# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本周国内最受关注的AI盛事,今日启幕。
活动规格之高,没有哪个关心AI技术发展的人能不为之吸引——
Sora团队负责人Aditya Ramesh与DiT作者谢赛宁同台交流,李开复与张亚勤炉边对话,Llama2/3作者Thomas Scialom,王小川、杨植麟等最受关注AI创业者……也都现场亮相。

一年一度,中国“AI春晚”智源大会如约而至,依然AI大佬密度拉满,依然干货成果满满当当。
从学术向的“语言智能与视觉智能融合创造世界模拟器”,到产业向的“大模型价格战有何影响”,活动开启第一个上午,顶级AI学者、专家们的观点交锋已经让线上线下观众直呼过瘾。

不仅如此,主办方智源研究院,还抛出了一箩筐重磅新进展,开源开放的那种:
大模型趋势以来,创业公司大厂的动向吸引了诸多关注。
但更回归技术本身,当下大模型发展还需要关注哪些方面?是时候参考研究机构的动向和理解了。
智源研究院带来的最新发布主要有大模型进展以及底层算力基座。
智源大模型“全家桶”由4部分组成:

首先在大语言模型方面,智源表示不会重复造轮子,最新发布的成果主要面向产业界正面临的共同难点,比如算力缺乏问题。
智源与中国电信人工智能研究院(TeleAI)联合研发了基于生长技术训练的全球首个低碳单体稠密万亿语言模型。
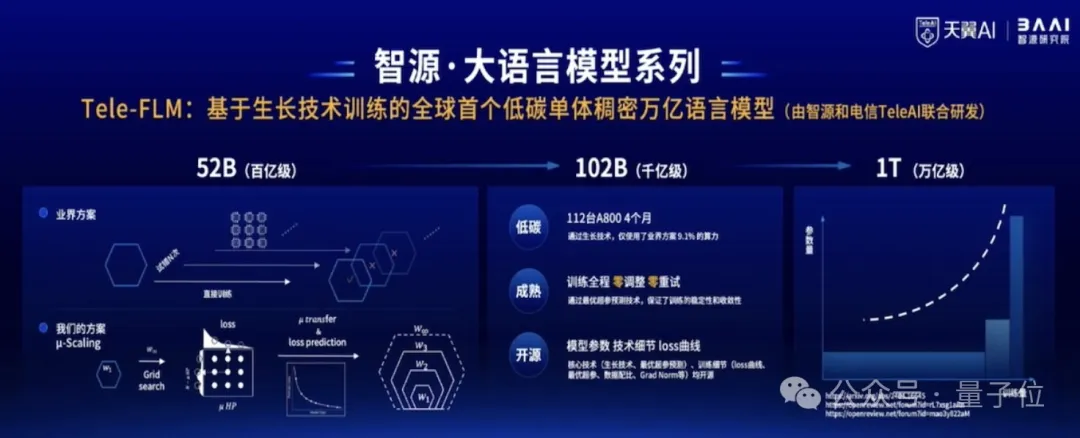
尽管模型参数规模达到万亿级别,但训练实际只用了112台A800,这相当于业界普通训练方案9%的算力资源。
通过优越超参预测技术,训练全过程零调整、零重试。
目前Tele-FLM 1TB版本还在训练中,中间版Tele-FLM 52B已开源。
评估结果显示,在中文方面,Tele-FLM的BPB曲线优于Llama3-70B。英文方面,其BPB评测接近Llama3-70B,优于Llama2-70B。
之后,团队将开源1TB版本,以及训练技术细节以及loss曲线。以期为开源社区提供一个优秀的稠密万亿模型的初始参数版本,避免万亿参数模型早期难以收敛等问题。
同时,智源对基于该基座模型训练出的对话模型Tele-FLM-Chat(52B)进行评测。
AlignBench评测显示,它已达到GPT-4中文语言能力的96%,总体能力可达GPT-4的80%。现在已在ModelScope上可体验。

