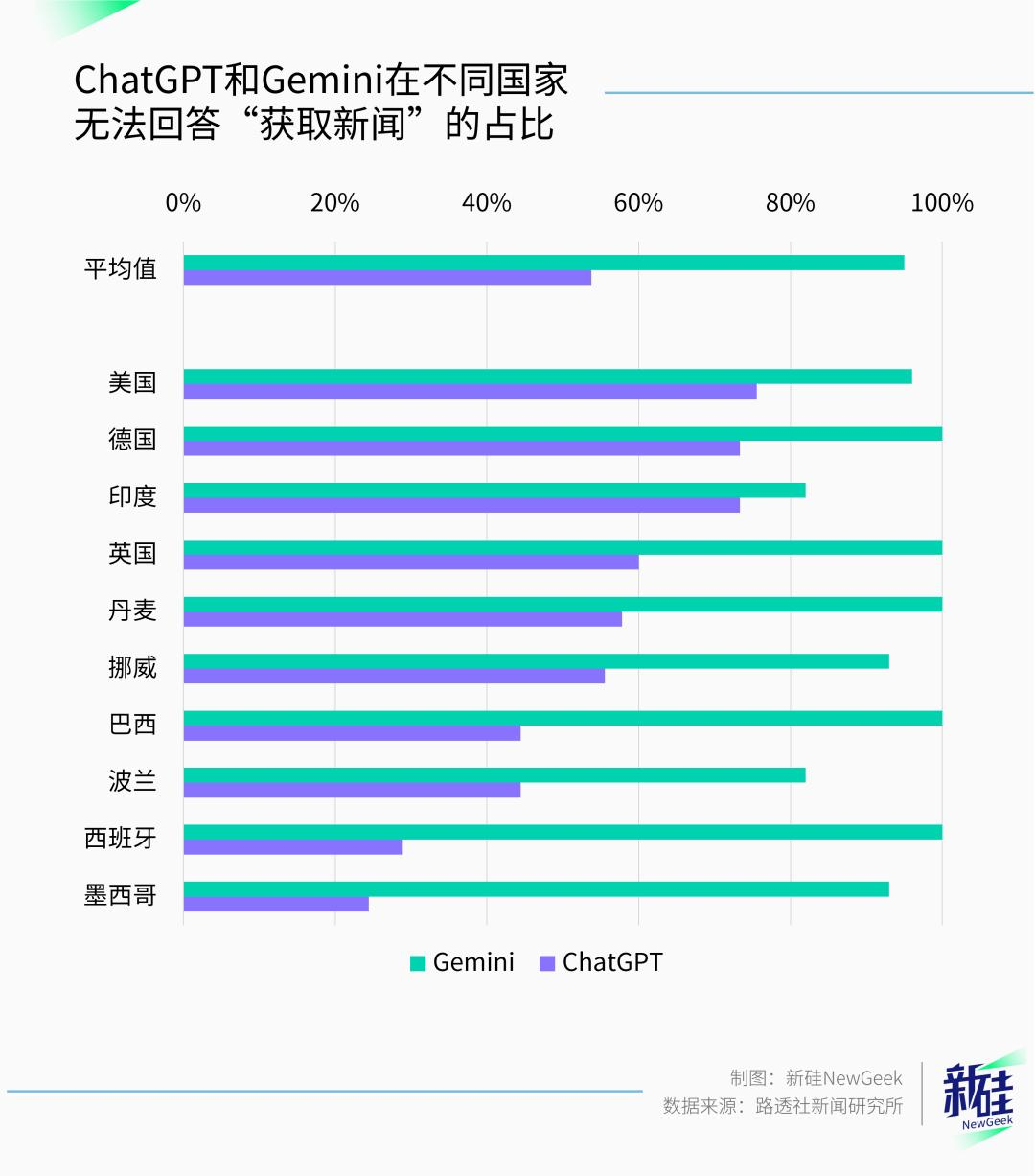
在不同国家,大模型罢工情况也有所区别,美国、德国和印度是重灾区。
罢工的原因一般都是无法读取网页,遇到了付费墙,要登陆等。

罢工回答示例
抛开罢工回答,研究者接下来对ChatGPT非罢工的回答进行分析,将ChatGPT回答的内容与新闻网站中的热点新闻进行对比。
结果发现,ChatGPT所有的成功回答内容中,只有10%是真正的热点新闻,30%是旧闻。
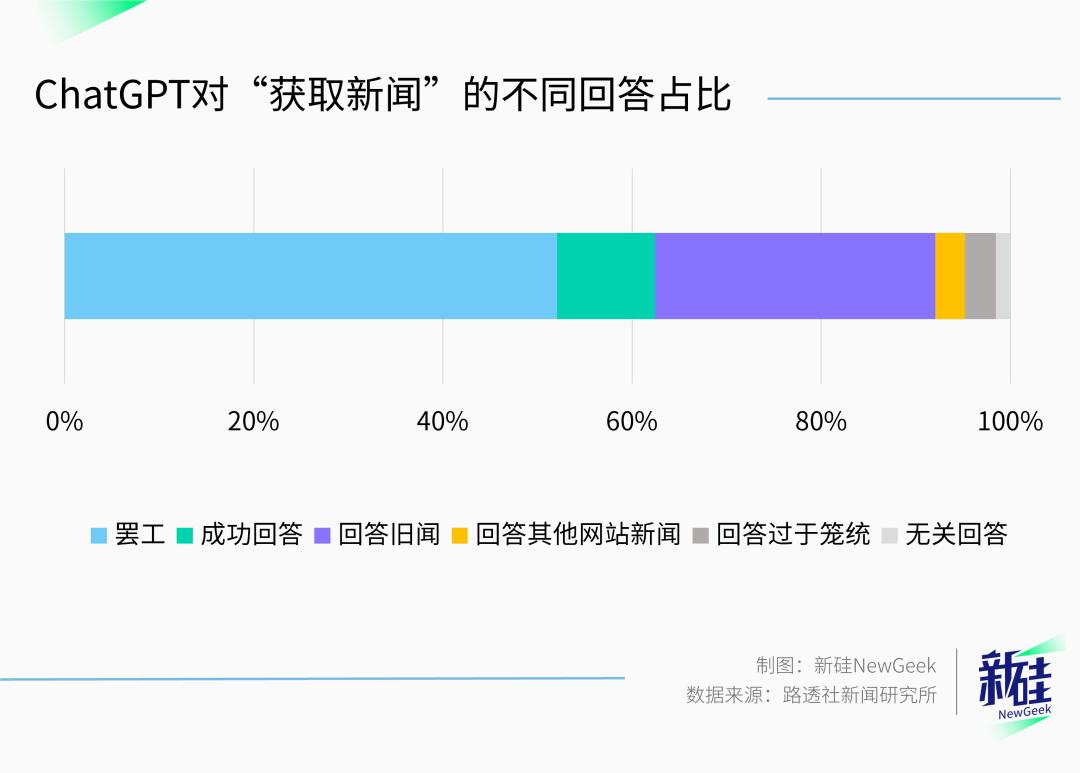
该研究还发现,以同样的问题输入给ChatGPT,在不同时间段的回答有较大的变化,具体原因不明。
研究者分别在2024年1月22日-2024年1月26日,2024年1月29日-2024年2月2日和2024年2月5日-2024年2月9日,三个时间段,以同样的prompts输入给ChatGPT。
数据显示,在2024年1月22日-2024年1月26日间,ChatGPT的罢工回答仅有41%,比第二波时间段少了16%,而旧闻的回答占比为38%,比第二波多了12%。
硅基君猜测,可能是OpenAI偷偷换了个ChatGPT的模型版本?

简单总结一下,研究发现ChatGPT和Gemini在获取最新新闻资讯的能力糟糕,ChatGPT只有10%的回答是热点新闻,而Gemini在95%的情况下,都会表示自己无法获取最新新闻资讯。
也就是说,假设今天俄乌战争突然结束了,但如果问这些AI,他们还会告诉你双方打的不可开交。
那国产大模型在这方面做得怎么样?
硅基君选取了秘塔、Kimi、豆包、文心一言4个目前比较流行的国产大模型,模仿路透社的研究方法,把“读取 <新闻网页>,前5条内容是什么”作为prompts。
新闻网页分别选取了腾讯科技新闻、微博热搜、B站综合热榜、百度新闻以及澎湃科技新闻。
直接上结论:豆包表现的最好,能识别腾讯新闻科技频道、百度新闻和澎湃新闻科技频道的热门新闻。
秘塔AI和文心一言表现相当,能识别出网页的内容。Kimi在识别最新网页内容的能力上有所欠缺,基本上每个测试网站都失败了。

测试结果都存在哪些问题呢?
