# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果考试题太简单,学渣也能拿一百昏。在 AI 圈,我们应该拿怎样的「试卷」来检验一直处于流量 C 位的大模型的真实水平?是高考题吗?当然不是!
也有些人认为,在各种 Benchmark 榜单上,谁排第一谁最强。
其实并非如此,有时候,越「权威」的榜单就越容易被策略性刷榜。
因此,模型的「强」不能只是在某个 Benchmark 上排名第一,而是要在多个维度上都很能打。
近日,全球领先的国际数据公司(IDC) 最新发布的大模型实测报告《中国大模型市场主流产品评估,2024》从基础能力到应用能力 7 大维度对 11 家大模型厂商的 16 款市场主流产品进行实测。
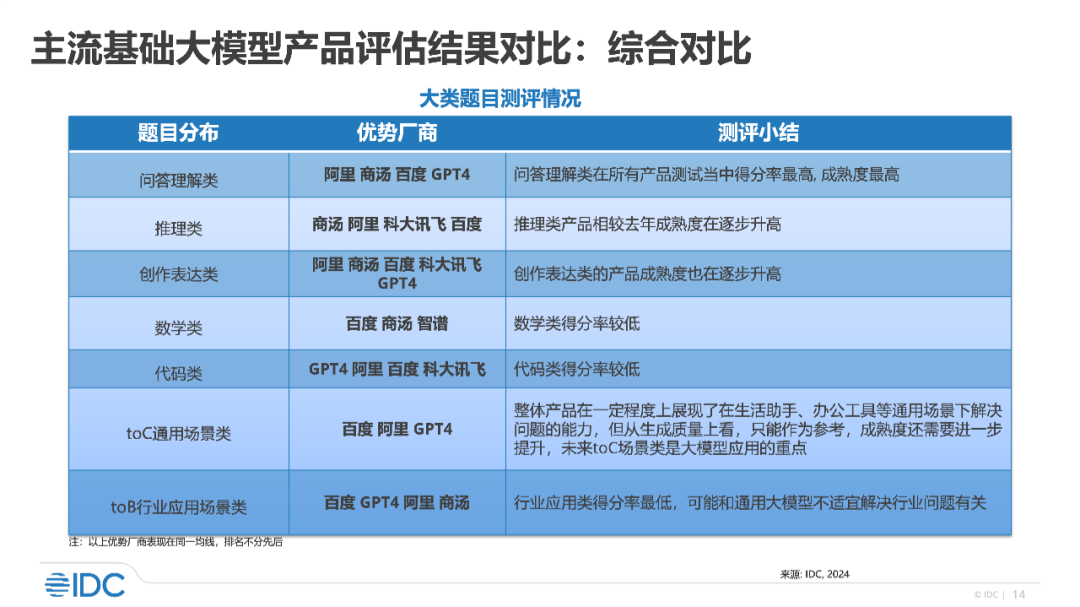
报告显示,百度文心大模型整体竞争力位于领先水平,产品能力处于第一梯队,是唯一一家在 7 大维度上均为优势厂商的企业。文心一言、文心一格在问答理解类、推理类、创作表达类、数学类、代码类等基础能力,toC 通用场景类、toB 特定行业类等应用能力等 7 大维度均具备领先优势。其他评测厂商中,阿里获 6 项优势维度,OpenAI GPT-4 和商汤分获 5 项。
IDC《中国大模型市场主流产品评估,2024》
要知道这份实测报告不同于以往的评测榜单:
首先,IDC 成立了专门的产品测试团队、邀请外部专家团队,在审核委员会的监督下,保证了评估结果的真实度。
其次,测试的全面性。在 IDC 列出的厂商里,有很多我们熟悉的公司,国外厂商如 OpenAI;国内厂商包括阿里、商汤、科大讯飞、百川、智谱、昆仑万维等 11 家大模型厂商的 16 款产品参与了本次评估。从这可以看出,IDC 集结的这批模型中,可谓是高手云集,想要在这当中拔得头筹,没有两把刷子是不可能占据一席之地的。
除了涵盖众多厂商,IDC 测试题目也涵盖方方面面,分为基础能力和应用能力两个大类共 7 个维度:基础能力包括问答理解类、推理类、创作表达类、数学类、代码类;应用能力主要包含 toC 通用场景类和 toB 特定行业类,每一类单独计分。

IDC 题目类型
7 项维度,主流大模型全面大比武
过去一年,说 AI 领域是「百模大战」一点也不为过。特别是国内,从科技巨头到创业公司都推出了自己的大模型产品。
此次 IDC,就对业内知名的主流基础大模型产品进行了评比。
从 IDC 报告的结果来看,百度文心一言 4.0、文心一格以及 OpenAI 、阿里、商汤、科大讯飞发布的大模型产品位于第一梯队;紧随其后的是百川、智谱、昆仑万维位于第二梯队;联汇、云知声、云从科技暂列第三梯队。