算力之外,大模型应用落地的另一大挑战是幻觉问题。
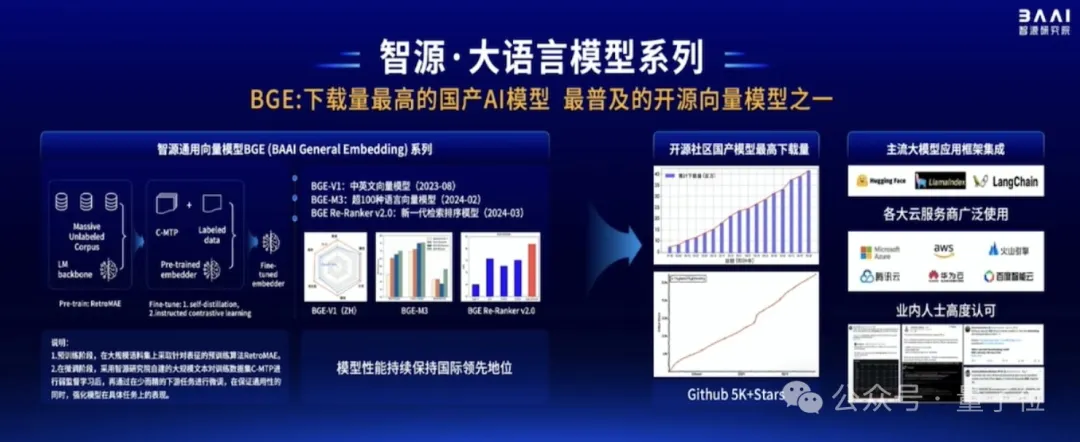
在这方面,智源带来了通用向量模型BGE(BAAI General Embedding)。
该系列模型如今已是全球范围内下载量最高的国产AI模型,也是最普及的开源向量模型之一。
它基于无监督预训练和多阶段对比学习,构建了多语言关联文本数据集C-MTP。
从去年8月发布至今,BGE模型得到了全球主流应用大模型框架的集成,包括Hugging Face、LlamaIndex等。如Azure、AWS、火山引擎、腾讯云、华为云、百度智能云等主流云厂商,也都集成了BGE模型,对外提供商用。
其次,智源聚焦多模态领域,带来了最新进展——Emu3。
去年7月,智源研究院发布生成式多模态模型Emu,12月迭代至Emu2。
最新发布的Emu3采用自回归技术路径,将图像、视频、文字共同训练,统一实现了图像、视频、文字的输入和输出,并且具备更多模态可扩展性。
它具备图像生成能力、视频生成能力:

并且可以理解图像和视频内容:

目前,Emu3还在持续训练中,在经过安全评估后会逐步开源。Emu1和Emu2已经开源。
另外在多模态方面,智源还带来了一个轻量级图文模型:Bunny-3B/4B/8B。
该模型采用灵活架构,可基于不同视觉编码器,如EVA-CLIP、SigLIP;也能基于不同的语言基座模型,比如Phi、StableLM等。
Bunny的模型、数据、代码将全部开源。

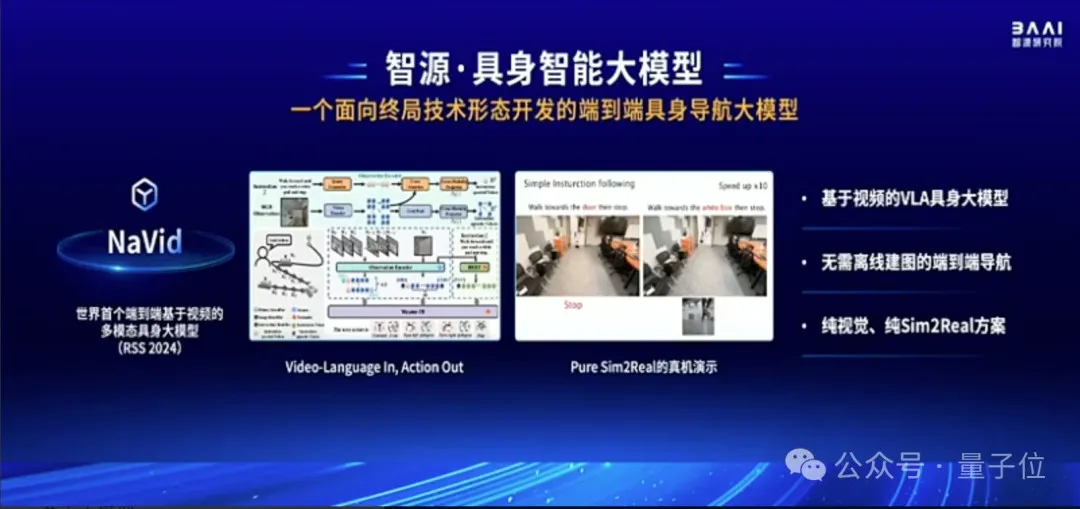
第三,面向具身智能的终局,智源还带来了一个端到端具身导航大模型,并已在人形机器人上应用。
NaVid是世界首个端到端基于视频的多模态具身大模型,它实现了“输入视频和语言,输出动作”。它无需离线建图,是纯视觉、纯Sim2Real方案,能在虚拟世界中训练,在现实世界中直接泛化。
另外智源也关注了具身智能几个关键点。
比如通用抓取模型ASGrasp。通过在仿真系统内构建千万量级场景以及超过10亿抓取数据,实现了抓取技术显著提升,在工业级真机上能够实现超过95%的抓取成功率,打破世界纪录,该成果已被ICRA 2024接收。

