# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。
但是,随着模型越来越大,RLHF 通常需要维持多个模型以及越来越复杂的学习流程,这又会导致内存和计算资源需求增长。举个例子,近端策略优化(PPO,这是 RLHF 常用的一种算法)需要在训练过程中维持四个模型。
由此,当语言模型的参数规模超过 700 亿时,为了训练和协调多个模型,所需的计算资源和调度复杂性会显著增长 —— 这是当前的架构设计难以满足的需求。
Transformer 强化学习(TRL)、ColossalChat(CAIChat)和 DeepSpeed-Chat(DSChat)等现有的开源 RLHF 框架是依靠零冗余优化器(Zero Redundancy Optimizer/ZeRO),来将 RLHF 训练涉及的四个模型配置到同一台 GPU 上。这个过程被称为 co-location,即空间并置。
但是,随着模型参数规模超过 700 亿,在内存有限的 GPU 上,这种调度方法的效率会越来越低。
为了解决空间并置的限制,TRL 等一些框架选择在内存使用上做出妥协,其做法包括将 actor 和 critic 模型融合起来或采用低秩适应(LoRA)等技术。但是,这些技术会降低模型性能,而且融合 actor-critic 式架构与备受推崇的实践做法不兼容,即使用奖励模型的权重来初始化 critic 模型的权重。
另一种替代方法是使用来自英伟达 Megatron 的张量并行化和管道并行化技术。但是,Megatron 与人们常用的 Hugging Face 软件库不兼容,而适应新模型又需要大量修改源代码,如此就很难使用了。
为了轻松实现大规模 RLHF 训练,OpenLLMAI、字节跳动、网易伏羲 AI Lab、阿里巴巴的一个联合团队提出并开源了 OpenRLHF,其中第一作者为 Jian Hu。该框架使用 Ray、vLLM 和 DeepSpeed 对模型调度进行了重新设计,可支持超 700 亿参数的模型的 RLHF 训练,其优势包括简单易用、高性能、实现了分布式 RLHF、集成了 PPO 实现技巧。

