# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通过无透镜成像实现3D人体姿态和形状估计不仅有利于保护隐私,而且由于设备体积小、结构简单,可用于军事等隐秘监测场景。
然而,无透镜系统的成像结果经过了特殊的光学编码,目前的图像恢复方法无法得到高质量的图像,因此无法通过先恢复图像再重建人体的方式来实现。
针对以上问题,天津大学团队联合南京大学在CVPR 2024的工作中提出了端到端的无透镜成像下的人体三维重建框架LPSNet。

代码:https://github.com/xiaonan12138/LPSNet
项目主页:https://cic.tju.edu.cn/faculty/likun/projects/LPSNet
由于无透镜成像数据结果经过了特殊的光学编码,现有的方法无法直接从无透镜系统的成像结果中提取有效的特征。
为了直接从无透镜成像数据中提取有效的特征,作者设计了多尺度无透镜特征解码器。
除此之外,为了提高人体姿态估计的准确度,作者加入了双头辅助监督机制。
最后,作者通过实验验证了LPSNet可以通过无透镜成像系统完成3D人体姿态和形状估计。图一展示了部分实验结果。

图1 第一行:无透镜成像数据(右下角小图为对应场景的RGB图像,仅供参考),作为LPSNet的输入;第二行:通过LPSNet得到的3D人体姿态和形状,与对应场景图像的对齐结果展示;第三行:不同视角3D结果展示
方法动机
近年来,无透镜成像因其隐私保护强、体积小、结构简单、成本低等诸多优点,取得了显著进步。随着应用场景的多样化,人体姿态估计需要更加小型化和轻量化的成像设备。
无透镜成像系统正好可以满足这些优点,特别在隐私保护方面。在本文中,作者提出了LPSNet,其目的是通过无透镜成像系统采集的数据(lensless measurement)来估计3D人体姿态和形状,从而实现低成本且具有隐私保护属性的3D人体姿态与形状估计。
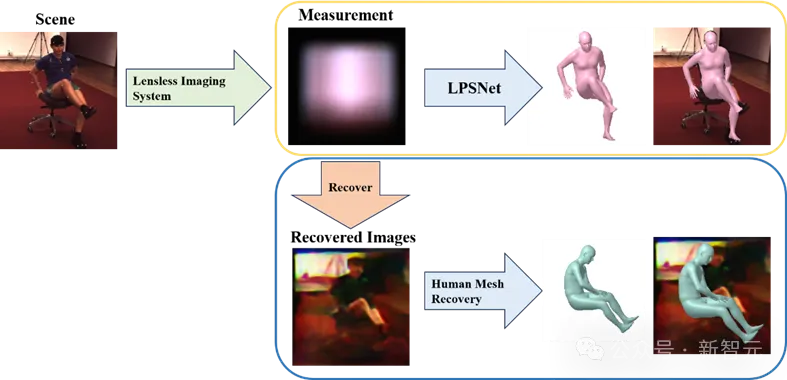
图2 无透镜人体姿态与形状估计方案
不同于传统相机,无透镜成像系统将传统相机中的镜头替换成一种轻薄且低成本的光学编码器。由于无透镜成像系统特殊的光学编码方法,可以从无透镜测量中获得更多有价值的信息。
现阶段,无透镜成像系统的应用十分广泛,主要应用于显微成像、RGB图像重建等领域。目前还没有方法可以直接通过无透镜成像系统估计3D人体姿态与形状。
一种直接的方法是通过两阶段的方式完成:如图2示,首先从无透镜成像数据中重建RGB图像,然后从RGB图像中估计人体三维姿态和形状。
然而图2实验结果表明,重建的RGB图像质量不理想,导致局部特征不完整,人体位置偏差明显。当使用无透镜成像数据来重建RGB图像时,结合这些因素会导致不准确的人体姿态估计。同时,使用这种方法需要消耗大量的计算资源,非常不适合在终端部署。
在这篇论文中,作者的目标是使用无透镜成像系统来完成端到端的3D人体姿态和形状估计,这需要克服两个主要挑战:
1. 如何有效的从无透镜成像数据中提取特征用于人体姿态和形状估计
2. 作者在初期进行的无透镜人体姿态估计尝试中发现,当从无透镜成像数据中提取特征估计3D人体姿态和形状时,人体四肢的估计精度很差。
为了解决这些挑战,作者提出了LPSNet,这是第一个基于无透镜成像系统的端到端的人体姿态和形状估计框架。
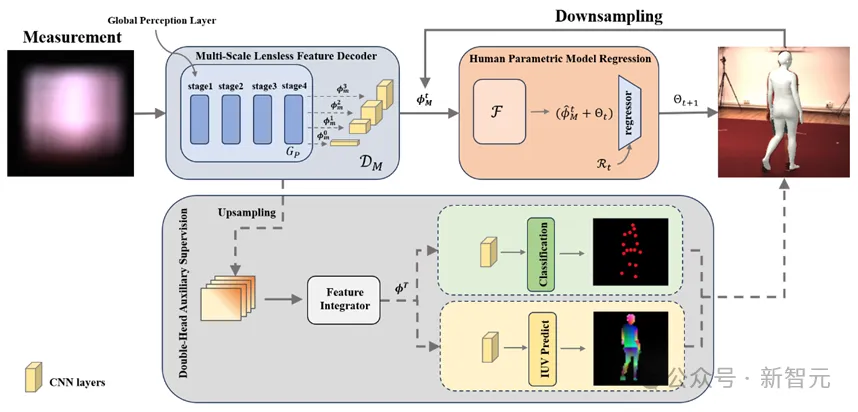
图3 LPSNet框架总览
方法思路
LPSNet框架总览
LPSNet工作的重点是通过无透镜成像数据来估计3D人体姿态和形状。LPSNet的基本框架如图3所示,该方法的核心包括以下三个部分:
1. 作者提出了一个多尺度无透镜特征解码器(MSFDecoder)它可以有效地解码由无透镜成像系统光学编码的信息;
2. 将MSFDecoder输出的多尺度特征送入人体参数化模型回归器中,通过回归器估计人姿态和形状参数;
3. 作者还提出了一个双头辅助监督机制(DHAS)可以帮助LPSNet提高人体肢体末端的估计精度。
多尺度无透镜特征解码器
