# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有没有想过你的狗狗想要对你说什么?
在科幻或者想象的场景中,人类有时会编织类似的情节。
然而在AI风行之下,科幻已然到来!
狗的语言也是「自然语言」,人的语言能word to vector,「汪汪」为什么不行?

近日,就有研究人员开发了一款人工智能工具,可以区分不同含义的狗叫声,并识别狗的年龄、性别和品种。

论文地址:https://arxiv.org/pdf/2404.18739
而且,研究结果表明,源自人类语音的声音和模式,可以作为分析和理解其他声音(例如动物发声)声学模式的基础。
研究者来自密歇根大学,以及墨西哥国家天体物理、光学和电子研究所(INAOE)。
该篇工作同时发表在International Conference on Computational Linguistics, Language Resources and Evaluation上。
这是一作Artem Abzaliev,和他的狗Nova:

——以前是遇事不决,量子力学,以后搞不定的事都喂给AI模型就行了。
大模型:嗯?怎么今天的饭味道怪怪的?

要理解狗狗,首先需要收集狗狗的数据,二作Humberto Pérez-Espinosa负责领导收集数据的团队,共记录了74只不同品种、年龄和性别的狗狗在各种情况下发出的声音。
然后是训练模型,研究人员比较了两种方式的实现效果:
1. 完全用狗狗的声音数据从头训练模型;
2. 在人类语音预训练模型的基础上,使用狗狗声音数据进行微调。
模型选择Wav2Vec2,是使用人类语音数据训练的SOTA语音表示模型。
通过这个模型,研究人员能够生成从狗身上收集的声学数据的表示,并解释这些表示。
实验表明,使用人类语音预训练的模型,居然表现更好。
看来通用基础大模型微调的套路,即使跨物种也能行得通。

最重要的是,研究人员不必时常被极高的数据门槛所阻碍。
毕竟,相比于人类语言,收集动物语言数据要难得多,公开的数据集更是少之又少。
Artem Abzaliev表示,动物的发声在逻辑上更难征求和记录,要么在野外被动记录,要么寻找家养宠物,但必须征得主人的许可。

文章的作者之一,密歇根大学人工智能实验室主任Rada Mihalcea表示:
「关于与我们共享这个世界的动物,我们不知道的还有很多。人工智能的进步将彻底改变我们对动物交流的理解,而且我们可以使用以人类语音为基础的预训练模型,不必从头开始。」
「汪汪」to Vector
要理解动物的交流方式,需要解决三个主要问题:
(1)动物使用的语音和感知单位是什么?
(2)组合这些单位的规则是什么?
(3)这些单位是否有意义,如何将声音单位映射到具体含义?
而这篇工作探讨的是第三个问题,尝试去理解狗狗发声的语义。
研究人员使用了一个由74只狗的叫声记录组成的数据集,这些记录是在墨西哥的狗主人家中现场收集的。
使用相机内置麦克风获得录音,音频编解码器为A52立体声,采样率48,000Hz,比特率为256kbps。
本研究中使用的狗发声协议,由墨西哥Tlaxcala行为生物学中心的动物行为专家设计和验证。
74只狗狗包括48只母狗和26只公狗,品种分布为:42只吉娃娃、21只法国贵宾犬和11只雪纳瑞犬。狗的年龄在5到84个月之间,平均年龄为35个月。

狗的叫声来自于不同的场景,比如:
实验者反复按响家庭门铃并用力敲门;
实验者模拟对狗狗主人的攻击;
主人亲切地对狗说话;
主人使用狗通常玩的物品与狗玩耍;
主人执行散步前的正常例行程序;
主人用皮带将狗拴在树上,然后走出视线;
记录狗狗对这些刺激做出的反应,根据不同情景,录音会持续10秒到60分钟。
数据处理
将录音会分割成较短的片段,长度在0.3到5秒之间,使用阈值来区分叫声和背景噪声。
使用与刺激相关的信息手动注释每个生成的片段。下表显示了14种狗的发声类型以及相应的段数和持续时间:

为了在数据集中创建狗狗叫声的声学表示,研究人员以自监督语音表示模型Wav2Vec2为基础,来进行微调。
Wav2Vec2使用Librispeech语料库进行预训练(960小时未标记的人类语音数据),来学习如何将音频信号表示为一系列离散标记。
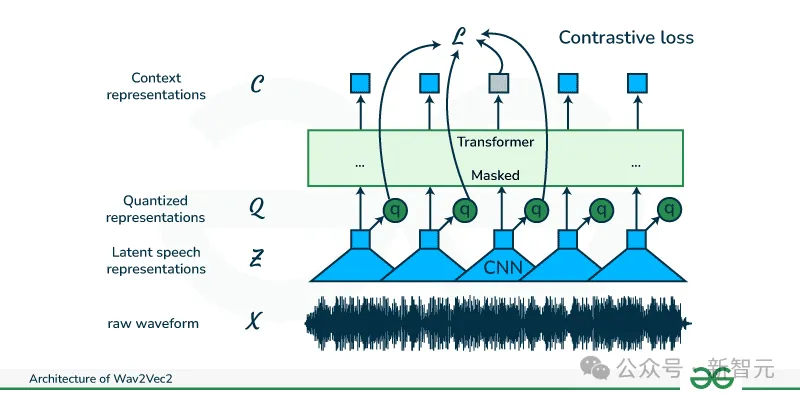
这里使用HuggingFace上的Wav2Vec2开源实现,并且比较了用狗狗数据从头训练模型,以及使用预训练模型微调,两者的效果差异。
研究人员探索了几个基本任务,包括个体叫声识别、狗的品种识别、性别识别、以及预测叫声关联的场景。
所有实验都使用十倍交叉验证设置:将7-8只狗作为测试数据集,使用其余狗的发声进行训练。
叫声识别
这个任务需要将单个音频片段,分类为数据集中74只狗中的一只。据说,人类很难区分单个狗的吠叫声,但AI不同,即使是无监督的模型也可以表现得相当好。
下表显示了实验结果,使用预训练模型微调的方案占据了优势:

品种鉴别
这项任务的目标是预测狗的品种(吉娃娃、法国贵宾犬和雪纳瑞犬)。这里假设不同的品种有不同的音高,因此声学模型应该能够识别这些差异,而与上下文无关。
这有点类似于人类的口音识别,比如根据声音来区分是美国、英国还是印度人。
实验结果如下表所示,预训练模型表现最好。单个品种的差异可以通过每个品种的观察数量不平衡来解释,吉娃娃是数据集中最常见的品种(57%),其次是法国贵宾犬(28%)和雪纳瑞犬(15%)。

从结果来看,在所有任务中,性别识别是最困难的任务。
作者假设从头开始训练的模型专注于学习声学特征,而预训练的wav2vec则试图走捷径,导致过拟合,因此女性的F1增加,男性的F1降低。
关联场景预测
最后一项任务预测叫声关联的场景。由于标签分布高度偏斜,这里关注的是有更多例子的场景:
对陌生人非常具有攻击性的吠叫(LS2);
对陌生人正常吠叫(L-S1);
负面尖叫(在陌生人在场的情况下)(CH-N);
消极的咕噜声(在陌生人面前)(GR-N)。
实验结果如下表所示。与之前的实验类似,两种Wav2Vec2模型的表现都优于基线(Majority),而预训练版本获得了最准确的结果。

文章来源于“新智元”,作者“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
