# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年2月,Google Research的研究人员提出了一个时序预测基础模型TimesFM,在1000亿个「真实世界时间点」上进行预训练,仅仅用200M的参数规模就展现出了超强的零样本学习能力。

论文链接:https://arxiv.org/pdf/2310.10688.pdf
当时权重还没有发布,就已经有人在Reddit社区中表达了难以克制的兴奋。
5月8日,这篇研究又掀起了一阵波澜。
官方博客宣布这篇文章被ICML 2024接收,而且在GitHub和HuggingFace上公开了源代码和模型权重。


开源后的短短几天内,GitHub上项目标星数已经达到了1.5k。
DeepMind首席科学家Jeff Dean转发了官方推特,为TimesFM的研究成果背书。

在官宣的消息下面,网友们纷纷为谷歌这波公开模型的操作点赞:
「非常酷,希望大多数公司经常做这样的事。」

「非常高兴看到谷歌拥抱开源模型和HuggingFace社区。」
也有网友称赞TimesFM的零样本表现。

让时序模型实现「零样本」预测
时间序列预测在零售、金融、制造业、医疗保健和自然科学等各个领域无处不在,比如预测股市、降雨量、流感病例、GDP等各种各样的指标,是一种「基于过去预测未来」的科学。
然而,时序预测并不是一件容易的事,模型需要处理各种复杂且动态的模式,比如循环周期、季节性、频率、趋势、异常值、噪音等等。
传统的深度学习方法需要大量数据和领域知识,却只能针对特定的任务和数据集对模型进行训练和微调。
与此同时,如ChatGPT等模型的问世让我们看到了LLM超强的零样本学习能力,只需要给出提示,不需要进一步训练或微调即可让模型完成各种类型的语言任务。
这就引出了一个问题:时间序列的基础模型能否像自然语言一样存在?在大量时间序列数据上进行预训练的大模型,能否像在大量语料上训练过的GPT一样,对未见数据进行准确预测?
这就是谷歌研究人员声称要让TimesFM实现的目标。
「类GPT」架构
相比非常容易大量爬取的文本数据,时间序列方面的公共数据集非常稀缺。而且为了训练通用的时序模型,数据集中应该包含大量的(百万级别)来自各种领域的多样化数据,且有不同的时间粒度,比如每小时、每日、每周等。
TimesFM的研究团队设法从三个特别渠道找到了这样的时序数据:
通过大量的数据集创建和评估工作,他们得到了包含1000亿个数据点的数据集。
虽然和Llama含有1T token的语料库依旧存在一定差距,但在时序预测领域是前所未有的大规模数据集。