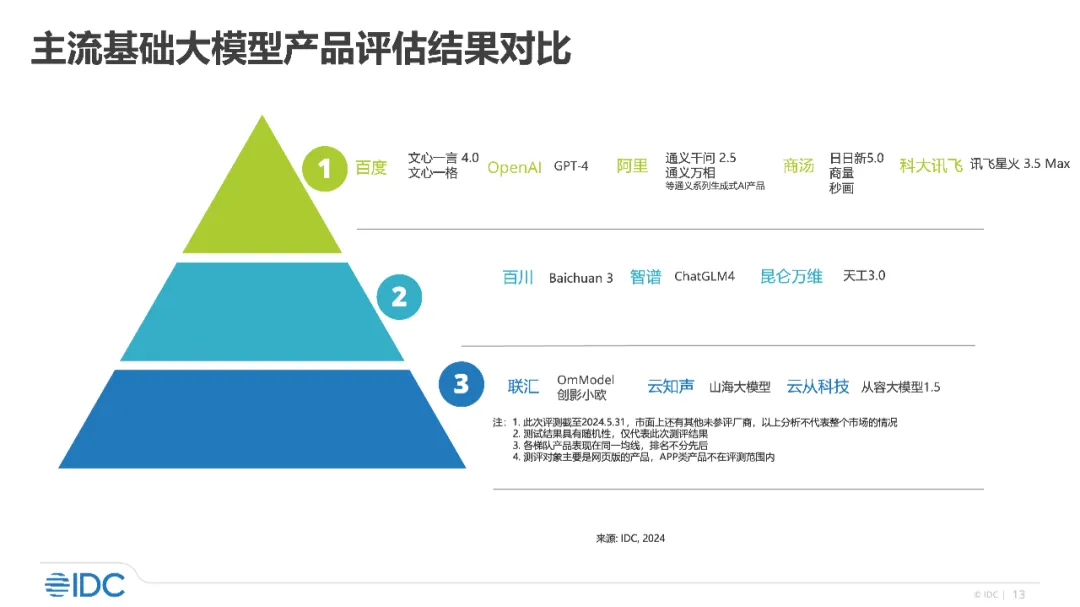
细分来看,在 IDC 评测的 7 个维度上,百度文心大模型在每一项指标上都被列为优势厂商,没有短板,可以说是一位全能选手。其他厂商的大模型均未拿到全优,在一个或多个方面存在短板。阿里获得 6 项优势维度排名第二,OpenAI GPT-4 和商汤获得 5 项优势排名第三。举例来说,排名靠前的 OpenAI 以及阿里在数学类题目上不及百度,商汤在 toC 通用场景类题目上落选。
从实际的模型效果和迭代速度来看,文心大模型在文档 / 长文能力、检索增强、创作智能体等技术和产品创新上比较可圈可点。
拆解基础能力
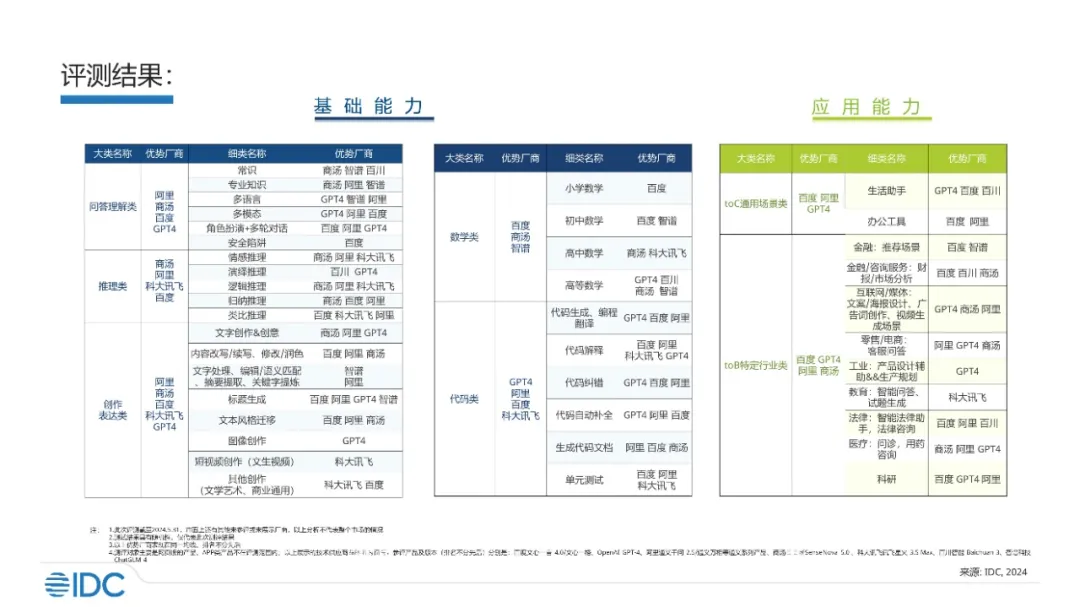
IDC 咨询发布的基础大模型产品实测结果
百度、GPT-4、阿里、商汤在问答理解类被列为优势厂商。这类题目主要考察模型理解和回答人类问题的能力,IDC 从常识、专业知识、多语言、多模态、角色扮演 + 多轮对话、安全陷阱进行考察。
在安全陷阱这个细分维度,只有百度文心大模型入选。我们推测,这是因为百度在大模型安全问题上进行了全面的研究,确保服务安全。一直以来围绕大模型讨论最多的就是安全和隐私,IDC 的结果表明当前安全陷阱问题仅有少数产品能够识别地较好,需要进一步的优化。
如今大模型的发展方向朝着多模态前进,不但要求大模型在文本上表现良好,在图像、语音等多个方面也要拿出成绩。百度在多模态和角色扮演 + 多轮对话上也表现优异。
推理类题目主要考察大模型基于已知信息推出新结论的思维方式。百度在归纳推理、类比推理两项指标上入选优势厂商。归纳和类比推理通常涉及抽象和高级思维能力,这就需要模型在进行推理时,应能处理并整合来自不同源的信息,包括直接数据和推断出的隐含信息,从而确保模型推理的准确性。
随着生成式 AI 的快速发展,创作表达成为大模型一较高下的赛道。一篇文章只写了开头不知该如何续写、不会起标题…… 这时大模型都能帮你完成。我们以文本风格迁移为例, 这项任务要求模型必须准确理解原始文本的内容和意图,这是风格转换的基础。模型需要识别和理解不同的写作风格,这要求模型能够区分例如学术文本、商业报告、新闻报道或口语等不同类型的语言风格。模型在理解原文内容和目标风格的基础上,生成的文本需要保持一致性和连贯性等等。这些都对大模型背后的技术提出了很高的要求。
这一维度的比较结果表明百度在内容创作、生成质量和速度等方面展现出优势,这将在数字内容市场中具有更强的竞争力。
从 IDC 的测试来看,国产大模型在问题解答、推理和创作表达上的成熟度在逐步升高。但在数学和代码这两个基础能力维度上得分率整体较低。