SAGE模型是一个操作系统大模型,基于三维视觉小模型和图文大模型,它能让机器人在操作失败后进行思考,就像人一样,然后重新规划动作,进而完成任务。
该模型也被ICRA 2024接收。
Open6DOR则是全球首个开放指令六自由度取放大模型系统,它能让机器人既关注物体的位置,也考虑物体的姿态,从而让抓取更有效。
基于如上成果,智源的具身智能已经可以理解人类的指令并进行对话、执行任务,比如在听到人类说“我渴了/我饿了”之后,它会递上可乐或橘子。

在实际落地方面,智源还与清华大学301研究院带来了全球首创智能心脏超声机器人。
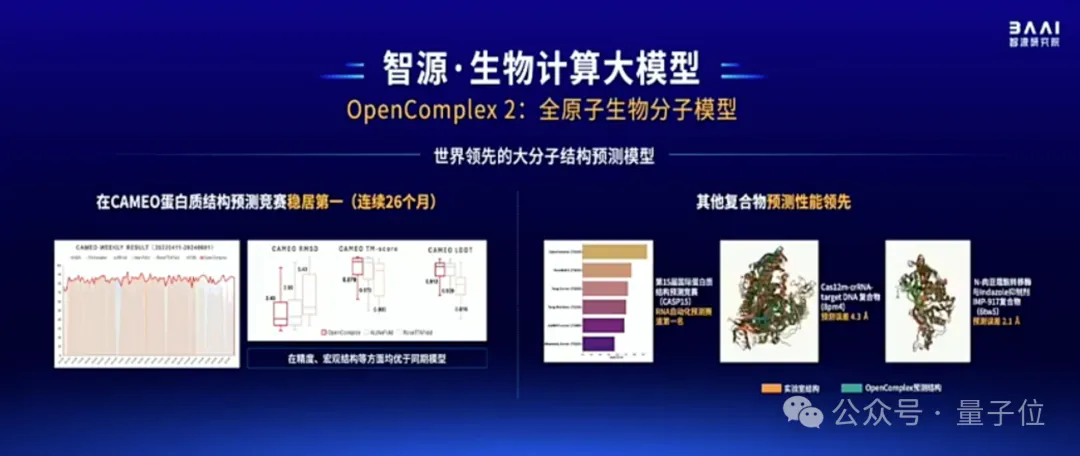
最后,在生物计算方面,智源发布了OpenComplex2全原子生物分子模型。
这是一个decoder-only模型,它基于生成式AI,能在原子层面对RNA、DNA等小分子的结构和相互关系进行预测,精度可达超算水平。
在CAMEO蛋白质结构预测竞赛中,OpenComplex已经连续26个月稳居第一,在精度和宏观结构等方面均优于同期模型(如AlphaFold2)。同时也能对RNA、DNA、蛋白质复合物进行预测。
在与超算结果的对比中显示,OpenComplex已经初步具备通路预测能力。
以上便是智源在过去一年中在大模型领域方面的进展。
带来这些进展其实都离不开底层算力基座的支持。
去年,智源发布了FlagOpen1.0。这是一个面向异构芯片、支持多种框架的大模型全栈开源技术基座。
今年FlagOpen升级至2.0版本。在1.0的基础上,进一步完善了模型、数据、算法、评测、系统五大版图布局,旨在打造大模型时代的Linux。