现有的方法无法直接从无透镜成像数据中提取有效的特征,因此作者设计无透镜特征解码器的目标是从无透镜成像数据中有效的提取多尺度特征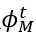 ,并用于后续3D人体姿态和形状的估计。
,并用于后续3D人体姿态和形状的估计。
在解码器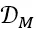 的内部作者加入了全局感知层
的内部作者加入了全局感知层 ,
,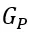 的设计灵感来源于HRNet[1]。
的设计灵感来源于HRNet[1]。
全局感知层的内部,不同分支之间的信息交互弥补了通道数量减少所造成的信息损失;全局感知层正是继承了HRNet[1]的许多优点,才能够始终保持较高的分辨率,这些优点对于从无透镜成像数据中提取特征非常重要。
人体参数化模型回归
作者在本文中使用的人体参数回归器借鉴了PyMAF[2]的设计。
PyMAF[2]中的人体参数回归器使用了通过反卷积得到的不同尺度特征,然而使用这种做法,会导致大量有效的信息在不断的上下采样过程中丢失,在LPSNet中,作者设计的全局感知层利用了HRNet[1]的结构特性维护了更多全局高分辨率特征。
双头辅助监督机制
从无透镜成像数据中提取的空间特征图比较粗糙,含有大量的噪声,对人体肢体末端的估计仍然存在一定的偏差。为了提高人体肢体末端估计的精度,作者引入了双头辅助监督机制。
具体来说,作者首先通过上采样将所有不同尺度的空间特征转换为相同的尺度,然后将它们连接在一起得到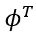 ,特征
,特征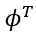 被用于不同的辅助监督头。
被用于不同的辅助监督头。
一方面,作者通过Classification层生成热图表示来体现二维关键点的位置;另一方面,作者还通过IUV Predict层估计密集映射。
双头辅助监督的损失函数由两部分组成,可表示为:
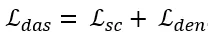
1. 关键点辅助监督
作者使用基于SimCC[3]的方法来预测姿态关键点。这种方法将关键点定位作为水平和垂直坐标的分类任务。在训练过程中,作者没有估计实际坐标,而是使用两个向量分表表示和的相关位置信息,同时2D关键点真值转换为同样的两个向量来计算损失。
损失函数的表达式为:
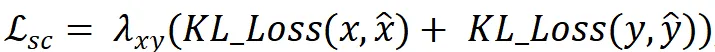
式中KL-Loss为Kullback-Leibler散度损失,和分别为处理后2D关键点真值。
2. IUV辅助监督
作者采用DensePose[5]中定义的IUV映射作为密集对应表示,这种映射在2D图像和3D表面的顶点之间建立了确定的对应关系。
模板网格上的顶点可以使用3D表面空间和2D UV空间之间的预定义双射映射将其映射回2D图像。密集对应表示包括身体部分P的索引和网格顶点的UV值。
实验数据集
LPSNet的输入是无透镜成像数据,因此经典的人体姿态估计数据集目前还无法直接使用。为了解决这一问题,作者搭建了一个无透镜成像系统用于采集实验数据,该成像系统还具备较为可靠数学模型,可以用于系统仿真。
作者的实验的数据集来源可分为以下两个方面:
1)真实数据集:使用无透镜成像系统采集显示在屏幕上的图像作为无透镜成像数据是目前在无透镜领域获取数据集的主要方法。作者使用这种方式收集人体姿态数据集,包括Human3.6M、MPII、COCO、3DPW和MIP-INF-3DHP数据集。除此之外作者还采集了真实场景的人体数据。
2) 仿真数据集:无透镜成像系统的成像过程可以通过数学模型表示。作者通过无透镜成像系统的数学模型将主流人体姿态数据集转换为无透镜成像系统采集的结果。
实验结果
由于该工作是第一个通过无透镜成像数据估计3D人体姿势和形状的工作,缺少对比的方法,因此作者设计了一个两阶段的baseline进行对比。
Baseline基本结构如图4所示,作者首先使用了Rego等人提出的无透镜图像重建方法[4]重建出RGB图像,然后使用PyMAF[2]方法从RGB图像中估计人体三维姿态与形状。此外,作者还使用了从无透镜数据重建的图像对PyMAF进行微调,记为PyMAF†。