一直以来,大模型被划分为数学上的「差等生」。在数学任务上,大模型不仅需要逻辑推理能力,还需要对问题有很好的解析和理解、抽象出各个问题的逻辑关系,最后给出准确的答案。IDC 报告显示,百度大模型在数学类任务上体现出较强的体系化思维、逻辑思维和抽象思维能力。
代码能力是评估大模型理解、逻辑、推理、生成等综合能力的体现,其已成为程序员辅助编程的必备助手。在代码类所有 6 个细分维度中,百度均入围优势厂商,在代码生成、编程翻译、代码补全、代码纠错等多个方面表现优异。
应用能力评估
除了基础能力,IDC 还对大模型的应用能力进行了全方位测评,主要包括两个方面:面向普通用户服务 ToC,以及面向企业用户服务 ToB。
在 ToC 类场景下,入选的厂商非常少,但百度在这两项指标上均入选。评测结果显示,百度文心大模型、GPT-4 等在搜索、写邮件、文生表图等办公场景下具备优势,此外文心大模型在衣食住行、生活服务、闲聊创意等生活助手场景中被选为优势厂商。
在 toB 特定行业类任务上,文心大模型已经在金融、法律、科研等多个行业落地。GPT-4 在工业、零售电商等落地较好。
技术是通用大模型立身之本
许多人都是从 2022 年底 ChatGPT 发布之后才听过大模型一词。
但其实 ChatGPT 这类大模型产品的爆火背后是 NLP 领域多年技术积累的结果,而这个过程中国科技公司如百度等也从未缺席。
例如,百度早在 2019 年 3 月,就发布了文心大模型 1.0 版,现已升级到文心大模型 4.0 版,实现了基础模型的全面升级,在理解、生成、逻辑和记忆能力上都有着显著提升。
这些提升靠什么做到的?主要是百度在芯片、框架、模型和应用上的全栈布局,尤其是飞桨深度学习平台和文心大模型的联合优化。
具体来说,在训练方面,百度采用块状稀疏掩码注意力计算、超长序列分片并行、灵活批次虚拟流水并行、并行计算与通信深度联合优化等技术,提高模型整体训练效率和性能;在推理部署方面,百度创新了 INT4 无损量化加速、注意力机制协同优化、精调模型集约化部署、异构多芯混部推理等技术,在模型精度、推理性能、部署成本等方面均取得了较好成果。
相比 2023 年文心一言发布时,文心大模型训练效率提升到当时的 5.1 倍,推理性能提升到 105 倍。
反映到用户数据上,2024 百度 Create AI 开发者大会的最新数据显示,文心一言累计用户规模已达 2 亿,日均调用量也达到了 2 亿。
增效降本的实际应用
大模型不仅掀起了一场 AI 技术变革,还在一定程度上重塑了我们的生产和生活方式,提高了生产力。