有关 Ray、vLLM 和 DeepSpeed 的具体详情,请访问原论文:
OpenRLHF 可与 Hugging Face Transformer 无缝整合,并且支持混合专家(MoE)、Jamba 和 QLoRA 等常用技术。此外,OpenRLHF 还实现了多个对齐算法,包括直接偏好优化(DPO)和 Kahneman-Tversky 优化(KTO)、条件 SFT 和拒绝采样。
因此,可以说 OpenRLHF 是一个非常全面的 RLHF 训练框架。
表 1 比较了常用的 RLHF 框架。

调度优化
要为更大的模型执行 RLHF 训练,需要高效地在多台 GPU 上分配至少四个组件模型(actor、critic、奖励、参考)。为什么需要多台 GPU?因为每台 GPU 加速器的内存有限,比如 NVIDIA A100 的内存不到 80GB。OpenRLHF 在模型调度方面创新性地使用了 Ray 来进行模型安放和细粒度的编排。
同时,OpenRLHF 还使用了针对推理优化的软件库 vLLM 和针对训练优化的软件库 DeepSpeed;它们都由基于 Ray 的调度器管理。
OpenRLHF 能将四个模型分配到多台 GPU 上,而不是将它们并置于同一台 GPU,如图 1 所示。
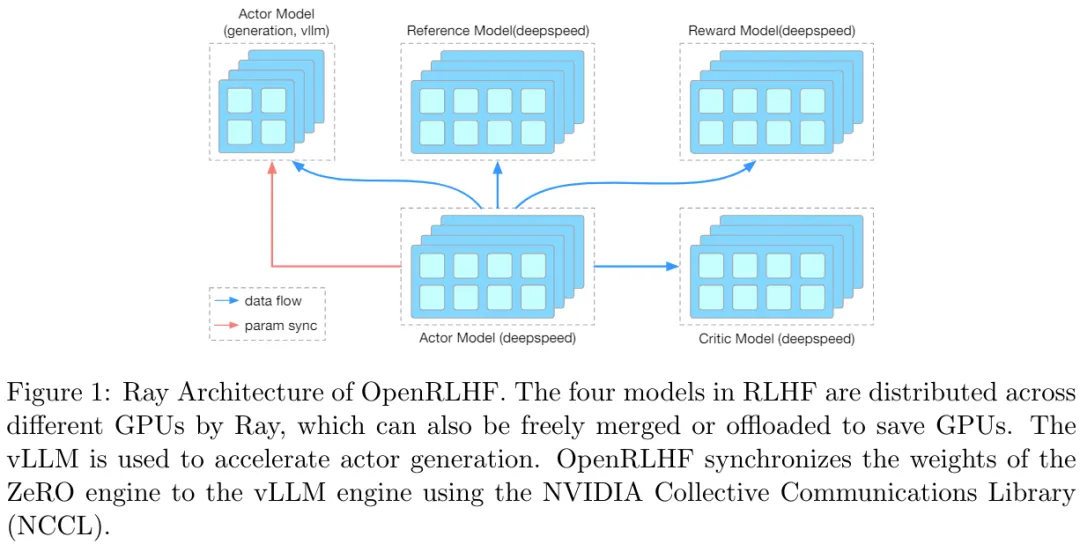
这样的设计很自然就支持在 RLHF 训练过程中使用多个奖励模型,如图 2 所示,并适用于多种算法实现。
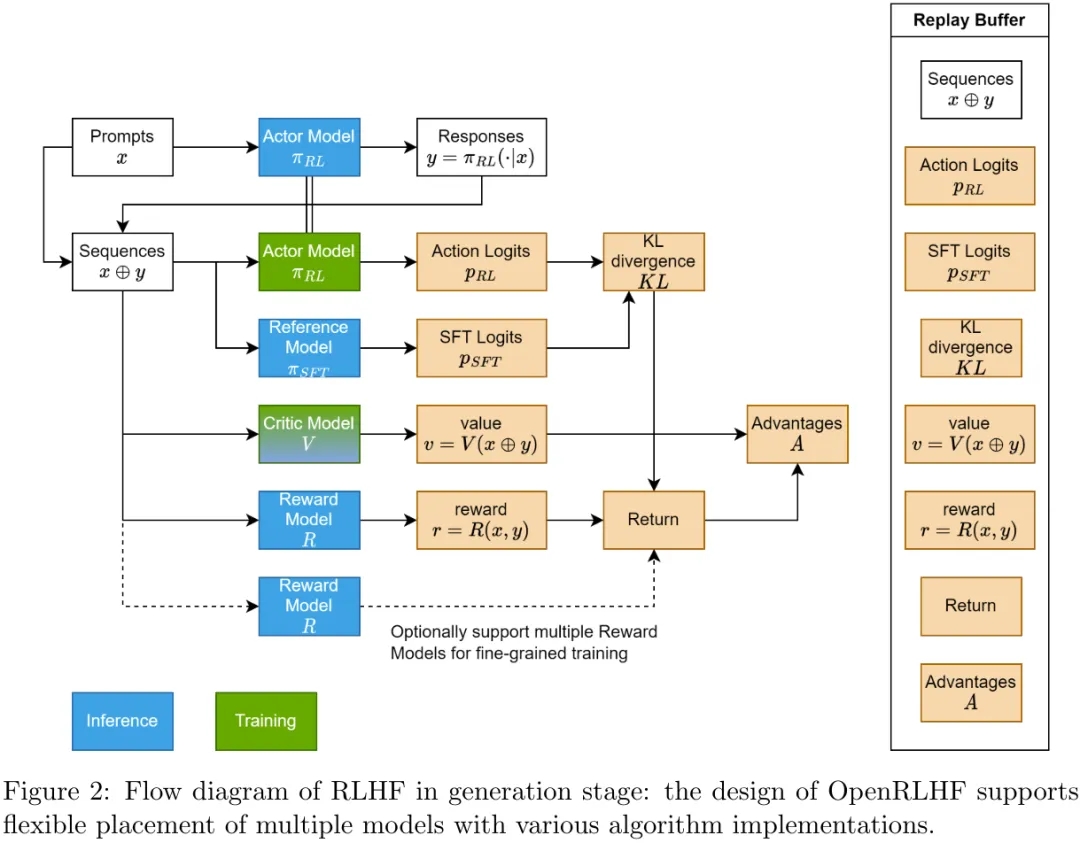
基于此,算法工程师无需关心底层数据流的细节,就能快速构建多种对齐策略,比如有用性和有害性分离。这样的调度器设计还可使用 Ray 和 DeepSpeed 来实现灵活的模型融合或卸载策略。比如可以融合 actor - 参考或 critic - 奖励模型以节省 GPU 资源。
