# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
怎样才能将可爱又迷人的柯基与柴犬的图像进行区分?

如果单从图像识别角度而言,两种犬类在外观上极为相似,拥有相近的色块像素,仅凭数据内蕴信息(即图像自身)可能难以对二者进行区分,但如果借助外部数据和知识,情况可能会大幅改观。
近日,一篇以《Image Clustering with External Guidance》为题的论文,提出了能够大幅提升CLIP图像聚类性能,引入外部知识库内容辅助深度聚类的方法。

作为机器学习的经典任务之一,图像聚类旨在无需依赖样本标注的情况下,将图像依据语义划分到不同的类簇中,其核心在于利用先验知识构建监督信号。从经典基于类簇紧致性的k-means到近年来基于增广不变性的对比聚类[1],聚类方法的发展本质上对应于监督信号的演进。
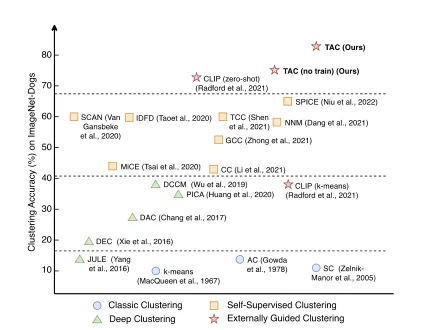
图1: 聚类方法的发展大致可分为三个阶段: (1)传统聚类,基于数据分布假设设计聚类策略; (2)深度聚类,利用深度神经网络提取有利于聚类的特征; (3)自监督聚类,通过数据增广或动量网络等策略构建自监督信号。不同于此前的工作聚焦于从数据内部挖掘监督信号,本文提出利用外部知识来引导聚类,并将新范式归类为 (4)外部引导聚类。实验结果表明,通过利用文本模态中的语义信息,所提出的方法(TAC)显著提升了图像聚类精度。
现有的聚类研究虽然在方法设计上各不相同,但均是从数据内部挖掘监督信号,其性能最终会受限于数据自身所蕴含信息量的固有上限。举例来说,柯基和巴哥犬的图片有明显的差异,但其和柴犬在外观上十分相似,仅依据图像本身难以对二者进行区分。
但值得注意的是,在数据内蕴信息之外,现实世界中还存在着大量有助于聚类的外部知识,而在现有工作中被很大程度地忽略了。
在上述例子中,假设模型具备来自知识库的「柯基腿较短,而柴犬腿较长」等非图像域的外部先验,则能更准确地对二者的图像进行区分。
换而言之,与从数据中竭力地挖掘内部监督信号相比,利用更加丰富且容易获得的外部知识来引导聚类,有望起到事半功倍的效果。