图4 Baseline基本结构 (上部)重建图像与原图像对比(下部)
作者对比了LPSNet、baseline(PyMAF)和baseline(PyMAF†)方法的结果,如图5,图6所示。可以看到,LPSNet的结果相较于两种baseline有着较为明显的提升。表1为定量结果,LPSNet在MPJPE和PVE两个评价指标上优于两个baseline方法。

图5 不同方法的定性对比结果
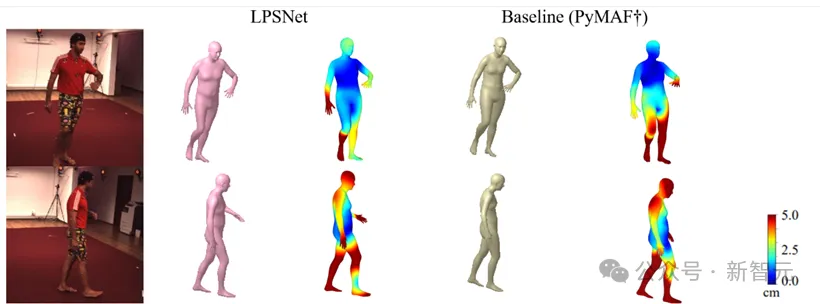
图6 不同方法的定性对比结果(注意:baseline(PyMAF)误差较大,这里不做误差分析)
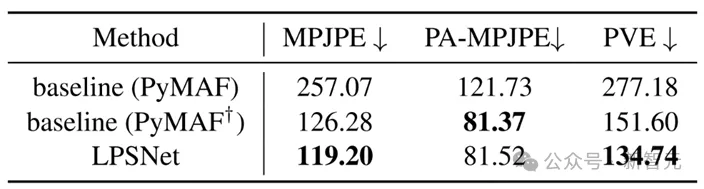
表1 不同方法的定量对比结果
除此之外,作者也提供了较为详细的消融实验。图7展示了定性结果,表2展示了定量结果。通过消融实验可以看出,使用了作者设计的无透镜特征解码器和双头辅助监督机制后,实验结果有明显提升。
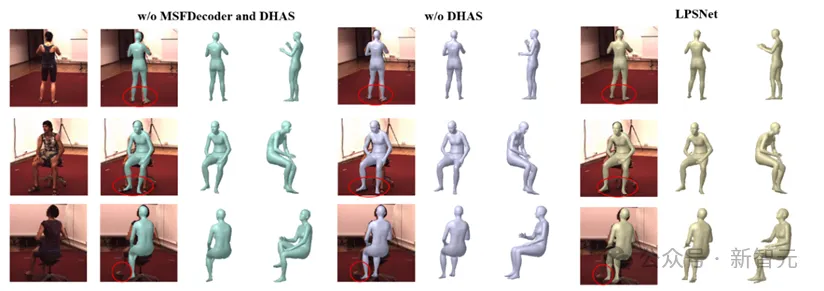
图7 LPSNet消融实验结果(定性)
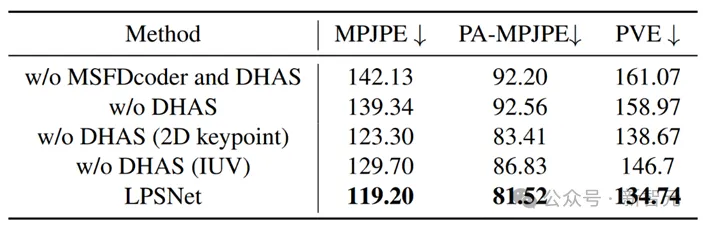
表2 LPSNet消融实验结果(定量)
该工作的demo视频如下:

作者简介
葛昊洋,天津大学22级硕士研究生,主要研究方向:三维视觉、无透镜成像。

冯桥,天津大学21级硕士研究生,主要研究方向:三维视觉、计算机图形学。

贾海龙,天津大学22级硕士研究生,主要研究方向:三维视觉、无透镜成像。

李雄政,天津大学19级博士研究生,主要研究方向:三维视觉、人体与衣物重建。

殷祥军,天津大学19级博士研究生,主要研究方向:无透镜成像、计算摄像学。

周游,南京大学助理教授,主要研究方向:计算光学与显微成像。

杨敬钰,天津大学教授、博导,主要研究方向:计算摄像学、多媒体处理。

李坤(通讯作者),天津大学教授、博导,主要研究方向:三维视觉、多媒体处理。

文章来源于“新智元”,作者“新智元”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