在模型架构方面,TimesFM的灵感来自于Vision Transformer(ViT)和GPT,采用了decoder-only架构,主要由三个部分组成:输入编码器、解码器和输出解码器。
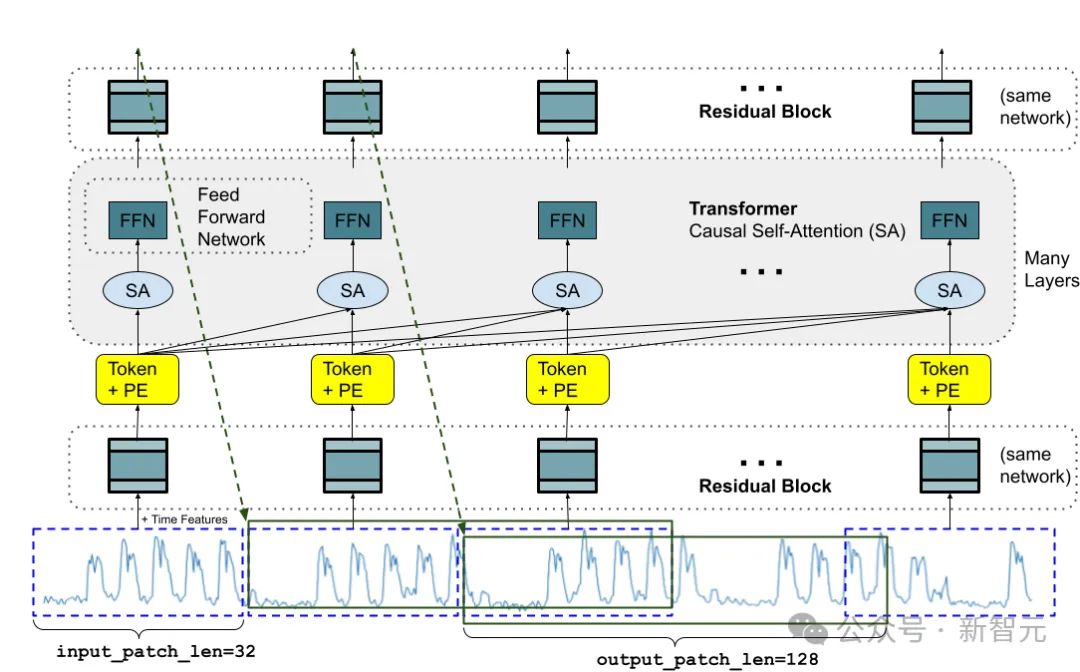
对于输入数据的表达,同时借鉴了计算机视觉中的patch以及自然语言中的token两个概念。
输入的时间序列数据会先被输入编码器表示为token,再被分割为许多相同长度的patch,再将每个patch映射为作为模型输入的token。
解码器是模型的核心组件,应用了自注意力和位置编码机制,让模型可以学习序列中不同token之间的依赖关系。最后,输出解码器将输出token映射为最终的预测。
而且,TimesFM的关键功能之一是,它可以生成可变长度的输出token,这意味着模型可以预测任意数量的未来时间点,而不需要任何重新训练或微调。这是通过在模型输入中加入预测长度(PL)token实现的。
预测结果媲美监督学习
研究人员使用Monash Forecasting Archive来评估TimesFM的「开箱即用」性能,该数据集包含来自各个领域的数万个时间序列,如交通、天气和需求预测,覆盖频率从几分钟到每年的数据。
可以看到,zero-shot(ZS)TimesFM比大多数监督方法都要好,包括最近的深度学习模型。论文还对比了TimesFM和GPT-3.5使用llmtime(ZS)提出的特定提示技术进行预测,结果证明了TimesFM的性能优于llmtime(ZS)。
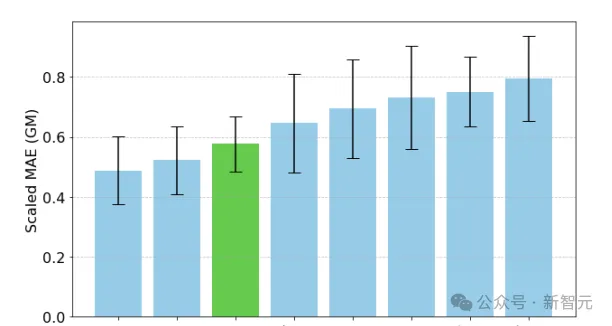
在Monash数据集上,TimesFM(ZS)与其他有监督和零样本方法的比例MAE(越低越好)
大多数Monash数据集都是短期或中期的,也就是说预测长度不会太长;研究人员还测试了TimesFM对常用基准长期预测对最先进的基线PatchTST(和其他长期预测基线)。
研究人员绘制了ETT数据集上的MAE,用于预测未来96和192个时间点的任务,在每个数据集的最后一个测试窗口上计算指标。
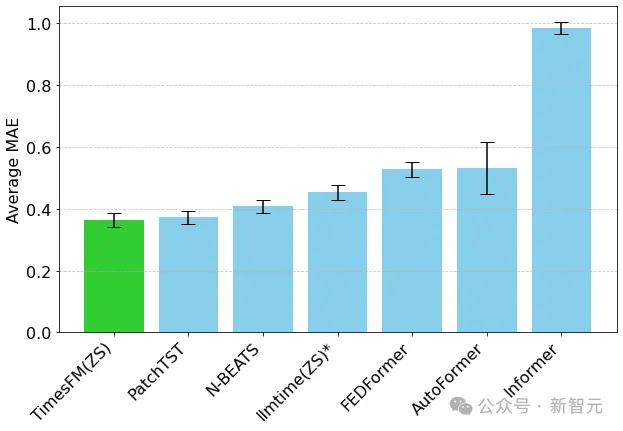
TimesFM(ZS)的最后一个窗口MAE(越低越好)相对于llmtime(ZS)以及ETT数据集上的长期预测基线
可以看到,TimesFM不仅超过了llmtime(ZS)的性能,而且与在相应数据集上显式训练的有监督PatchTST模型的性能相匹配。
文章来源于“新智元”,作者“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