本文提出了一种简单而有效的外部引导聚类方法TAC(Text-Aided Clustering,文本辅助的聚类),基于预训练CLIP模型,通过利用来自文本模态的外部知识辅助图像聚类。
在缺乏类别标注和图像描述等文本信息的情况下,利用文本语义辅助图像聚类面临两个挑战:
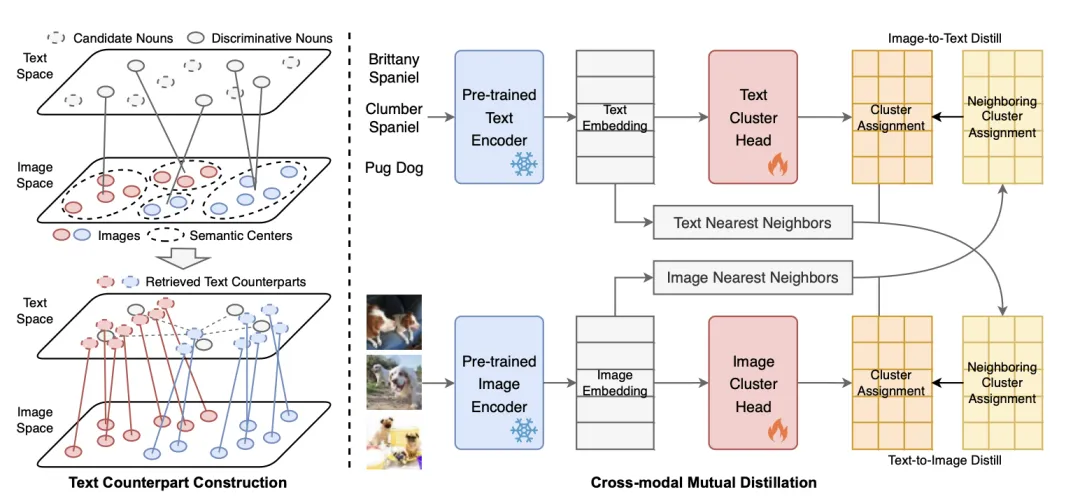
图2:所提出的TAC方法框架,包括文本表征构建和跨模态互蒸馏两部分。
一、文本表征构建
针对第一个挑战,由于样本标注、图像描述等文本信息在图像聚类任务中不可用,本文提出将来自WordNet[2]的所有名词作为文本模态的候选词,选择其中具有代表性的名词集合来组成文本空间。
具体地,为了使文本表征精确地覆盖图像语义,同时尽可能在不同类别图像之间具有区分度,本文首先使用k-means算法来计算图像语义中心。
考虑到过多的语义中心会关注过于细粒度的特征,不利于区分不同类别的图像,而过少的语义中心则会难以准确覆盖位于聚类边界图像的语义,本文提出根据样本点的个数估计k-means算法中合适的k值(实验中选取k=N/300,N为图像个数),并计算图像语义中心如下:
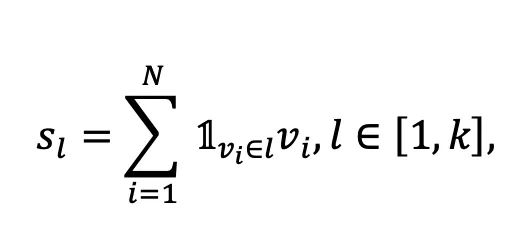
其中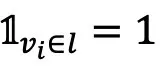 当且仅当图像
当且仅当图像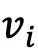 属于第l个聚类,
属于第l个聚类,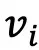 表示第i张图像经过CLIP图像编码器后得到的表征。在得到图像语义中心后,为了选取具有代表性的名词集合,与常见的CLIP Zero-shot分类相反,本文将所有WordNet中的名词划分到k个图像语义中心,其中第i个名词属于第l和语义中心的概率为:
表示第i张图像经过CLIP图像编码器后得到的表征。在得到图像语义中心后,为了选取具有代表性的名词集合,与常见的CLIP Zero-shot分类相反,本文将所有WordNet中的名词划分到k个图像语义中心,其中第i个名词属于第l和语义中心的概率为:
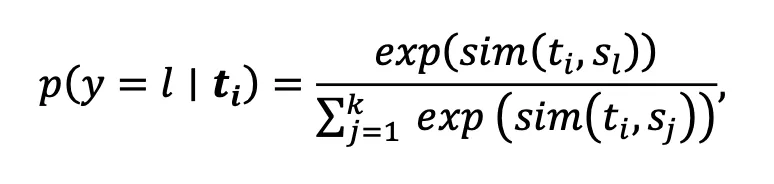