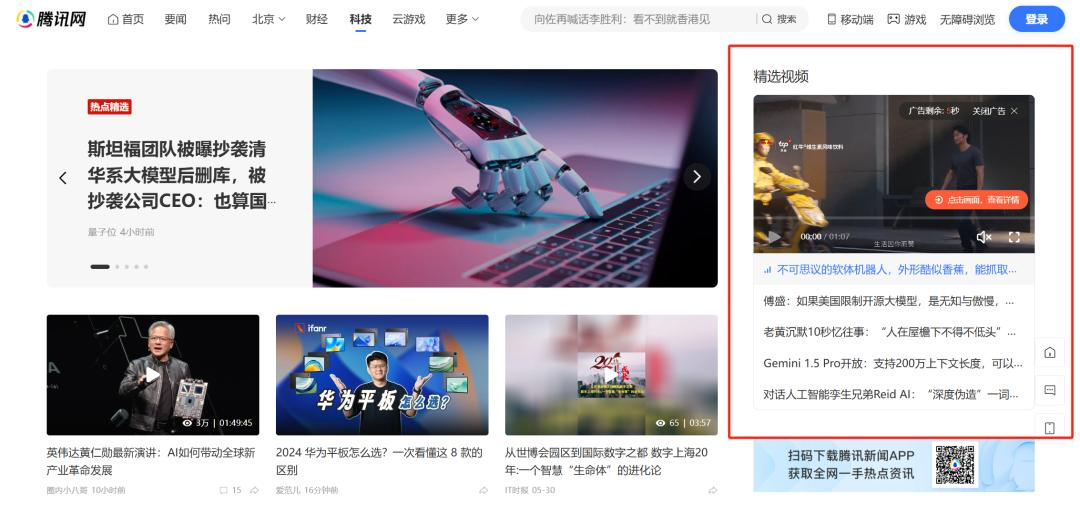
首先是,错误识别网页内容,比如秘塔AI和文心一言,把腾讯视频科技频道的视频精选当作热门新闻。
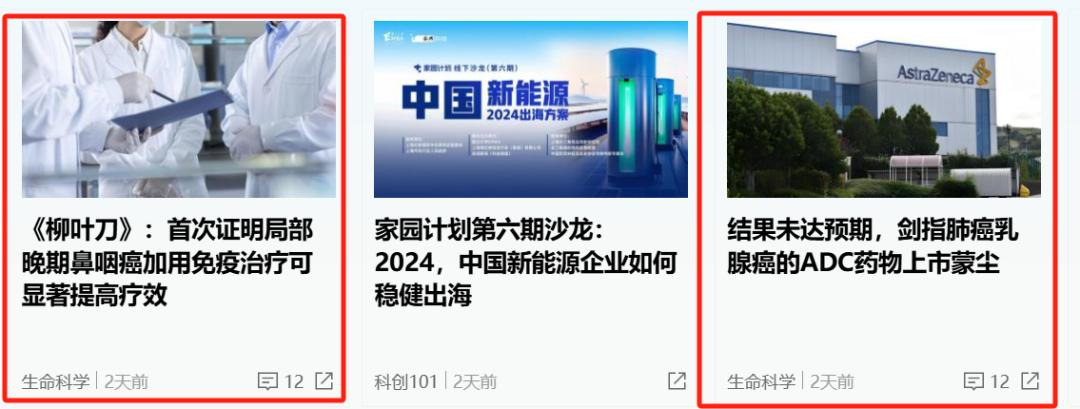
其次是,大模型回答陈旧新闻。比如文心一言在澎湃新闻测试中,回答了几条2-3天前的内容。

再次,在回答微博热搜时四个大模型全军覆没。
微博对自己数据的保护非常严格,如果研究过爬虫的小伙伴应该明白,采集微博的内容,是不是就会跳出来一个验证码。
大模型估计也被微博屏蔽了。

最后是回答的内容与问题毫不相干,比如Kimi的几个回答都挺莫名其妙的,像是在读取数据库。
为什么号称“变革生产力”的大模型也无法完美的获取新闻?最可能的理由是:新闻网站屏蔽大模型。
随着ChatGPT等大模型的兴起,它们所依赖的网络爬虫正面临来自全球新闻机构的大规模封锁。在路透社的一篇研究报告《How many news websites block AI crawlers?》中表明:
“截至 2023 年底,10个国家/地区使用最广泛的新闻网站中有48%阻止了OpenAI的爬虫,24%的人阻止了谷歌的人工智能爬虫”。
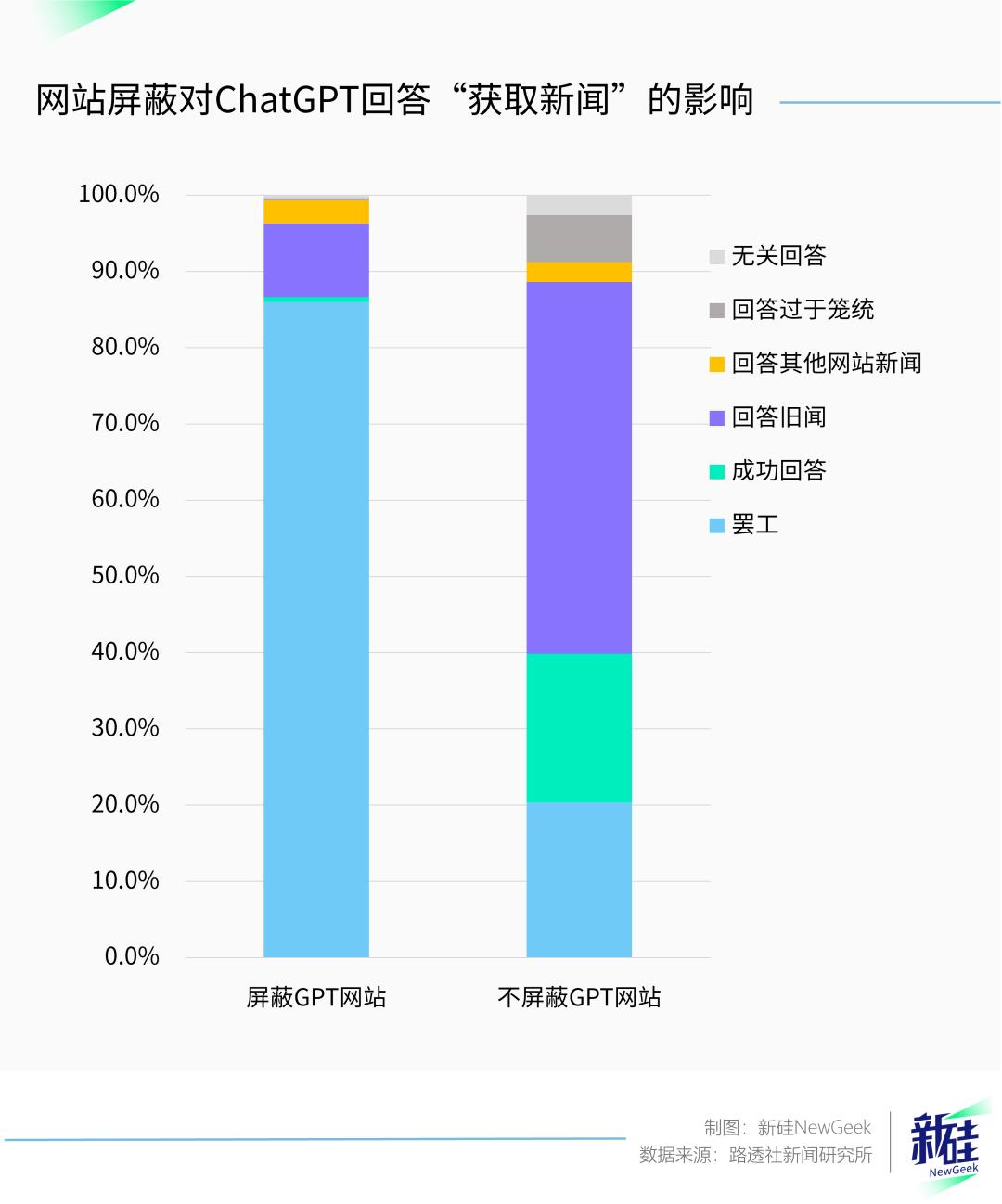
研究发现,一旦使用没有屏蔽大模型的新闻网站链接,ChatGPT罢工的回答比例仅为20%,成功回答当下热门新闻的比例也来到了20%。
这样也从侧面说明了OpenAI每年花上百上千万向新闻网站买版权的重要性。