同时,智源也构建了为大模型而生、支持异构芯片的算力集群“操作系统”FlagOS。

它包括异构算力智能调度管理平台九鼎、支持多元AI异构算力的并行训推框架FlagScale、支持多种AI芯片架构的高性能算子库FlagAttention和FlagGems,集群诊断工具FlagDiagnose和AI芯片评测工具FlagPerf。
可向上支撑大模型训练推理评测等,向下管理底层异构算力、高速网络、分布式存储等。
目前,FlagOS已支持了超过50个团队的大模型研发,支持8种芯片,管理超过4600个AI加速卡,稳定运行20个月,SLA超过99.5%。
此外,智源研究院还推出了开源Triton算子库、首个千万级高质量开源指令微调数据集InfinityInstruct、全球最大开源中英文多行业数据集IndustryCorpus等等新进展。
可见在过去一年中,智源研究院的脚步走得非常快、且布局广泛。
而值得关注的是,在发布新进展同时,智源研究院这一国内顶级AI研究机构,此次也明确地公布了对未来技术趋势的判断。
与大模型领域的工业界玩家不同,智源研究院是一家非营利研究机构,相较于短期应用,更聚焦AI的前沿研究。
在与智源研究院院长王仲远的交流中,他对此解释说:
企业已经在做的事,智源不会做,而是聚焦于更前沿的技术问题。