其中sim表示余弦相似性,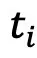 表示第i个名词经过预训练好的文本编码器后得到的表征。保留每个语义中心对应概率最高的名词,作为组成文本空间的候选词。
表示第i个名词经过预训练好的文本编码器后得到的表征。保留每个语义中心对应概率最高的名词,作为组成文本空间的候选词。
选取完具有代表性的名词集合后,可通过为每张图像检索其最相关的名词来构建其文本模态的表征:
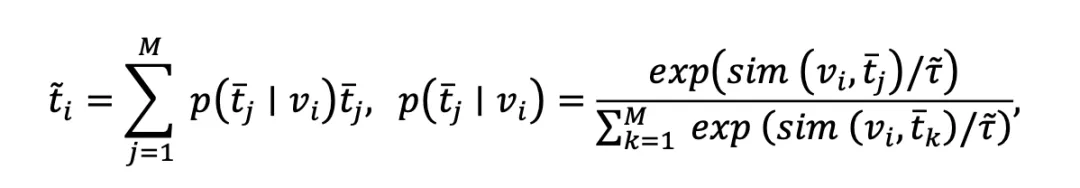
其中,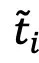 表示第i张图像对应的文本模态中的表征,
表示第i张图像对应的文本模态中的表征,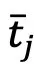 表示组成文本空间的第j个候选名词,
表示组成文本空间的第j个候选名词,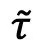 控制检索的平滑程度。
控制检索的平滑程度。
至此,作者为每张图像构建出了其在文本模态中的表征。此时可通过在文本和图像的拼接表征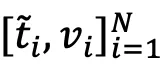 直接使用经典k-means聚类方法来实现图像聚类。
直接使用经典k-means聚类方法来实现图像聚类。
由于融入了来自文本模态的紧凑语义,拼接后的表征具有更好的判别性,从而相较于直接在图像表征上使用k-means会得到更好的图像聚类结果。
值得注意的是,上述文本模态的构建过程不需要任何的额外训练和模型调优,其中名词选取和检索过程的计算开销几乎可以忽略不计。
尽管直接将文本和图像表征进行拼接已能显著提升图像聚类效果,但是简单的拼接并不能充分协同文本和图像两个模态。因此,本文进一步提出跨模态互蒸馏方法,通过训练额外的聚类网络进一步提升聚类性能。
具体地,为每张图像构建邻居集合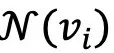 ,并引入一个聚类网络f对每个图像表征做出聚类指派,在每次迭代中,计算所有图像和其邻居集合中随机的一个图像的聚类指派,记为:
