# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
团队成员均来自斯坦福大学,CTO还是泰勒·斯威夫特的铁杆粉丝。
AI视频领域卷疯了。
Luma引发的狂欢还没结束,AI视频圈又来了个挑战者——
斯坦福大学团队出品的Proteus。

据介绍,Proteus 是一款低延迟基础模型,可以生成高度真实且富有表现力的人物形象。
例如,让世界名画中的主角——蒙娜丽莎或者带珍珠耳环的女孩——肆无忌惮地大笑,面部表情自然流畅:

让奥黛丽·赫本一改往日淑女形象,玩起嘻哈说唱:

还让《哈利·波特》中的斯内普教授唱《Despacito》:

Proteus刚发布,一众大佬发来「贺信」:
AI科学家贾扬清称赞,实时人工智能头像质量出奇得好。

英伟达科学家Jim Fan则表示,这一项目令人印象深刻。

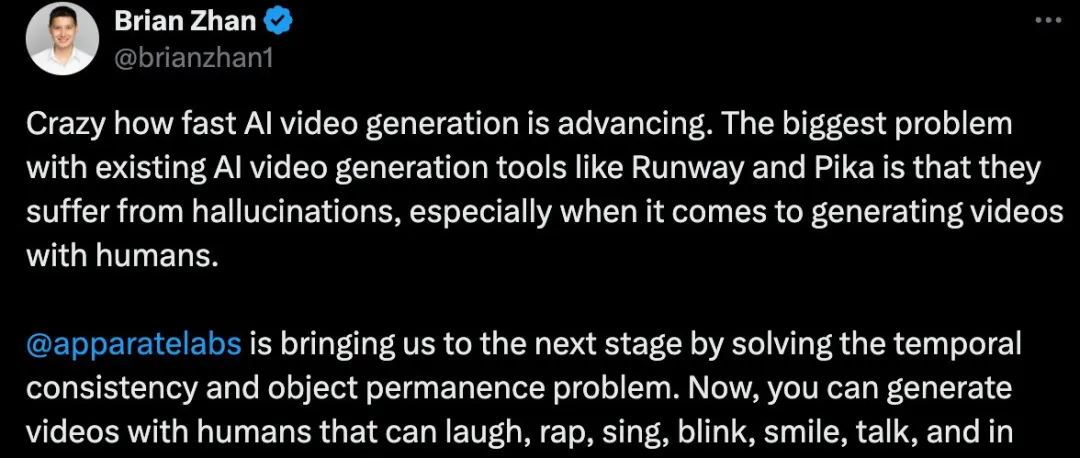
早期投资人Brian Zhan发文称,现有AI视频工具,比如Runway和Pika,最大的问题就是会产生幻觉,尤其是在生成含有人类的视频时。而Apparate Labs通过解决时间连贯性和对象恒定性等问题,使AI视频生成步入下一个阶段。
离谱!鲁迅说起了绕口令
Proteus是新一代的基础模型,用于人类的实时表情生成。
要知道,目前即便是最先进和最强大的生成模型,也无法完全实现人类表情的实时生成。
现有的模型运行速度缓慢,无法提供对生成人物的复杂面部表情和身体动作的直观控制,而且它们在逼真度和表现力方面仍有所欠缺。
而Proteus采用了最先进的transformer 架构的潜在扩散模型,其创新性的潜在空间设计确保了实时的高效率,并且随着架构和算法的持续优化,Proteus能够实现每秒100帧以上(100+ FPS)的视频流。
换句话说,只需一张简单的照片,Proteus不仅能够模仿人类的笑声、说唱、歌唱、眨眼、微笑和对话,还能执行更多生动的表情和动作。
比如说,一向严肃的鲁迅说起了绕口令:

或者让居里夫人清唱《Le Festin》:

抑或是给科学家们开个圆桌会议:

据Proteus研发团队介绍,他们期望Proteus可以成为一个声音可控的视觉化身,为人工智能对话实体提供一个直观的交互界面,同时能够与众多多模态大语言模型无缝兼容,为各种不同的应用场景提供定制化服务。
对此,不少网友脑洞大开——
「只需要用爱因斯坦的数据对大语言模型进行微调,再配上他生动的面部表情,就能让伟大的爱因斯坦化身教学助手,来亲自教授物理课,青少年再也不用愁学不好科学了。」

还有网友表示,我爱死它了,今年绝对是AI视频之年。

起底背后团队
这款被大佬力捧、小而美的模型, 背后是个怎样的团队?
据官网介绍,这是由斯坦福大学的Apparate Labs研发出来的。
目前该团队仅6人,从名字和照片来看,有3人为华人。

首席执行官兼联合创始人沈博魁(William Shen)博士就读于斯坦福大学计算机科学系,由知名教授Silvio Savarese和Leonidas J. Guibas共同指导。

他的研究涵盖人工智能多个领域,包括计算机视觉、机器人学、图形学、生成模型和具身智能。其论文多次获奖,例如在IEEE-CVPR获得了最佳论文奖,还在RSS上入围了最佳学生论文奖的决赛。
此前,他还以GPA4.0的优异成绩获得斯坦福大学计算机科学学士学位。
首席技术官兼联合创始人Connor Lin也是个学霸。
他本硕就读于卡内基·梅隆大学,师从Keenan Crane教授。2020年前往斯坦福大学攻读计算机博士。目前他是一名四年级在读博士生,由Leonidas Guibas和Gordon Wetzstein两位教授共同指导。

Connor Lin的研究聚焦于3D先验知识和神经表示,用于3D重建、生成和编辑,曾获得David Cheriton斯坦福研究生奖学金的支持。
在攻读博士期间,他在谷歌研究、英伟达研究和Adobe研究实习。此前,还在谷歌担任软件工程师,负责Pixel手机的人像模式开发。
此外,这小哥兴趣广泛,喜欢旅行和体育,喜欢烹饪、羽毛球、游泳、桌游和音乐,还是泰勒·斯威夫特的铁杆粉丝
和Connor Lin一样,首席科学家Linqi (Alex) Zhou也是斯坦福大学的一名博士生,由Stefano Ermon教授指导。
此前,Linqi Zhou在加州大学洛杉矶分校获得了计算机科学和应用数学的学士学位,由Song-Chun Zhu教授和Ying-Nian Wu教授指导。
他主要在计算机视觉和机器学习领域进行研究,并致力于构建能够以结构化和概率性方式理解世界的模型。
文章来源于“机器之心”,作者“关注AI大模型的”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