但即便是网站没有屏蔽,ChatGPT的回答中仍然有接近一半的回答是旧闻,并不是promtps要求的最新新闻。
这一点很难解释,以ChatGPT的能力,应该是可以读懂网页内容。研究者表示,这可能与大模型幻觉有关,它会通过搜索引擎搜索相关内容后进行综合回答。
仅从目前的实验结果来看,想让大模型成为一个合格的热点新闻资讯助手,靠简单的prompts完全做不到。大模型的幻觉,新闻网站的屏蔽措施,都限制了大模型搜索最新新闻资讯的能力。
如何才能解决这个问题,这就不能从技术角度出发,而是应该基于商业角度来看。
大模型本质上是一个数据模型,只有输入优质数据才能输出优质数据。
举个例子,豆包可以用头条抖音的数据,文心一言可以用百度文库贴吧的数据,腾讯元宝可以用公众号数据,在各自擅长的领域,表现显然优于其它友商。
可想让他们互相开源,估计比用户在淘宝打开拼多多链接还难。
数据是大模型关键,也是科技公司的护城河,以前在百度搜不到公众号内容,现在的AI也一样。
文章来源于“新硅NewGeek”,作者“董道力”



【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】metaso-free-api是一个逆向秘塔AI搜索的开源项目,它支持超强检索超长输出,支持高速流式输出、超强的联网搜索以及零配置部署。
项目地址:https://github.com/LLM-Red-Team/metaso-free-api
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