,并引入一个聚类网络f对每个图像表征做出聚类指派,在每次迭代中,计算所有图像和其邻居集合中随机的一个图像的聚类指派,记为:
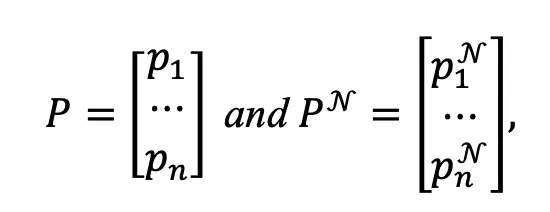
其中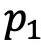 和
和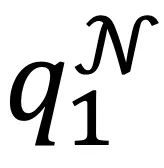 分别对应图像i及其邻居的聚类指派,P和
分别对应图像i及其邻居的聚类指派,P和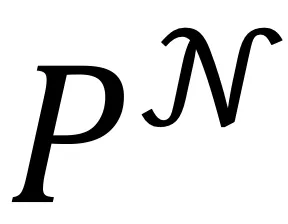 均为n*K的矩阵,其中K表示目标聚类个数。
均为n*K的矩阵,其中K表示目标聚类个数。
相类似的,引入另一个聚类网络g来对每个文本表征做出聚类指派,同样为每个文本表征构建邻居集合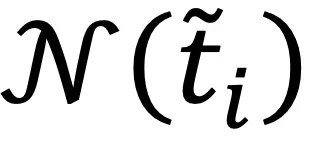 ,在每次迭代中,计算所有文本和其邻居集合中随机的一个文本的聚类指派,记为:
,在每次迭代中,计算所有文本和其邻居集合中随机的一个文本的聚类指派,记为:
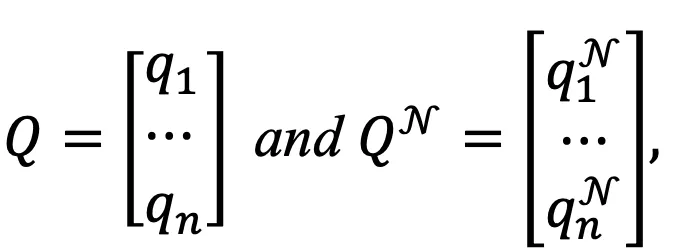
其中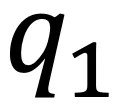 和
和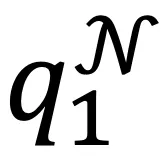 分别对应文本i及其邻居的聚类指派,Q和Q^N同样均为n*K的矩阵。
分别对应文本i及其邻居的聚类指派,Q和Q^N同样均为n*K的矩阵。
为了协同图像和文本两个模态,要求网络对于图像和其对应文本模态的邻居具有类似的聚类指派,同时对于文本和其对应图像模态的邻居也具有类似的聚类指派。为实现该目标,本文设计了如下的损失函数:
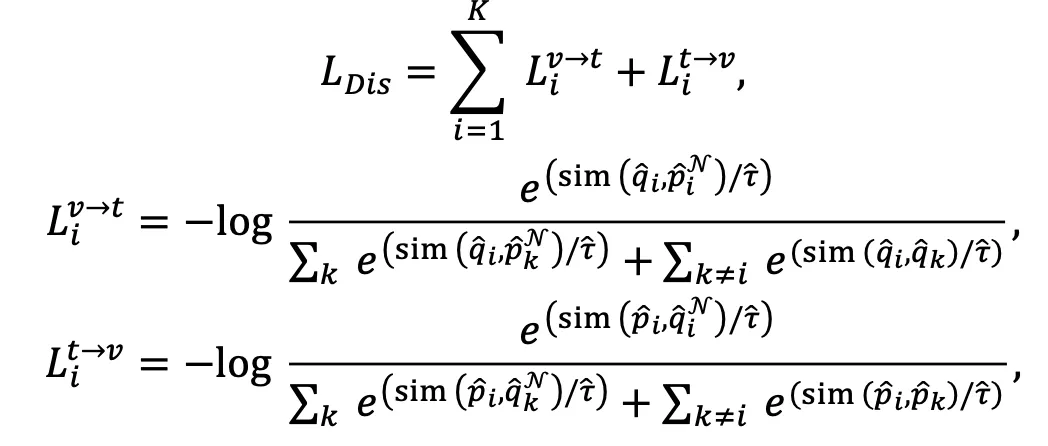
其中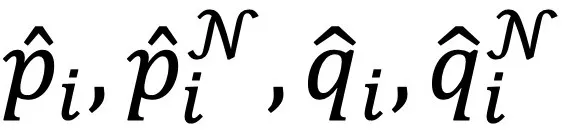 分别表示聚类指派矩阵P,P^N,Q,Q^N的第i列,
分别表示聚类指派矩阵P,P^N,Q,Q^N的第i列, 为温度系数。该损失函数一方面能通过跨模态邻居之间的聚类指派一致性实现图文模态的协同,另一方面能扩大不同的类簇之间的差异性。