总结起来,智源对技术路线发展的判断很明确:
在基础模型层面上,是要解决大语言模型发展过程中面临的核心痛点。
比如算力问题。
2023年9月,智源研究院就联合中科院计算所、南洋理工大学、电子科技大学、哈尔滨工业大学等研究团队,提出了一种“生长策略”(growth strategy)。
简单来说,基于生长策略,模型的参数量在训练过程中并不是固定的,而是可以随着训练进行,从较小的参数规模扩展到更大的参数规模。
这次发布的稠密万亿参数语言模型Tele-FLM,就是通过生长技术来训练的。王仲远透露,训练这一模型只用了112台A800,也就是不到1000张卡。
又比如多模态问题。
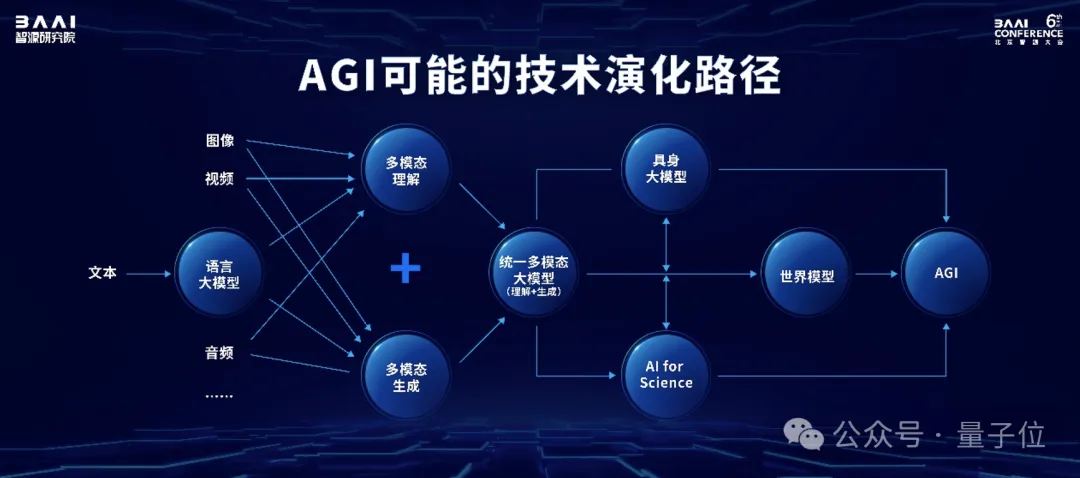
尽管多模态已经成为当下大模型发展的主流方向,但在现阶段,很多多模态大模型其实是单一跨模态模型,无法同时实现视频、图片的生成和理解。
智源的Emu项目,旨在最终实现原生多模态世界模型。
从训练数据的角度,从一开始,文字、图像、视频数据就被放在一起联合训练;从技术路线的角度,智源也选择了难度更高的自回归路线而非Sora带火的DiT路线。
我们认为,像OpenAI,未来也可能会将ChatGPT和Sora做进一步的融合。
从技术判断上,我们想要瞄准真正的多模态大模型,因此选择了自回归这样一个我们认为终极的技术路线。
而在更具体的应用层面上,重点关注具身智能和生物计算, 也并非是单纯追热点。
王仲远甚至主动降了一波预期:
大家要客观理性地来看待技术的发展周期,具身智能未来几年内也可能进入低谷。但我们坚信智能体会从数字世界进入到物理世界。
有此布局的核心原因还是要做“原始的创新”、“集中资源关注核心技术的突破”,智源研究院认为,数字世界的智能体进入物理世界,主要有两条路线:
一是在宏观世界赋能硬件,也就是具身智能。
二是进入微观世界,也就是用大模型对生命分子进行研究。
这两条技术路线“会跟世界模型相互促进,并且最终实现AGI”。
值得关注的是,在更面向未来的技术路线选择之外,智源研究院在最新发布中,再次强调了开源开放。
比如Tele-FLM的核心技术“生长策略”,其技术细节此前就已完全公开。此番发布的多模态图文模型Bunny,同样是基座模型、模型参数、训练代码、训练数据全部开源。Tele-FLM的万亿参数版本和Emu 3也计划在安全评估之后对外开源。
事实上,无论是高举高打的技术布局思路,还是一以贯之的技术共享模式,都是智源研究院创立之始就刻写在基因里的。
2018年,智源研究院作为人工智能领域的新型研发机构正式成立,其使命可以概括为:
2020年,智源“悟道”项目立项。2021年3月,悟道1.0发布,智源研究院正式使用“大模型”这个说法,此后被业界广泛采纳。
而悟道系列开源大模型,也成为过去一年中国产大模型快速发展的技术基石之一。一方面,悟道的7个开源模型成果涵盖文本类、图文类、蛋白质类等多个领域,在发布时连续创下“中国首个+世界最大”记录。另一方面,悟道系列也为中国大模型产业培养了一大批大模型人才,不少现如今在产业界担当主力的大模型研究者,都是“智源系”出身。
可以说,智源研究院是最早系统布局大模型研究的国内科研机构之一,是中国大模型研究的启蒙先行者。
大会现场,几位国内AI大咖也对此有颇多感慨。
杨植麟提到,智源研究院至少是在亚洲地区最早投入、而且真的投入去做大模型的机构。
这是非常难得、非常领先的一个想法。
王小川觉得,智源在中国大模型产业中有着非常好的定位。
智源既有技术高度,又有智库的角色。这两方面有独有的意义,在生态里能够帮助我们更加快速健康的发展。
李大海则提到,在大模型领域的快速发展过程中,有一些事可能商业公司没有动力、没有资源去做。从创企角度出发,非常期待在智源的撮合跟带领下,搭建一个更好的平台,把需要做好的事情一起协作好。
张鹏表示,非常非常希望跟智源长期在学术研究、落地应用合作,甚至包括公共政策相关方面继续保持合作,也祝愿智源大会越办越好。
也正是这样的技术领导力和技术影响力,使得智源研究院成为国内最具国际号召力的研究机构之一。一年一度的智源大会,已然成为国内国际顶尖AI学者交流的重要平台。
2019年首届智源大会起,每年都不乏图灵奖得主、明星项目大咖、行业关键人物现身这场“AI春晚”。深度学习三巨头、贝叶斯网络提出者Judea Pearl、RISC-V掌门人David Patterson……都曾先后参与其中,带来精彩观点的碰撞。
今年,是智源大会举办的第6年,现场依旧爆满,足见其在AI从业者和相关专业学生中的影响力。

如果说,过去顶级的AI学术、交流活动都远在大洋彼岸,现在,就在中国,就在北京,以智源大会为代表,我们也有了属于自己的顶级AI盛会。
在探讨多模态大模型、AGI的全体大会之外,今年的智源大会依然围绕大家最关注的前沿技术问题,设置了大模型产业技术、Agent、具身智能、数据新基建等等分论坛和技术报告。
如果你感兴趣,更多详情,可以关注:
https://2024.baai.ac.cn/schedule
文章来自于微信公众号 “量子位”,作者 “鱼羊 明敏”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