在大模型应用落地过程中,效果、效率和成本都很重要,我们需要从实际应用的场景需求出发,选择最适合的模型。从研发侧来说,需要持续不断进行高效、低成本的模型生产;在应用侧,则需要充分发挥按需调度的原则,利用任务需求的不同设计多模型的组合推理机制。
在 IDC 评测报告中,我们可以看到百度文心大模型在 toC 和 toB 应用场景中均有出色表现。这源于百度在大模型应用落地中的两个关键考量:一方面是高效低成本的模型生产;另一方面是多模型推理。
高效低成本模型生产方面,百度研制了大小模型协同的训练机制,可以有效进行知识继承,高效生产高质量小模型,也可以利用小模型实现对比增强,帮助大模型的训练。同时,建设了种子模型矩阵,数据提质与增强机制,以及从预训练、精调对齐、模型压缩到推理部署的配套工具链。高效低成本模型生产机制,助力应用速度更快、成本更低、效果更好。
多模型推理方面,百度研发了基于反馈学习的端到端多模型推理技术,构建了智能路由模型,进行端到端反馈学习,充分发挥不同模型处理不同任务的能力,达到效果、效率和成本的最佳平衡。
基于上述两方面的设计,文心大模型已经发展出基础模型应用、智能体模式应用、多模态应用等多种创新应用模式,真正地把大模型能力转化成了生产力的提升。
例如在行业落地上,百度智能云推出千帆大模型平台,以一站式企业级大模型开发及服务运行平台服务大众。2024 年 5 月底,百度宣布文心大模型的两款主力模型 ERNIE Speed、ERNIE Lite 免费。截至目前,包括国家电网、浦发银行、中国航天、吉利、长安汽车、泰康保险、TCL、上海辞书出版社、荣耀、三星、蔚来汽车、南方电网、山东港、汽车之家、毕马威等都成为百度文心大模型的用户和合作伙伴。文心大模型已经拥有中国最广泛的产业落地规模。
结语
除了 IDC 这份报告,我们也关注到文心大模型和文心一言在近期多个评测的不俗表现。
不久之前,清华的《SuperBench 大模型综合能力评测报告》共评测了 14 个海内外具有代表性的模型,结果显示文心一言 4.0 表现亮眼,作为国内头部模型,与国际一流模型水平接近。
沙利文发布的《2024 年中国大模型能力评测》报告显示百度文心一言稳居国产大模型首位,拿下了数理科学、语言能力、道德责任、行业能力及综合能力等五大评测维度的四项第一。
回顾从 2012 年开始的深度学习革命,百度就一直看重 AI 技术的发展与应用。一直到这波大模型浪潮,百度率先推出国产大模型产品,并不断迭代技术、推进落地应用。而经过一年半的「百模大战」,大模型进入了拼落地应用的阶段。这个过程中,百度大模型的生成质量、生成速度与使用成本也许会成为这场战争的胜负手。
文章来源于“机器之心”,作者“陈萍、小舟”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