除了能高度定制算法实现这一优点,该调度器还能以最优方式编排 GPU,从而提升整体训练性能。
RLHF 算法的性能取决于训练和推理两方面的效率。从分析结果看,主要瓶颈是在 PPO 样本生成阶段(如图 2 所示),这个阶段占到了整体训练时间的 80%。原因是:在生成阶段,自回归解码的复杂度为 O (n^2),并且也受到内存限制。
为了进一步加快样本生成的速度以及支持无法载入到单台 GPU 的更大型 LLM(比如 700 亿参数的模型),OpenRLHF 使用了 vLLM 的张量并行化等先进技术(连续批处理和分页注意力)来执行生成过程,如图 1 所示。
在 RLHF 的生成和学习阶段,OpenRLHF 采用了以下技术来获得进一步的提升:
图 2 中另外三个模型使用了 ZeRO 的第 3 阶段(对模型、梯度和优化器进行分片)。OpenRLHF 使用了英伟达 NCCL 和 vLLM 权重加载器来同步 ZeRO 和 vLLM 引擎的权重,确保实现快速又简单的集成。
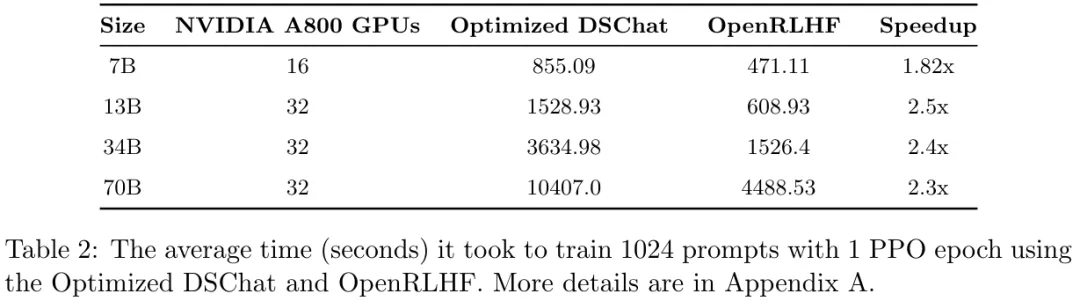
表 2 比较了 OpenRLHF 与该团队精心微调过的 DSChat 的性能。
在训练大型语言模型(LLM)时,PPO 等强化学习算法容易不稳定。为了保证稳定,该团队尽力验证了 OpenRLHF 的实现细节。图 2 和图 3 分别给出了一般的推理和学习流程。
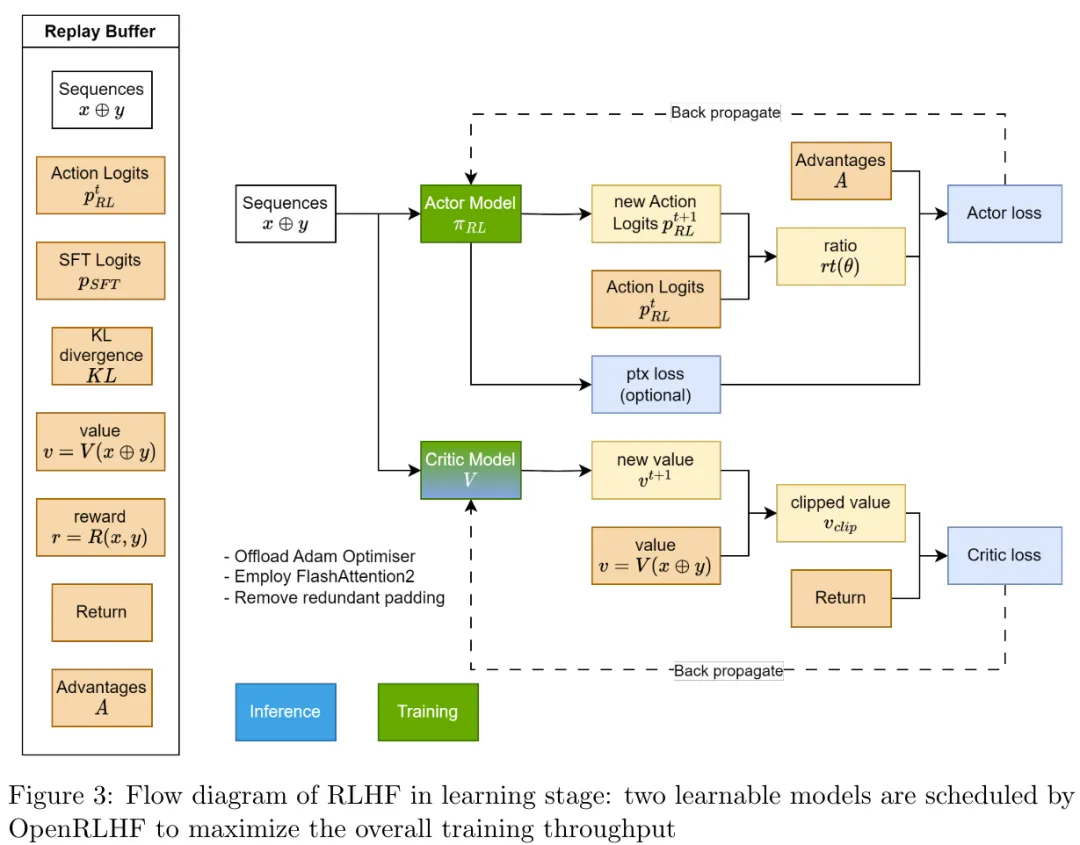
此外,OpenRLHF 还借助了一些技巧来保证 PPO 实现的训练稳定,包括:
为便于用户使用,该团队还为支持的算法提供了一键可用的可训练脚本(详见原论文),并且该脚本与 Hugging Face 软件库完全兼容。下面给出了 Llama2 70B 模型的 RLHF 训练的最低配置:

文章来自于微信公众号机器之心,作者Panda




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