为温度系数。该损失函数一方面能通过跨模态邻居之间的聚类指派一致性实现图文模态的协同,另一方面能扩大不同的类簇之间的差异性。
此外,为了使训练过程更加稳定,本文设计了另外两个正则项损失函数。首先,为了鼓励模型做出更加置信的聚类指派,提出如下损失函数:
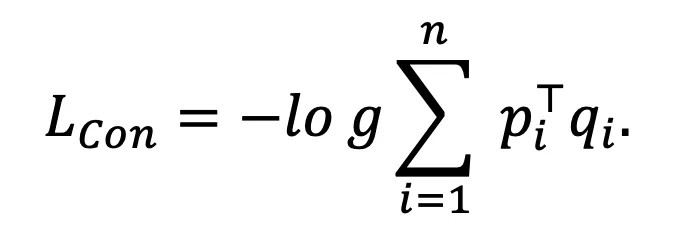
该损失函数在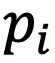 和
和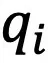 均为独热(One-hot)编码时被最小化,因此能提升聚类指派的置信度。另外,为了防止模型将大量图像和文本都分配到个别类簇中,提出了以下损失函数:
均为独热(One-hot)编码时被最小化,因此能提升聚类指派的置信度。另外,为了防止模型将大量图像和文本都分配到个别类簇中,提出了以下损失函数:
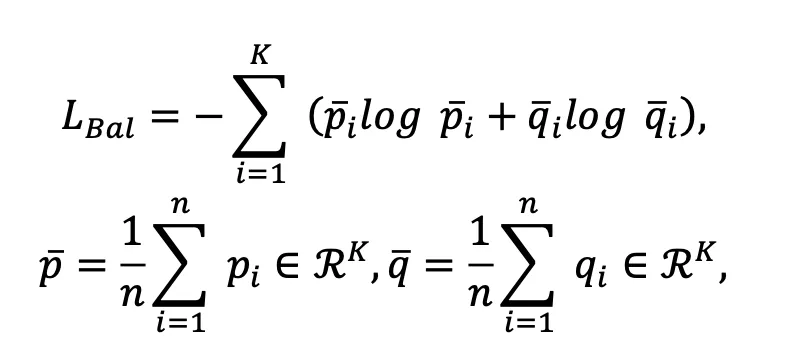
其中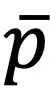 和
和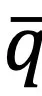 分别表示图像和文本模态中整体的聚类分布。
分别表示图像和文本模态中整体的聚类分布。
综合上述三个损失函数,本文使用如下损失函数来优化图像和文本模态的聚类网络f和g:
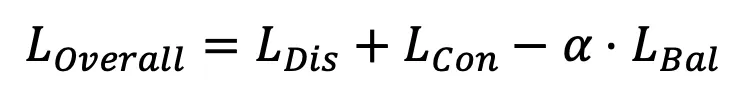
其中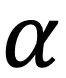 为权重参数。需要指出的是,上述损失函数只用来优化额外引入的聚类网络,并不修改CLIP预训练好的文本和图像编码器,因此其整体训练开销较小,实验表明所提出的方法在CIFAR-10的6万张图像上训练仅需使用1分钟。
为权重参数。需要指出的是,上述损失函数只用来优化额外引入的聚类网络,并不修改CLIP预训练好的文本和图像编码器,因此其整体训练开销较小,实验表明所提出的方法在CIFAR-10的6万张图像上训练仅需使用1分钟。
训练完成后,只需将待聚类的图像输入聚类网络f,即可得到其聚类指派,从而实现准确的图像聚类。
本文在五个经典数据集和三个更具挑战性的图像聚类数据集上对方法进行了验证,部分实验结果如下:
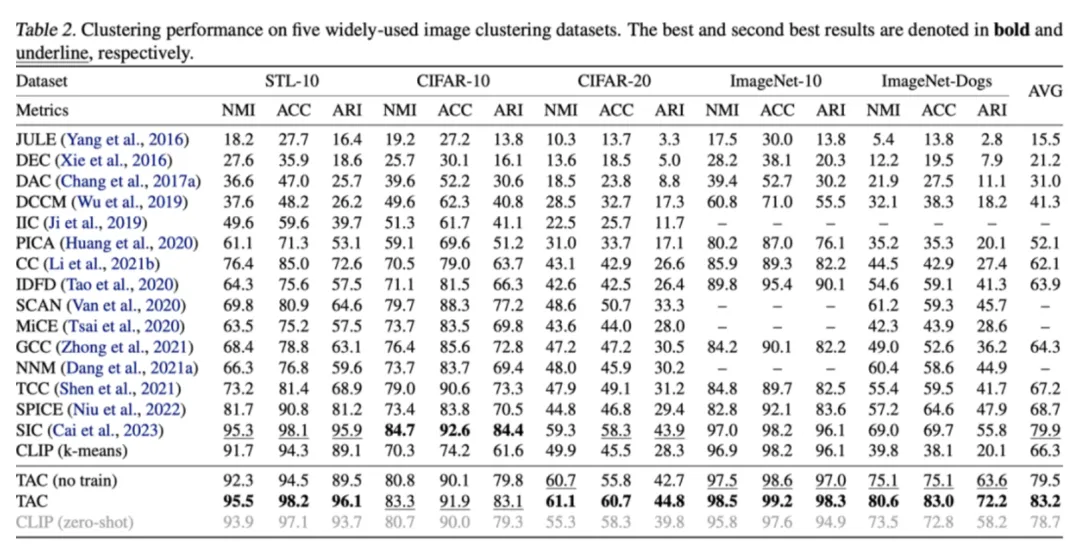
表1:所提出的TAC方法在经典图像聚类数据集上的聚类性能
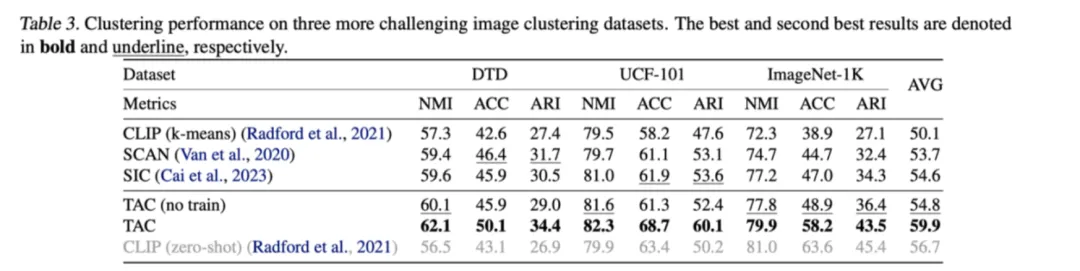
表2:所提出的TAC方法在更具挑战性的图像聚类数据集上的聚类性能
从结果中可以看出,在缺少标注信息的情况下所提出的TAC方法通过为每个图像构建文本表征,能够有效地从文本模态中挖掘语义信息。在无需任何额外训练的情况下,TAC (no train)显著提高了直接在CLIP提取的图像表征上使用k-means聚类的性能,特别是在更困难的数据集上。
当进一步使用提出的跨模态相互蒸馏策略训练聚类网络时,TAC取得了最优的聚类性能,甚至超过了依赖类别标签信息的CLIP Zero-shot分类性能。
不同于现有的聚类研究聚焦于从数据内部构建监督信号,本文创新性地提出利用此前被忽略的外部知识来引导聚类。
所提出的TAC方法通过在无需文本描述的情况下,从预训练CLIP模型的文本模态挖掘语义信息,显著提升了图像聚类性能,证明了所提出的外部引导聚类新范式的有效性。
所提出的外部引导聚类范式的挑战在于:
除了本工作关注的文本语义外,外部知识广泛存在于各类的数据、模型、知识库等,对于不同的数据类型和聚类目标,需要针对性地选择与利用外部知识。
总的来说,在目前大模型、知识库日趋成熟背景下,外部引导的聚类新范式具备良好的发展潜力,希望未来有更多工作进行相关的探索。
参考文献:
[1] Li Y, Hu P, Liu Z, et al. Contrastive clustering[C]//Proceedings of the AAAI conference on artificial intelligence. 2021, 35(10): 8547-8555.
[2] Miller G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
文章来自于微信公众号机器之心,作者李云帆




【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
